자연어 감독으로부터 전이 가능한 시각 모델 학습하기
초록
최첨단 컴퓨터 비전 시스템은 미리 정해진 고정된 객체 범주 집합을 예측하도록 훈련된다. 이러한 제한된 형태의 감독은 다른 어떤 시각 개념을 지정하기 위해 추가적인 레이블된 데이터가 필요하므로 그 일반성과 사용성을 제한한다. 이미지에 관한 원시 텍스트로부터 직접 학습하는 것은 훨씬 더 넓은 감독 원천을 활용하는 유망한 대안이다. 우리는 어떤 캡션이 어떤 이미지와 어울리는지를 예측하는 단순한 사전 훈련 과제가, 인터넷에서 수집한 4억 개의 (image, text) 쌍 데이터셋에서 처음부터 SOTA 이미지 표현을 학습하는 효율적이고 확장 가능한 방법임을 보인다. 사전 훈련 후에는 자연어를 사용하여 학습된 시각 개념을 참조하거나 새로운 개념을 설명할 수 있으며, 이를 통해 모델을 다운스트림 과제로 zero-shot 전이할 수 있다. 우리는 OCR, 비디오의 행동 인식, 지리적 위치 추정, 그리고 여러 종류의 세밀한 객체 분류와 같은 과제를 포괄하는 30개 이상의 서로 다른 기존 컴퓨터 비전 데이터셋에서 벤치마킹하여 이 접근법의 성능을 연구한다. 이 모델은 대부분의 과제에 비자명하게 전이되며, 어떤 데이터셋별 훈련도 필요 없이 완전 감독 기준선과 종종 경쟁력이 있다. 예를 들어, 우리는 ImageNet에서 원래 ResNet-50의 정확도와 zero-shot으로 맞먹으며, 그것이 훈련된 128만 개의 훈련 예제를 전혀 사용할 필요가 없다. 우리는 코드와 사전 훈련된 모델 가중치를 다음에 공개한다https://github.com/OpenAI/CLIP.
1 서론 및 동기 부여가 되는 연구
원시 텍스트로부터 직접 학습하는 사전 훈련 방법들은 지난 몇 년 동안 NLP를 혁신해 왔다(Dai&Le,2015; Peters et al.,2018; Howard&Ruder,2018; Radford et al.,2018; Devlin et al.,2018; Raffel et al.,2019). 자기회귀 및 masked language modeling과 같은 과제-비의존적 목표는 compute, model capacity, data에서 여러 자릿수 규모에 걸쳐 확장되어 능력을 꾸준히 향상시켰다. 표준화된 입출력 인터페이스로서 “text-to-text”의 개발은(McCann et al.,2018; Radford et al.,2019; Raffel et al.,2019)과제-비의존적 아키텍처가 특수한 출력 head나 데이터셋별 맞춤화의 필요를 제거하면서 다운스트림 데이터셋으로 zero-shot 전이할 수 있게 했다. GPT-3와 같은 대표 시스템들은(Brown et al.,2020)이제 데이터셋별 훈련 데이터가 거의 또는 전혀 필요하지 않으면서 많은 과제에서 맞춤형 모델들과 경쟁력이 있다.
이러한 결과는 웹 규모 텍스트 모음 내에서 현대적 사전 훈련 방법들이 접근할 수 있는 집합적 감독이 고품질 crowd-labeled NLP 데이터셋의 감독을 능가함을 시사한다. 그러나 컴퓨터 비전과 같은 다른 분야에서는 ImageNet과 같은 crowd-labeled 데이터셋에서 모델을 사전 훈련하는 것이 여전히 표준 관행이다(Deng et al.,2009). 웹 텍스트로부터 직접 학습하는 확장 가능한 사전 훈련 방법들이 컴퓨터 비전에서도 유사한 돌파구를 가져올 수 있을까? 선행 연구는 고무적이다.
20년도 더 전에Mori et al. (1999)이미지와 짝지어진 텍스트 문서의 명사와 형용사를 예측하도록 모델을 훈련하여 content based image retrieval을 개선하는 것을 탐구했다.Quattoni et al. (2007)이미지와 관련된 캡션의 단어를 예측하도록 훈련된 분류기의 weight space에서 manifold learning을 통해 더 데이터 효율적인 이미지 표현을 학습할 수 있음을 보였다.Srivastava&Salakhutdinov (2012)저수준 이미지 및 텍스트 태그 특징 위에서 multimodal Deep Boltzmann Machines를 훈련하여 deep representation learning을 탐구했다.Joulin et al. (2016)이 연구 흐름을 현대화하고, 이미지 캡션의 단어를 예측하도록 훈련된 CNN이 유용한 이미지 표현을 학습함을 보였다. 그들은 YFCC100M 데이터셋의 이미지 제목, 설명, 해시태그 메타데이터를(Thomee et al.,2016)bag-of-words multi-label classification 과제로 변환하고, AlexNet을 사전 훈련하면(Krizhevsky et al.,2012)이러한 레이블을 예측하도록 학습된 표현이 전이 과제에서 ImageNet 기반 사전 훈련과 유사하게 수행됨을 보였다.Li et al. (2017)그런 다음 이 접근법을 개별 단어에 더해 phrase n-grams를 예측하도록 확장했으며, 학습된 시각 n-grams 사전을 기반으로 대상 클래스에 점수를 매기고 가장 높은 점수의 클래스를 예측함으로써 그들의 시스템이 다른 이미지 분류 데이터셋으로 zero-shot 전이할 수 있음을 보였다. 더 최근의 아키텍처와 사전 훈련 접근법을 채택한 VirTex(Desai&Johnson,2020), ICMLM(Bulent Sariyildiz et al.,2020), 그리고 ConVIRT(Zhang et al.,2020)은 최근 transformer 기반 language modeling, masked language modeling, contrastive objectives가 텍스트로부터 이미지 표현을 학습할 잠재력을 보였다.
개념 증명으로서는 흥미롭지만, 이미지 표현 학습에 자연어 감독을 사용하는 것은 여전히 드물다. 이는 흔한 벤치마크에서 보인 성능이 대안적 접근법보다 훨씬 낮기 때문일 가능성이 크다. 예를 들어,Li et al. (2017)는 zero-shot 설정에서 ImageNet 정확도 11.5%에만 도달한다. 이는 현재 state of the art의 88.4% 정확도보다 훨씬 낮다(Xie et al.,2020). 이는 고전적 컴퓨터 비전 접근법의 50% 정확도보다도 낮다(Deng et al.,2012). 대신, 더 좁은 범위이지만 잘 표적화된 weak supervision 사용이 성능을 향상시켜 왔다.Mahajan et al. (2018)은 Instagram 이미지에서 ImageNet 관련 해시태그를 예측하는 것이 효과적인 사전 훈련 과제임을 보였다. ImageNet에 fine-tune했을 때 이러한 사전 훈련 모델들은 정확도를 5% 이상 높이고 당시의 전반적인 state of the art를 개선했다.Kolesnikov et al. (2019)그리고Dosovitskiy et al. (2020)또한 noisily labeled JFT-300M 데이터셋의 클래스를 예측하도록 모델을 사전 훈련함으로써 더 넓은 전이 벤치마크 집합에서 큰 향상을 보였다.
이 연구 흐름은 제한된 양의 감독된 “gold-labels”로부터 학습하는 것과 사실상 무제한의 원시 텍스트로부터 학습하는 것 사이의 현재 실용적 중간 지점을 나타낸다. 그러나 타협이 없는 것은 아니다. 두 연구 모두 감독을 각각 1000개와 18291개의 클래스로 신중하게 설계하고, 그 과정에서 제한한다. 자연어는 그 일반성을 통해 훨씬 더 넓은 시각 개념 집합을 표현할 수 있고, 따라서 감독할 수 있다. 두 접근법 모두 예측을 수행하기 위해 정적 softmax 분류기를 사용하며 동적 출력 메커니즘이 없다. 이는 그 유연성을 심각하게 줄이고 “zero-shot” 능력을 제한한다.
이러한 weakly supervised 모델들과 자연어로부터 직접 이미지 표현을 학습하는 최근 탐구 사이의 중요한 차이는 규모이다. 반면Mahajan et al. (2018)그리고Kolesnikov et al. (2019)은 수백만에서 수십억 개의 이미지에 대해 accelerator years 동안 모델을 훈련했지만, VirTex, ICMLM, ConVIRT는 10만에서 20만 개의 이미지에 대해 accelerator days 동안 훈련했다. 이 연구에서 우리는 이 간극을 메우고, 대규모 자연어 감독으로 훈련된 이미지 분류기의 행동을 연구한다. 인터넷에서 공개적으로 이용 가능한 이러한 형태의 대량 데이터에 힘입어, 우리는 4억 개의 (image, text) 쌍으로 된 새로운 데이터셋을 만들고, ConVIRT의 단순화된 버전을 처음부터 훈련한 것, 즉 Contrastive Language-Image Pre-training을 뜻하는 CLIP이 자연어 감독으로부터 학습하는 효율적인 방법임을 보인다. 우리는 거의 2 orders of magnitude의 compute에 걸친 8개 모델 시리즈를 훈련하여 CLIP의 확장성을 연구하고, 전이 성능이 compute의 매끄럽게 예측 가능한 함수임을 관찰한다(Hestness et al.,2017; Kaplan et al.,2020). 우리는 CLIP이 GPT 계열과 유사하게 사전 훈련 중 OCR, geo-localization, action recognition 등 넓은 과제 집합을 수행하는 법을 학습함을 발견한다. 우리는 30개 이상의 기존 데이터셋에서 CLIP의 zero-shot 전이 성능을 벤치마킹하여 이를 측정하고, 이전 과제별 감독 모델들과 경쟁력이 있을 수 있음을 발견한다. 또한 linear-probe representation learning 분석으로 이러한 발견을 확인하고, CLIP이 공개적으로 이용 가능한 최고의 ImageNet 모델을 능가하면서도 계산적으로 더 효율적임을 보인다. 추가로 우리는 zero-shot CLIP 모델들이 동등한 정확도의 supervised ImageNet 모델들보다 훨씬 더 robust함을 발견하는데, 이는 과제-비의존적 모델의 zero-shot 평가가 모델 능력을 훨씬 더 대표한다는 것을 시사한다. 이러한 결과는 중요한 정책적 및 윤리적 함의를 가지며, 우리는 이를 Section에서 고려한다7.
2 접근법
2.1 자연어 감독
우리 접근법의 핵심에는 자연어에 담긴 감독으로부터 지각을 학습한다는 아이디어가 있다. 서론에서 논의했듯이 이것은 결코 새로운 아이디어가 아니지만, 이 영역의 연구를 설명하는 데 사용되는 용어는 다양하고, 심지어 겉보기에는 모순적이며, 제시된 동기도 다양하다.Zhang et al. (2020), Gomez et al. (2017), Joulin et al. (2016), 그리고Desai&Johnson (2020)은 모두 이미지와 짝지어진 텍스트로부터 시각 표현을 학습하는 방법을 소개하지만, 그들의 접근법을 각각 unsupervised, self-supervised, weakly supervised, supervised라고 설명한다.
우리는 이 연구 흐름 전반에 공통적인 것이 사용된 특정 방법들의 세부 사항이 아니라, 훈련 신호로서 자연어를 인정하는 것임을 강조한다. 이 모든 접근법은 다음으로부터 학습하고 있다자연어 감독. 초기 연구가 topic model과 n-gram 표현을 사용할 때 자연어의 복잡성과 씨름했지만, deep contextual representation learning의 발전은 이제 우리가 이 풍부한 감독 원천을 효과적으로 활용할 도구를 갖추었음을 시사한다(McCann et al.,2017).
자연어로부터 학습하는 것은 다른 훈련 방법들에 비해 여러 잠재적 강점을 가진다. 자연어 감독은 이미지 분류를 위한 표준 crowd-sourced labeling에 비해 확장하기가 훨씬 쉬운데, 이는 주석이 표준적인 1-of-N majority vote “gold label”과 같은 고전적인 “machine learning compatible format”일 필요가 없기 때문이다. 대신, 자연어에서 작동하는 방법들은 인터넷의 방대한 텍스트에 담긴 감독으로부터 수동적으로 학습할 수 있다. 자연어로부터의 학습은 또한 대부분의 unsupervised 또는 self-supervised learning 접근법에 비해 중요한 장점을 가지는데, 그것은 표현을 “그저” 학습하는 것이 아니라 그 표현을 언어와 연결하여 유연한 zero-shot 전이를 가능하게 한다는 점이다. 다음 하위 절들에서 우리는 우리가 최종적으로 선택한 구체적인 접근법을 자세히 설명한다.
2.2 충분히 큰 데이터셋 만들기
기존 연구는 주로 세 가지 데이터셋, MS-COCO를 사용했다(Lin et al.,2014), Visual Genome(Krishna et al.,2017), 그리고 YFCC100M(Thomee et al.,2016). MS-COCO와 Visual Genome은 고품질 crowd-labeled 데이터셋이지만, 각각 약 100,000장의 훈련 사진으로 현대 기준으로는 작다. 비교하자면, 다른 컴퓨터 비전 시스템들은 최대 3.5billionInstagram 사진으로 훈련된다(Mahajan et al.,2018). 1억 장의 사진을 가진 YFCC100M은 가능한 대안이지만, 각 이미지의 메타데이터는 희박하고 품질이 다양하다. 많은 이미지가20160716_113957.JPG와 같은 자동 생성 파일명을 “titles”로 사용하거나 카메라 노출 설정에 대한 “descriptions”를 포함한다. 영어로 된 자연어 제목 및/또는 설명이 있는 이미지만 남기도록 필터링한 후, 데이터셋은 6배 줄어 단 1,500만 장의 사진만 남았다. 이는 ImageNet과 거의 같은 크기이다.
자연어 감독의 주요 동기는 인터넷에 공개적으로 이용 가능한 이러한 형태의 대량 데이터이다. 기존 데이터셋은 이 가능성을 적절히 반영하지 않으므로, 그 데이터셋들에서의 결과만 고려하면 이 연구 흐름의 잠재력을 과소평가하게 된다. 이를 해결하기 위해 우리는 인터넷의 다양한 공개적으로 이용 가능한 출처에서 수집한 4억 개의 (image, text) 쌍으로 이루어진 새로운 데이터셋을 구축했다. 가능한 한 넓은 시각 개념 집합을 포괄하려는 시도로, 우리는 구축 과정의 일부로 텍스트가 500,000개 query 집합 중 하나를 포함하는 (image, text) 쌍을 검색한다.111기본 query 목록은 영어판 Wikipedia에서 적어도 100번 등장하는 모든 단어이다. 여기에 pointwise mutual information이 높은 bi-grams와 특정 검색량 이상의 모든 Wikipedia 문서 이름을 추가한다. 마지막으로 query 목록에 아직 없는 모든 WordNet synsets를 추가한다.우리는 query당 최대 20,000개의 (image, text) 쌍을 포함하여 결과를 대략적으로 class balance한다. 결과 데이터셋은 GPT-2를 훈련하는 데 사용된 WebText 데이터셋과 비슷한 총 단어 수를 가진다. 우리는 이 데이터셋을 WebImageText의 약자인 WIT라고 부른다.
2.3 효율적인 사전 훈련 방법 선택하기
최첨단 컴퓨터 비전 시스템은 매우 많은 양의 compute를 사용한다.Mahajan et al. (2018)은 그들의 ResNeXt101-32x48d를 훈련하는 데 19 GPU years가 필요했고Xie et al. (2020)은 그들의 Noisy Student EfficientNet-L2를 훈련하는 데 33 TPUv3 core-years가 필요했다. 이 두 시스템이 단지 1000개의 ImageNet 클래스만 예측하도록 훈련되었다는 점을 고려하면, 자연어로부터 열린 집합의 시각 개념을 학습하는 과제는 벅차 보인다. 우리의 노력 과정에서 우리는 훈련 효율성이 자연어 감독을 성공적으로 확장하는 데 핵심임을 발견했고, 이 지표를 기반으로 최종 사전 훈련 방법을 선택했다.
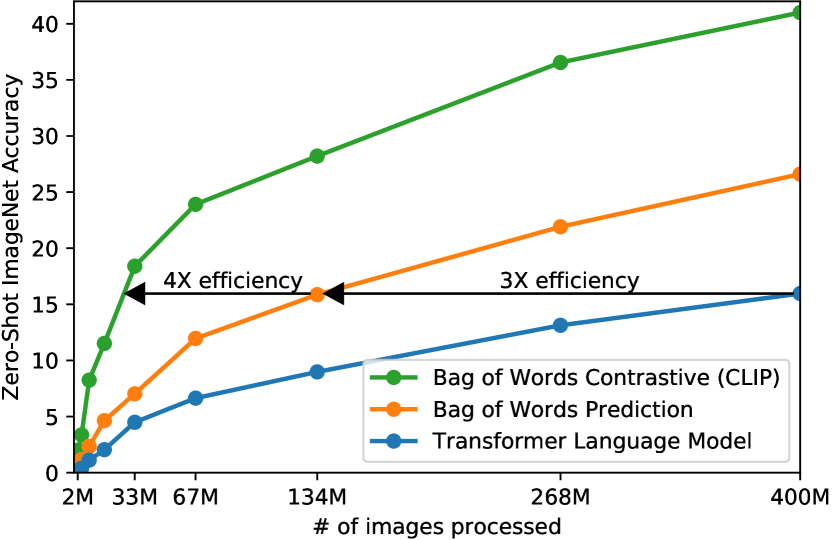
VirTex와 유사한 우리의 초기 접근법은 이미지의 캡션을 예측하기 위해 image CNN과 text transformer를 처음부터 공동으로 훈련했다. 그러나 우리는 이 방법을 효율적으로 확장하는 데 어려움을 겪었다. Figure에서2우리는 이미 그 ResNet-50 이미지 인코더보다 두 배의 compute를 사용하는 6,300만 parameter transformer language model이, 동일한 텍스트의 bag-of-words 인코딩을 예측하는 훨씬 더 단순한 기준선보다 ImageNet 클래스를 인식하는 데 세 배 더 느리게 학습함을 보인다.
이 두 접근법은 핵심적인 유사성을 공유한다. 그것들은 각 이미지에 동반된 텍스트의정확한단어를 예측하려고 한다. 이는 이미지와 함께 나타나는 설명, 댓글, 관련 텍스트가 매우 다양하기 때문에 어려운 과제이다. 이미지에 대한 contrastive representation learning의 최근 연구는 contrastive objectives가 그에 상응하는 predictive objective보다 더 나은 표현을 학습할 수 있음을 발견했다(Tian et al.,2019). 다른 연구는 이미지의 generative models가 고품질 이미지 표현을 학습할 수 있지만, 같은 성능의 contrastive models보다 한 자릿수 이상 더 많은 compute가 필요함을 발견했다(Chen et al.,2020a). 이러한 발견에 주목하여, 우리는 그 텍스트의 정확한 단어가 아니라 어떤 텍스트가전체로서어떤 이미지와 짝지어지는지만 예측하는, 잠재적으로 더 쉬운 proxy task를 풀도록 시스템을 훈련하는 것을 탐구했다. 동일한 bag-of-words 인코딩 기준선에서 시작하여, Figure에서 predictive objective를 contrastive objective로 바꾸었고2ImageNet으로의 zero-shot 전이 속도에서 추가적인 4x 효율성 향상을 관찰했다.
다음의 배치가 주어졌을 때(image, text) 쌍, CLIP은 배치 전체에서 가능한(image, text) 짝짓기 중 어떤 것이 실제로 발생했는지 예측하도록 훈련된다. 이를 위해 CLIP은 이미지 인코더와 텍스트 인코더를 공동으로 훈련하여 배치 내실제 쌍의 이미지 및 텍스트 임베딩의 cosine similarity를 최대화하는 동시에잘못된 짝짓기의 임베딩들의 cosine similarity를 최소화함으로써 multi-modal embedding space를 학습한다. 우리는 이러한 similarity scores에 대해 symmetric cross entropy loss를 최적화한다. Figure에서3우리는 CLIP 구현의 핵심에 대한 pseudocode를 포함한다. 우리가 아는 한 이 배치 구성 기법과 목표는 deep metric learning 영역에서 처음 도입되었으며 다음으로 불렸다multi-class N-pair loss Sohn (2016), contrastive representation learning을 위해 다음에 의해 대중화되었고Oord et al. (2018)InfoNCE loss로서, 그리고 최근 의료 영상 영역에서 contrastive (text, image) representation learning을 위해 다음에 의해 적응되었다Zhang et al. (2020).
우리 사전 훈련 데이터셋의 큰 크기 때문에 over-fitting은 주요한 우려가 아니며, CLIP 훈련의 세부 사항은 다음의 구현과 비교해 단순화된다Zhang et al. (2020). 우리는 ImageNet weights로 이미지 인코더를 초기화하거나 pre-trained weights로 텍스트 인코더를 초기화하지 않고 CLIP을 처음부터 훈련한다. 우리는 representation과 contrastive embedding space 사이의 non-linear projection을 사용하지 않는데, 이는 다음에 의해 도입된 변경이다Bachman et al. (2019)그리고 다음에 의해 대중화되었다Chen et al. (2020b). 대신 우리는 각 인코더의 representation에서 multi-modal embedding space로 매핑하기 위해 linear projection만 사용한다. 우리는 두 버전 사이의 훈련 효율성 차이를 발견하지 못했으며, non-linear projections가 현재 이미지 전용 self-supervised representation learning 방법들의 세부 사항과 co-adapted될 수 있다고 추측한다. 우리는 또한 text transformation function을 제거한다다음으로부터Zhang et al. (2020)이는 텍스트에서 단일 문장을 균등하게 샘플링하는데, CLIP의 사전 훈련 데이터셋에 있는 많은 (image, text) 쌍은 단일 문장뿐이기 때문이다. 우리는 또한 image transformation function을 단순화한다. resized images에서의 random square crop이 훈련 중 사용되는 유일한 data augmentation이다. 마지막으로, softmax에서 logits의 범위를 제어하는 temperature parameter,, 는 hyper-parameter로 튜닝하는 것을 피하기 위해 log-parameterized multiplicative scalar로 훈련 중 직접 최적화된다.

2.4 모델 선택 및 확장
우리는 이미지 인코더에 대해 두 가지 서로 다른 아키텍처를 고려한다. 첫 번째로, 우리는 ResNet-50을 사용한다(He et al.,2016a)이미지 인코더의 기본 아키텍처로 사용하는데, 이는 그것의 광범위한 채택과 입증된 성능 때문이다. 우리는 다음의 ResNet-D 개선을 사용하여 원래 버전에 여러 수정을 가한다He et al. (2019)그리고 다음의 antialiased rect-2 blur poolingZhang (2019). 또한 global average pooling layer를 attention pooling mechanism으로 대체한다. attention pooling은 “transformer-style” multi-head QKV attention의 단일 layer로 구현되며, query는 이미지의 global average-pooled representation에 조건화된다. 두 번째 아키텍처로, 우리는 최근 도입된 Vision Transformer (ViT)를 실험한다(Dosovitskiy et al.,2020). 우리는 transformer 전에 결합된 patch 및 position embeddings에 추가 layer normalization을 더하고 약간 다른 initialization scheme을 사용하는 사소한 수정만으로 그들의 구현을 밀접하게 따른다.
텍스트 인코더는 Transformer이다(Vaswani et al.,2017)다음에 설명된 아키텍처 수정과 함께Radford et al. (2019). 기본 크기로 우리는 8 attention heads를 가진 63M-parameter, 12-layer, 512-wide 모델을 사용한다. transformer는 49,152 vocab size의 lower-cased byte pair encoding (BPE) 텍스트 표현에서 작동한다(Sennrich et al.,2015). 계산 효율성을 위해 max sequence length는 76으로 제한되었다. 텍스트 sequence는[SOS]및[EOS]tokens로 둘러싸이며, transformer의 최고 layer에서[EOS]token의 activations가 텍스트의 feature representation으로 취급되어 layer normalized된 다음 multi-modal embedding space로 linearly projected된다. 텍스트 인코더에서는 pre-trained language model로 초기화하거나 language modeling을 auxiliary objective로 추가할 수 있는 능력을 보존하기 위해 masked self-attention이 사용되었지만, 이에 대한 탐구는 future work로 남겨둔다.
이전 컴퓨터 비전 연구는 종종 width를 증가시켜 모델을 확장해 왔지만(Mahajan et al.,2018)또는 depth를(He et al.,2016a)고립적으로 증가시켰지만, ResNet 이미지 인코더에 대해서 우리는 다음의 접근법을 채택한다Tan&Le (2019)이는 width, depth, resolution 모두에 걸쳐 추가 compute를 할당하는 것이 모델의 한 차원에만 할당하는 것보다 우수함을 발견했다. 반면Tan&Le (2019)은 그들의 EfficientNet 아키텍처에 대해 각 차원에 할당되는 compute의 비율을 조정하지만, 우리는 모델의 width, depth, resolution을 증가시키는 데 추가 compute를 균등하게 할당하는 단순한 기준선을 사용한다. 텍스트 인코더의 경우, 우리는 모델의 width만 ResNet의 계산된 width 증가에 비례하도록 확장하고 depth는 전혀 확장하지 않는데, CLIP의 성능이 텍스트 인코더의 capacity에 덜 민감하다는 것을 발견했기 때문이다.
2.5 훈련
우리는 5개의 ResNets와 3개의 Vision Transformers 시리즈를 훈련한다. ResNets의 경우 ResNet-50, ResNet-101, 그리고 EfficientNet-style model scaling을 따르고 ResNet-50의 compute를 각각 약 4x, 16x, 64x 사용하는 3개를 더 훈련한다. 이들은 각각 RN50x4, RN50x16, RN50x64로 표기된다. Vision Transformers의 경우 ViT-B/32, ViT-B/16, ViT-L/14를 훈련한다. 우리는 모든 모델을 32 epochs 동안 훈련한다. 우리는 Adam optimizer를 사용한다(Kingma&Ba,2014)분리된 가중치 감쇠 정규화와 함께(Loshchilov&Hutter,2017)gain이나 bias가 아닌 모든 가중치에 적용하고, cosine schedule을 사용해 learning rate를 감쇠시킨다(Loshchilov&Hutter,2016). 초기 hyper-parameter들은 1 epoch 동안 학습될 때 baseline ResNet-50 모델에서 grid search, random search, 그리고 수동 튜닝의 조합을 사용하여 설정되었다. 그런 다음 계산 제약 때문에 hyper-parameter들은 더 큰 모델들에 대해 휴리스틱하게 조정되었다. 학습 가능한 temperature parameter는 다음의 0.07에 해당하는 값으로 초기화되었다(Wu et al.,2018)그리고 logits를 100보다 크게 스케일링하지 못하도록 clip했는데, 이는 학습 불안정성을 방지하는 데 필요하다는 것을 발견했기 때문이다. 우리는 32,768의 매우 큰 minibatch size를 사용한다. Mixed-precision(Micikevicius et al.,2017)은 학습을 가속하고 메모리를 절약하기 위해 사용되었다. 추가 메모리를 절약하기 위해, gradient checkpointing(Griewank&Walther,2000; Chen et al.,2016), half-precision Adam statistics(Dhariwal et al.,2020), 그리고 half-precision stochastically rounded text encoder weights가 사용되었다. embedding similarity의 계산도 개별 GPU들이 그들의 local batch of embeddings에 필요한 pairwise similarity의 부분집합만 계산하도록 sharding되었다. 가장 큰 ResNet 모델인 RN50x64는 592개의 V100 GPU에서 학습하는 데 18일이 걸렸고, 가장 큰 Vision Transformer는 256개의 V100 GPU에서 12일이 걸렸다. ViT-L/14의 경우 우리는 또한 FixRes와 유사하게 성능을 높이기 위해 한 추가 epoch 동안 더 높은 336 pixel resolution에서 pre-train한다(Touvron et al.,2019). 우리는 이 모델을 ViT-L/14@336px로 표기한다. 달리 명시되지 않는 한, 이 논문에서 “CLIP”으로 보고된 모든 결과는 우리가 가장 잘 수행한다고 발견한 이 모델을 사용한다.
3 실험
3.1 Zero-Shot Transfer
3.1.1 동기
컴퓨터 비전에서 zero-shot learning은 보통 image classification에서 보지 못한 object category로 일반화하는 연구를 가리킨다(Lampert et al.,2009). 우리는 대신 이 용어를 더 넓은 의미로 사용하고, 보지 못한 dataset으로의 일반화를 연구한다. 우리는 이를 보지 못한 task를 수행하는 것에 대한 proxy로 동기화하며, 이는 다음의 zero-data learning 논문에서 지향된 바와 같다Larochelle et al. (2008). unsupervised learning 분야의 많은 연구가 machine learning system의representation learning능력에 초점을 맞추는 반면, 우리는 machine learning system의task-learning능력을 측정하는 방법으로 zero-shot transfer를 연구하는 것에 동기를 둔다. 이 관점에서 dataset은 특정 distribution에서 task에 대한 성능을 평가한다. 그러나 많은 인기 있는 computer vision dataset들은 특정 task의 성능을 측정하기보다는 generic image classification method의 개발을 안내하기 위한 benchmark로 주로 연구 커뮤니티에 의해 만들어졌다. SVHN dataset이 Google Street View 사진의 distribution에서 street number transcription task를 측정한다고 말하는 것은 합리적이지만, CIFAR-10 dataset이 어떤 “real” task를 측정하는지는 불분명하다. 그러나 CIFAR-10이 어떤 distribution에서 추출되었는지는 명확하다 - TinyImages(Torralba et al.,2008). 이러한 종류의 dataset에서 zero-shot transfer는 task generalization보다는 CLIP의 distribution shift와 domain generalization에 대한 robustness 평가에 더 가깝다. 이에 초점을 맞춘 분석은 Section3.3을 참조하라.
우리가 아는 한, Visual N-Grams(Li et al.,2017)는 위에서 설명한 방식으로 기존 image classification dataset으로의 zero-shot transfer를 처음 연구했다. 또한 우리가 아는 한, generically pre-trained model을 사용하여 standard image classification dataset으로의 zero-shot transfer를 연구한 유일한 다른 작업이며, CLIP을 맥락화하기 위한 최고의 기준점 역할을 한다. 그들의 접근법은 142,806개의 visual n-grams(1-gram부터 5-grams까지 포괄)의 dictionary parameter를 학습하고, 주어진 image에 대한 모든 text n-grams의 probability를 최대화하기 위해 Jelinek-Mercer smoothing의 differential version을 사용하여 이러한 n-grams를 최적화한다. zero-shot transfer를 수행하기 위해, 그들은 먼저 dataset의 각 class name의 text를 그 n-gram representation으로 변환한 다음, 그들의 model에 따라 그 probability를 계산하여 가장 높은 score를 가진 것을 예측한다.
task learning의 평가로서 zero-shot transfer를 연구하는 데 대한 우리의 초점은 NLP 분야에서 task learning을 보여주는 작업에서 영감을 받았다. 우리가 아는 한Liu et al. (2018)는 Wikipedia article을 생성하도록 학습된 language model이 언어 간 이름을 신뢰성 있게 transliterate하는 것을 배웠을 때 task learning을 “unexpected side-effect”로 처음 식별했다. GPT-1(Radford et al.,2018)은 supervised fine-tuning을 개선하기 위한 transfer learning method로서 pre-training에 초점을 맞추었지만, supervised adaption 없이 pre-training 과정 동안 네 가지 heuristic zero-shot transfer method의 성능이 꾸준히 향상됨을 보여주는 ablation study도 포함했다. 이 분석은 GPT-2의 기반이 되었다(Radford et al.,2019)이는 zero-shot transfer를 통해 language model의 task-learning capabilities를 연구하는 데 전적으로 초점을 맞추었다.
3.1.2 Zero-Shot Transfer를 위한 CLIP 사용
CLIP은 image와 text snippet이 그 dataset에서 함께 pair되어 있는지 예측하도록 pre-trained된다. zero-shot classification을 수행하기 위해, 우리는 이 capability를 재사용한다. 각 dataset에 대해, dataset의 모든 class name을 potential text pairing의 set으로 사용하고 CLIP에 따라 가장 probable한 (image, text) pair를 예측한다. 조금 더 자세히 말하면, 우리는 먼저 각각의 encoder로 image의 feature embedding과 possible texts의 set의 feature embedding을 계산한다. 그런 다음 이러한 embeddings의 cosine similarity가 계산되고, temperature parameter로 scaling되며, softmax를 통해 probability distribution으로 normalized된다. 이 prediction layer는 L2-normalized inputs, L2-normalized weights, bias 없음, temperature scaling을 가진 multinomial logistic regression classifier라는 점에 유의하라. 이렇게 해석하면, image encoder는 image에 대한 feature representation을 계산하는 computer vision backbone이고 text encoder는 hypernetwork이다(Ha et al.,2016)이는 class들이 나타내는 visual concept을 지정하는 text를 기반으로 linear classifier의 weights를 생성한다.Lei Ba et al. (2015)는 이러한 형태의 zero-shot image classifier를 처음 소개했으며, natural language로부터 classifier를 생성한다는 아이디어는 적어도 다음까지 거슬러 올라간다Elhoseiny et al. (2013). 이 해석을 계속하면, CLIP pre-training의 모든 step은 class당 1개의 example을 포함하고 natural language descriptions를 통해 정의된 총 32,768개의 class를 가진 computer vision dataset에 대한 randomly created proxy의 성능을 최적화하는 것으로 볼 수 있다. zero-shot evaluation을 위해, 우리는 text encoder에 의해 계산된 후 zero-shot classifier를 cache하고 모든 후속 prediction에 재사용한다. 이를 통해 이를 생성하는 비용을 dataset의 모든 prediction에 걸쳐 amortize할 수 있다.
3.1.3 Visual N-Grams와의 초기 비교
| aYahoo | ImageNet | SUN | |
| Visual N-Grams | 72.4 | 11.5 | 23.0 |
| CLIP | 98.4 | 76.2 | 58.5 |
Table1에서 우리는 Visual N-Grams를 CLIP과 비교한다. 최고의 CLIP model은 ImageNet에서 accuracy를 proof of concept 수준의 11.5%에서 76.2%로 향상시키며, 이 dataset에서 이용 가능한 128만 개의 crowd-labeled training example을 전혀 사용하지 않고도 original ResNet-50의 성능과 맞먹는다. 또한 CLIP model의 top-5 accuracy는 그들의 top-1보다 눈에 띄게 높으며, 이 model은 95% top-5 accuracy를 가져 Inception-V4와 맞먹는다(Szegedy et al.,2016). zero-shot setting에서 강력한 fully supervised baseline의 성능과 맞먹는 능력은 CLIP이 flexible하고 practical한 zero-shot computer vision classifier를 향한 중요한 단계임을 시사한다. 위에서 언급했듯이 Visual N-Grams와의 비교는 CLIP의 성능을 맥락화하기 위한 것이며, 두 system 사이의 성능 관련 많은 차이가 통제되지 않았기 때문에 CLIP과 Visual N-Grams 간의 직접적인 method comparison으로 해석되어서는 안 된다. 예를 들어, 우리는 10x 더 큰 dataset에서 학습하고, prediction당 거의 100x 더 많은 compute를 요구하는 vision model을 사용하며, 아마도 그들의 training compute의 1000x 이상을 사용했고, Visual N-Grams가 발표될 때 존재하지 않았던 transformer-based model을 사용한다. 더 가까운 비교로서, 우리는 Visual N-Grams가 학습된 동일한 YFCC100M dataset에서 CLIP ResNet-50을 학습했고, V100 GPU day 내에 그들이 보고한 ImageNet performance와 맞먹는 것을 발견했다. 이 baseline도 Visual N-Grams처럼 pre-trained ImageNet weights로 초기화된 것이 아니라 scratch에서 학습되었다.
CLIP은 또한 보고된 다른 2개 dataset에서도 Visual N-Grams를 능가한다. aYahoo에서 CLIP은 error 수를 95% 줄이고, SUN에서 CLIP은 Visual N-Grams의 accuracy를 두 배 이상 높인다. 더 포괄적인 분석과 stress test를 수행하기 위해, 우리는 AppendixA에 자세히 설명된 훨씬 더 큰 evaluation suite를 구현한다. 전체적으로 우리는 Visual N-Grams에서 보고된 3개 dataset에서 30개가 넘는 dataset을 포함하도록 확장하고, 결과를 맥락화하기 위해 50개가 넘는 기존 computer vision system과 비교한다.
3.1.4 Prompt Engineering과 Ensembling
대부분의 standard image classification dataset은 natural language 기반 zero-shot transfer를 가능하게 하는 class를 naming하거나 describing하는 정보를 부차적인 것으로 취급한다. 대다수의 dataset은 image에 label의 numeric id만 annotate하고, 이러한 id를 English name으로 다시 mapping하는 file을 포함한다. Flowers102와 GTSRB 같은 일부 dataset은 release된 version에 이 mapping을 전혀 포함하지 않는 것으로 보여 zero-shot transfer를 완전히 방지한다.222Alec은 이 project 과정에서 원래 예상했던 것보다 flower species와 German traffic signs에 대해 훨씬 더 많이 배웠다.많은 dataset에서 우리는 이러한 label들이 다소 무계획적으로 선택되었을 수 있으며, 성공적으로 transfer하기 위해 task description에 의존하는 zero-shot transfer와 관련된 문제를 예상하지 않는다는 것을 관찰했다.
흔한 문제는 polysemy이다. class의 name이 CLIP의 text encoder에 제공되는 유일한 정보일 때, context의 부족으로 인해 어떤 word sense가 의도되었는지 구별할 수 없다. 어떤 경우에는 같은 단어의 여러 meaning이 같은 dataset의 다른 class로 포함될 수도 있다! 이는 ImageNet에서 발생하는데, ImageNet에는 construction crane과 나는 crane이 모두 포함되어 있다. 또 다른 예는 Oxford-IIIT Pet dataset의 class에서 발견되며, boxer라는 단어는 context상 명백히 개의 breed를 가리키지만, context가 없는 text encoder에게는 athlete의 한 종류를 가리킬 가능성도 동일하게 있다.
우리가 마주친 또 다른 문제는 pre-training dataset에서 image와 paired된 text가 단 하나의 word인 경우가 비교적 드물다는 것이다. 보통 text는 어떤 방식으로든 image를 설명하는 full sentence이다. 이 distribution gap을 메우는 데 도움을 주기 위해, 우리는 prompt template “A photo of a {label}.”를 사용하는 것이 text가 image의 content에 관한 것임을 명시하는 데 도움이 되는 좋은 default임을 발견했다. 이는 종종 label text만 사용하는 baseline보다 performance를 향상시킨다. 예를 들어, 이 prompt만 사용해도 ImageNet에서 accuracy가 1.3% 향상된다.
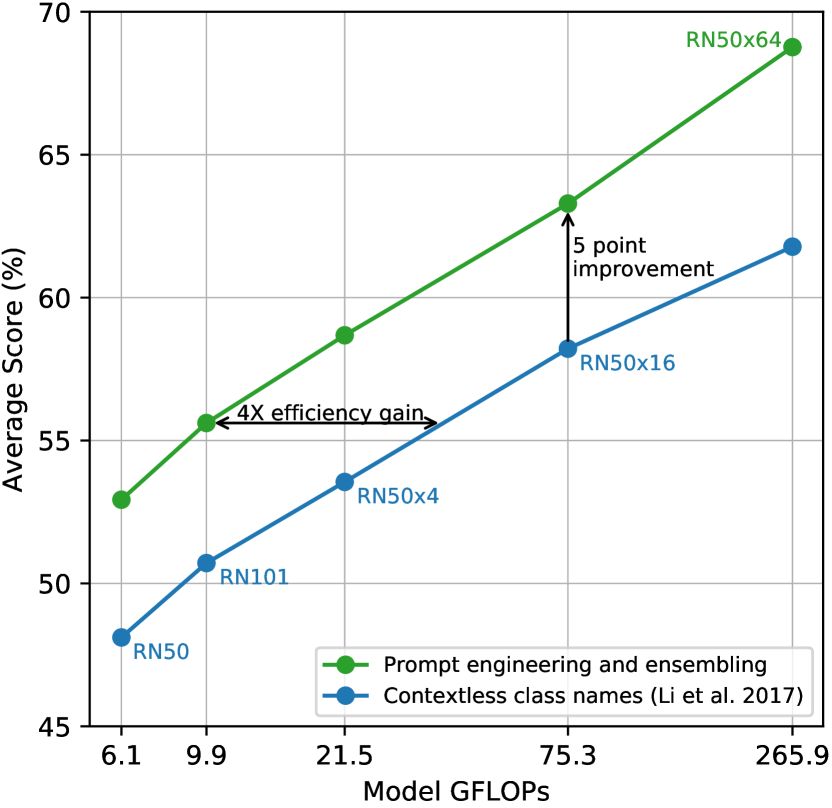
GPT-3 주변의 “prompt engineering” 논의와 유사하게(Brown et al.,2020; Gao et al.,2020), 우리는 또한 각 task에 맞게 prompt text를 customizing함으로써 zero-shot performance가 크게 향상될 수 있음을 관찰했다. 몇 가지 비 exhaustive한 예는 다음과 같다. 우리는 여러 fine-grained image classification dataset에서 category를 명시하는 것이 도움이 된다는 것을 발견했다. 예를 들어 Oxford-IIIT Pets에서, “A photo of a {label}, a type of pet.”를 사용해 context를 제공하는 것이 잘 작동했다. 마찬가지로, Food101에서a type of food를 명시하고 FGVC Aircraft에서a type of aircraft를 명시하는 것도 도움이 되었다. OCR dataset의 경우, 인식할 text나 number를 따옴표로 둘러싸는 것이 performance를 향상시킨다는 것을 발견했다. 마지막으로, satellite image classification dataset에서는 image가 이러한 형태임을 명시하는 것이 도움이 되었고 우리는 “a satellite photo of a {label}.”.
우리는 또한 performance를 향상시키는 또 다른 방법으로 여러 zero-shot classifier에 대한 ensembling을 실험했다. 이러한 classifier들은 ‘A photo of a big {label}”와 “A photo of a small {label}” 같은 서로 다른 context prompt를 사용하여 계산된다. 우리는 probability space 대신 embedding space 위에서 ensemble을 구성한다. 이를 통해 averaged text embeddings의 단일 set을 cache할 수 있으므로, 많은 prediction에 걸쳐 amortize될 때 ensemble의 compute cost는 single classifier를 사용하는 것과 같다. 우리는 생성된 많은 zero-shot classifier 전반의 ensembling이 performance를 신뢰성 있게 향상시키는 것을 관찰했으며, 이를 대부분의 dataset에 사용한다. ImageNet에서 우리는 80개의 서로 다른 context prompt를 ensemble하며, 이는 위에서 논의한 single default prompt보다 performance를 추가로 3.5% 향상시킨다. 함께 고려할 때, prompt engineering과 ensembling은 ImageNet accuracy를 거의 5% 향상시킨다. Figure4에서 우리는 prompt engineering과 ensembling이 class name을 직접 embedding하는 contextless baseline approach와 비교하여 CLIP model set의 performance를 어떻게 바꾸는지 시각화한다. 이는 다음에서 수행된 방식이다Li et al. (2017).
3.1.5 Zero-Shot CLIP Performance 분석
computer vision을 위한 task-agnostic zero-shot classifier는 충분히 연구되지 않았기 때문에, CLIP은 이러한 type의 model을 더 잘 이해할 수 있는 유망한 기회를 제공한다. 이 section에서 우리는 CLIP의 zero-shot classifier의 다양한 property에 대한 study를 수행한다. 첫 번째 질문으로, 우리는 zero-shot classifier가 얼마나 잘 수행하는지 단순히 살펴본다. 이를 맥락화하기 위해, 우리는 간단한 off-the-shelf baseline의 performance와 비교한다: canonical ResNet-50의 features 위에 fully supervised, regularized, logistic regression classifier를 fitting하는 것이다. Figure5에서 우리는 27개 dataset 전반에 걸쳐 이 비교를 보여준다. dataset과 setup의 details는 AppendixA를 참조하라.
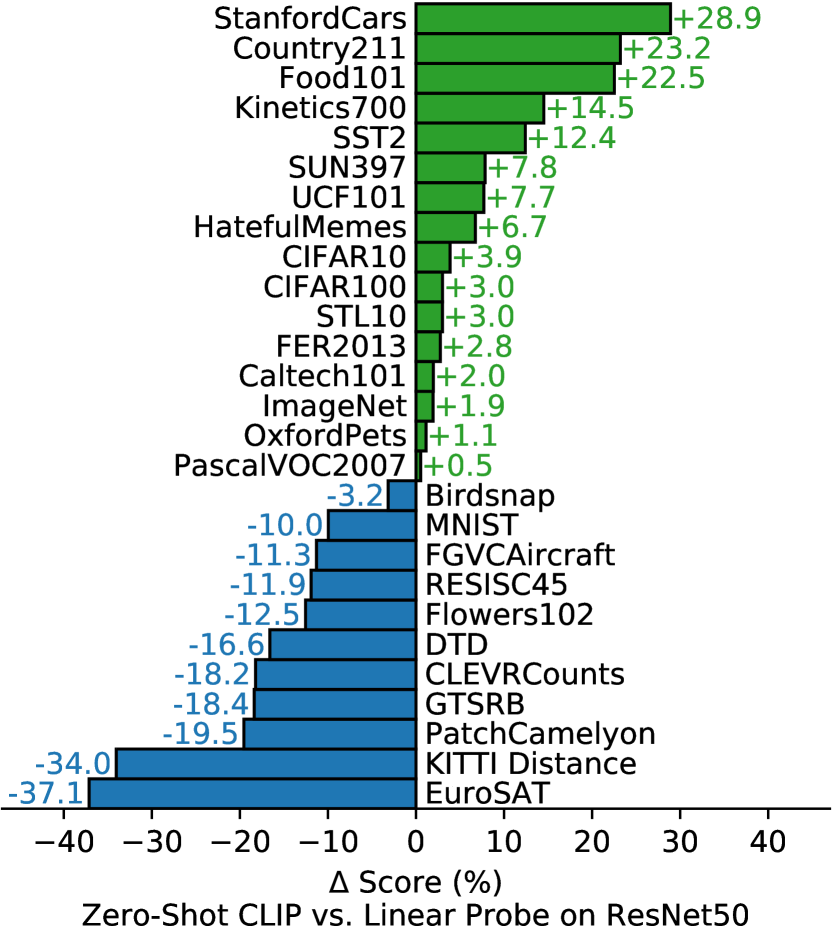
Zero-shot CLIP은 이 baseline을 그렇지 않은 경우보다 약간 더 자주 능가하며, 27개 dataset 중 16개에서 이긴다. 개별 dataset을 살펴보면 흥미로운 behavior가 드러난다. fine-grained classification task에서 우리는 performance의 넓은 spread를 관찰한다. 이러한 dataset 중 두 개, Stanford Cars와 Food101에서 zero-shot CLIP은 ResNet-50 features에 대한 logistic regression을 20% 넘게 능가하는 반면, 다른 두 개, Flowers102와 FGVCAircraft에서는 zero-shot CLIP이 10% 넘게 낮은 성능을 보인다. OxfordPets와 Birdsnap에서는 performance가 훨씬 더 가깝다. 우리는 이러한 차이가 주로 WIT와 ImageNet 사이의 per-task supervision 양의 차이 때문이라고 의심한다. ImageNet, CIFAR10/100, STL10, PascalVOC2007 같은 “general” object classification dataset에서는 performance가 비교적 유사하며 모든 경우에 zero-shot CLIP에 약간의 advantage가 있다. STL10에서 CLIP은 전체 99.3%를 달성하며, training example을 전혀 사용하지 않았음에도 새로운 state of the art로 보인다. Zero-shot CLIP은 video에서 action recognition을 측정하는 두 dataset에서 ResNet-50을 크게 능가한다. Kinetics700에서 CLIP은 ResNet-50을 14.5% 능가한다. Zero-shot CLIP은 또한 UCF101에서 ResNet-50의 features를 7.7% 능가한다. 우리는 이것이 ImageNet의 noun-centric object supervision과 비교하여 natural language가 verb가 포함된 visual concept에 더 넓은 supervision을 제공하기 때문이라고 추측한다.
zero-shot CLIP이 눈에 띄게 낮은 성능을 보이는 곳을 살펴보면, satellite image classification(EuroSAT 및 RESISC45), lymph node tumor detection(PatchCamelyon), synthetic scene에서 object counting(CLEVRCounts), German traffic sign recognition(GTSRB) 같은 self-driving 관련 task, 가장 가까운 car까지의 distance 인식(KITTI Distance)과 같은 여러 specialized, complex, 또는 abstract task에서 zero-shot CLIP이 상당히 약하다는 것을 알 수 있다. 이러한 결과는 더 complex한 task에서 zero-shot CLIP의 poor capability를 강조한다. 대조적으로, non-expert human은 counting, satellite image classification, traffic sign recognition 같은 이러한 task 중 여러 가지를 robust하게 수행할 수 있어 상당한 개선 여지가 있음을 시사한다. 그러나 우리는 거의 모든 human(그리고 아마도 CLIP)에게 lymph node tumor classification처럼 learner가 prior experience가 없는 어려운 task에 대해 few-shot transfer가 아니라 zero-shot transfer를 측정하는 것이 meaningful evaluation인지 불분명하다는 점을 주의시킨다.
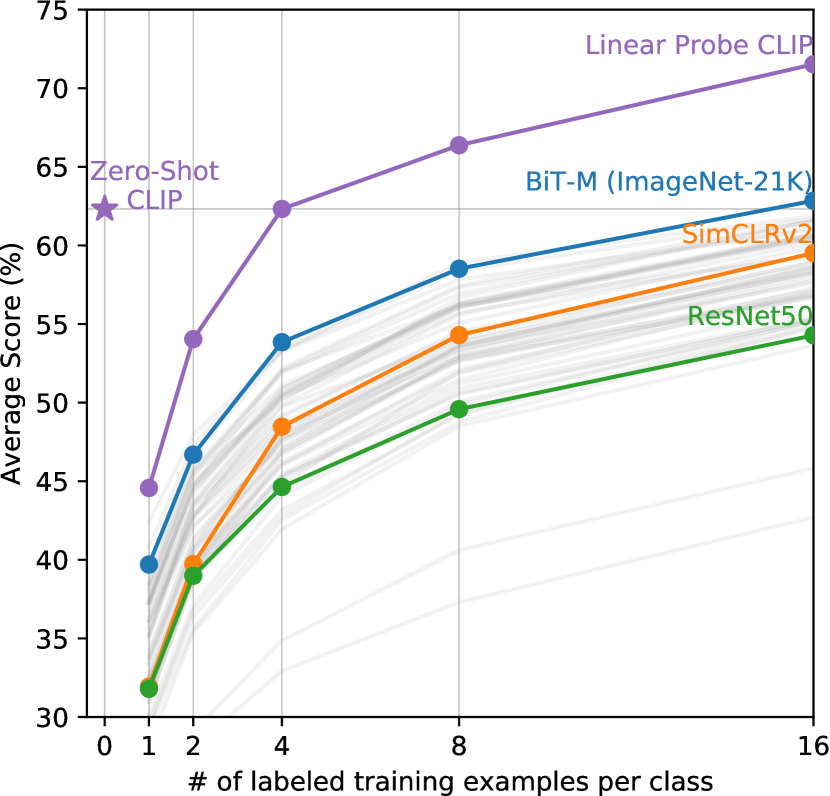
zero-shot performance를 fully supervised model과 비교하는 것은 CLIP의 task-learning capabilities를 맥락화하지만, few-shot method와의 비교는 zero-shot이 그 limit이므로 더 직접적인 비교이다. Figure6에서 우리는 zero-shot CLIP이 best publicly available ImageNet model, self-supervised learning method, 그리고 CLIP 자체를 포함한 많은 image model의 features 위에서 few-shot logistic regression과 어떻게 비교되는지 시각화한다. zero-shot이 one-shot보다 낮은 성능을 보일 것이라고 기대하는 것은 직관적이지만, 우리는 오히려 zero-shot CLIP이 같은 feature space에서 4-shot logistic regression의 performance와 맞먹는다는 것을 발견했다. 이는 zero-shot 접근법과 few-shot 접근법 사이의 중요한 차이 때문일 가능성이 높다. 첫째, CLIP의 zero-shot classifier는 natural language를 통해 생성되며, 이는 visual concept을 직접 specified(“communicated”)할 수 있게 한다. 대조적으로, “normal” supervised learning은 training example로부터 concept을 간접적으로 infer해야 한다. Context-less example-based learning은 특히 one-shot case에서 많은 서로 다른 hypothesis가 data와 consistent할 수 있다는 단점이 있다. 단일 image는 종종 많은 서로 다른 visual concept을 포함한다. capable learner가 image의 primary object가 demonstration되는 concept이라고 가정하는 것과 같은 visual cue와 heuristic을 exploit할 수는 있지만, 보장은 없다.
zero-shot과 few-shot performance 사이의 이 discrepancy에 대한 잠재적 해결책은 CLIP의 zero-shot classifier를 few-shot classifier의 weights에 대한 prior로 사용하는 것이다. 생성된 weights를 향한 L2 penalty를 추가하는 것은 이 아이디어의 straightforward implementation이지만, 우리는 hyperparameter optimization이 종종 이 regularizer의 너무 큰 값을 선택하여 결과적인 few-shot classifier가 “just” zero-shot classifier가 되도록 한다는 것을 발견했다. zero-shot transfer의 strength와 few-shot learning의 flexibility를 결합하는 더 나은 method에 대한 research는 future work의 유망한 방향이다.
zero-shot CLIP을 다른 model의 features 위에서 few-shot logistic regression과 비교할 때, zero-shot CLIP은 우리의 evaluation suite에서 best performing 16-shot classifier의 performance와 대략 맞먹는데, 이는 ImageNet-21K에서 학습된 BiT-M ResNet-152x2의 features를 사용한다. 우리는 JFT-300M에서 학습된 BiT-L model이 훨씬 더 잘 수행할 것이라고 확신하지만, 이러한 model들은 publicly released되지 않았다. BiT-M ResNet-152x2가 16-shot setting에서 best를 수행한다는 것은 다소 놀라운데, Section3.2에서 분석된 것처럼 fully supervised setting에서 Noisy Student EfficientNet-L2가 27개 dataset 전반에서 평균적으로 거의 5% 더 우수하기 때문이다.
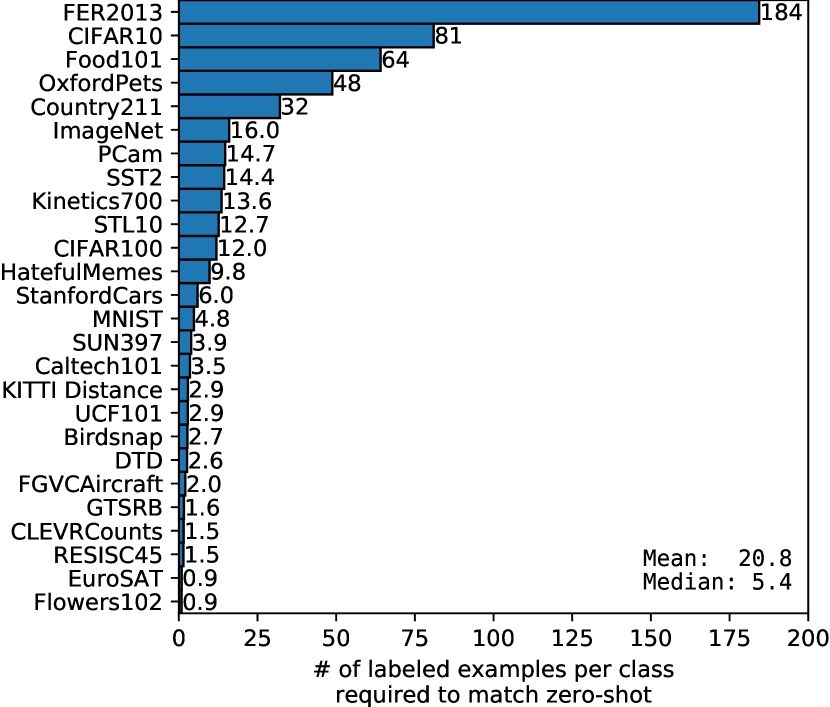
zero-shot CLIP과 few-shot logistic regression의 평균 performance를 연구하는 것 외에도, 우리는 개별 dataset에서의 performance도 검토한다. Figure7에서 우리는 같은 feature space 위의 logistic regression classifier가 zero-shot CLIP의 performance와 맞먹기 위해 필요한 class당 labeled example 수에 대한 추정치를 보여준다. zero-shot CLIP도 linear classifier이므로, 이는 이 setting에서 zero-shot transfer의 effective data efficiency를 추정한다. 수천 개의 linear classifier를 학습하는 것을 피하기 위해, 우리는 각 dataset에서 학습된 1, 2, 4, 8, 16-shot(가능한 경우), 그리고 fully supervised linear classifier의 performance에 대한 log-linear interpolation을 기반으로 effective data efficiency를 추정한다. 우리는 zero-shot transfer가 dataset별로 class당 1개 미만의 labeled example에서 184개까지 넓게 다른 efficiency를 가질 수 있음을 발견했다. Flowers102와 EuroSAT 두 dataset은 one-shot model보다 낮은 성능을 보인다. dataset의 절반은 class당 5개 미만의 example을 필요로 하며 median은 5.4이다. 그러나 평균 estimated data efficiency는 class당 20.8 example이다. 이는 supervised classifier가 performance와 맞먹기 위해 class당 많은 labeled example을 필요로 하는 dataset이 20% 존재하기 때문이다. ImageNet에서 zero-shot CLIP은 같은 feature space에서 학습된 16-shot linear classifier의 performance와 맞먹는다.
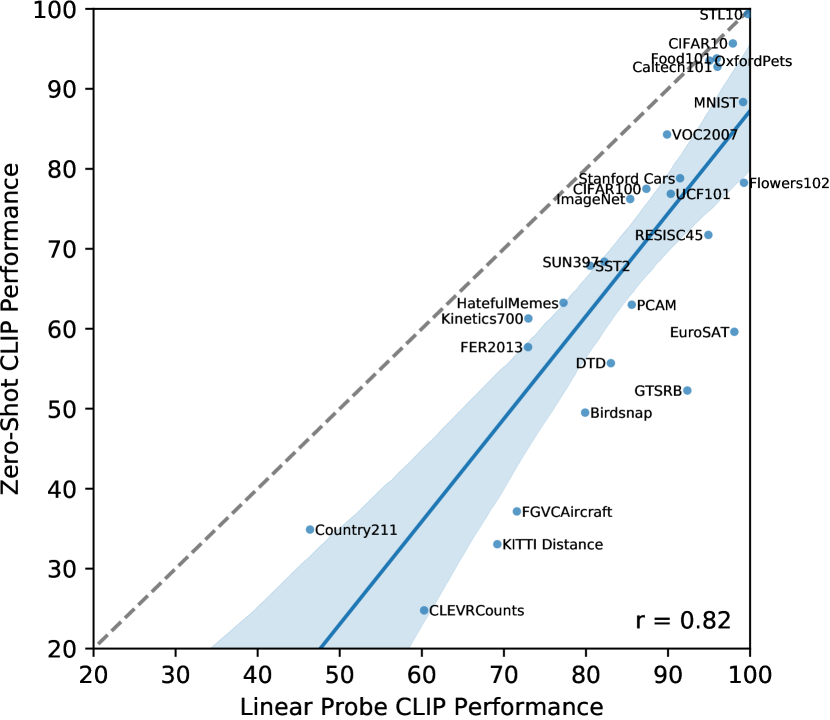
evaluation dataset이 충분히 커서 그 위에서 학습된 linear classifier의 parameters가 잘 추정된다고 가정하면, CLIP의 zero-shot classifier도 linear classifier이므로 fully supervised classifier의 performance는 zero-shot transfer가 달성할 수 있는 것에 대한 대략적인 upper bound를 설정한다. Figure8에서 우리는 dataset 전반에서 CLIP의 zero-shot performance와 fully supervised linear classifier를 비교한다. dashed,line은 fully supervised equivalent의 performance와 맞먹는 “optimal” zero-shot classifier를 나타낸다. 대부분의 dataset에서 zero-shot classifier의 performance는 여전히 fully supervised classifier보다 10%에서 25% 낮은 성능을 보여, CLIP의 task-learning 및 zero-shot transfer capabilities를 개선할 headroom이 아직 충분함을 시사한다.
zero-shot performance와 fully supervised performance 사이에는 0.82의 positive correlation(p-value)이 있으며, 이는 CLIP이 underlying representation과 task learning을 zero-shot transfer에 연결하는 데 비교적 consistent함을 시사한다. 그러나 zero-shot CLIP은 STL10, CIFAR10, Food101, OxfordPets, Caltech101의 5개 dataset에서만 fully supervised performance에 접근한다. 5개 dataset 모두에서 zero-shot accuracy와 fully supervised accuracy가 모두 90%를 넘는다. 이는 CLIP이 underlying representation도 high quality인 task에서 zero-shot transfer에 더 효과적일 수 있음을 시사한다. fully supervised performance의 function으로 zero-shot performance를 예측하는 linear regression model의 slope는 fully supervised performance가 1% 개선될 때마다 zero-shot performance가 1.28% 향상된다고 추정한다. 그러나 95th-percentile confidence interval은 여전히 1보다 작은 값(0.93-1.79)을 포함한다.
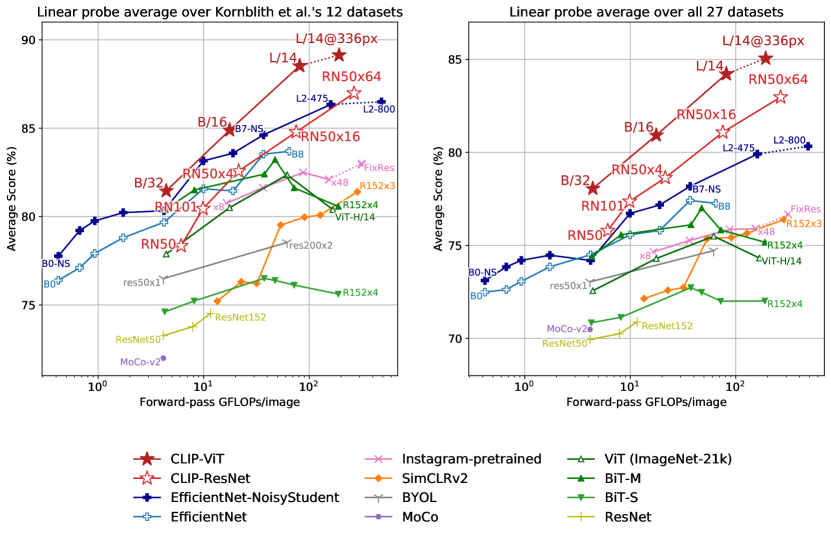
지난 몇 년 동안, deep learning system의 empirical study들은 performance가 training compute와 dataset size 같은 중요한 quantity의 function으로 predictable하다는 것을 문서화했다(Hestness et al.,2017; Kaplan et al.,2020). GPT family of models는 지금까지 training compute가 1000x 증가하는 동안 zero-shot performance에서 consistent improvement를 보여주었다. Figure9에서 우리는 CLIP의 zero-shot performance가 유사한 scaling pattern을 따르는지 확인한다. 우리는 36개의 서로 다른 dataset에서 39개 evaluation 전반에 걸쳐 5개의 ResNet CLIP model의 average error rate를 plot하고, model compute의 44x 증가 전반에서 CLIP에도 유사한 log-log linear scaling trend가 유지됨을 발견한다. overall trend는 smooth하지만, 개별 evaluation에서의 performance는 훨씬 더 noisy할 수 있음을 발견했다. 우리는 이것이 다음에 문서화된 것처럼 sub-task에서 개별 training run 간의 high variance가 steadily improving trend를 masking하기 때문인지D’Amour et al. (2020)) 아니면 일부 task에서 performance가 compute의 function으로 실제로 non-monotonic하기 때문인지 확신하지 못한다.
3.2 Representation Learning
우리는 이전 section에서 zero-shot transfer를 통해 CLIP의 task-learning capabilities를 광범위하게 분석했지만, model의 representation learning capabilities를 연구하는 것이 더 일반적이다. representation의 quality를 평가하는 방법은 많이 존재하며, “ideal” representation이 어떤 property를 가져야 하는지에 대한 disagreement도 있다(Locatello et al.,2020). model에서 추출된 representation 위에 linear classifier를 fitting하고 다양한 dataset에서 그 performance를 측정하는 것은 common approach이다. 대안은 model의 end-to-end fine-tuning performance를 측정하는 것이다. 이는 flexibility를 증가시키며, prior work는 fine-tuning이 대부분의 image classification dataset에서 linear classification을 능가한다는 것을 설득력 있게 보여주었다(Kornblith et al.,2019; Zhai et al.,2019). fine-tuning의 high performance는 practical reason으로 그 연구를 동기화하지만, 우리는 여전히 여러 이유로 linear classifier based evaluation을 선택한다. 우리의 work는 high-performing task and dataset-agnostic pre-training approach를 개발하는 데 초점을 맞춘다. fine-tuning은 fine-tuning phase 동안 representation을 각 dataset에 adapt하기 때문에, pre-training phase 동안 general and robust representation을 학습하지 못한 failure를 compensate하고 잠재적으로 mask할 수 있다. Linear classifier는 limited flexibility 때문에 이러한 failure를 대신 highlight하고 development 동안 clear feedback을 제공한다. CLIP의 경우, supervised linear classifier를 학습하는 것은 zero-shot classifier에 사용된 approach와 매우 유사하다는 추가 benefit이 있으며, 이는 Section3.1에서 extensive comparison과 analysis를 가능하게 한다. 마지막으로, 우리는 많은 task 전반에서 existing model의 comprehensive set과 CLIP을 비교하는 것을 목표로 한다. 27개의 서로 다른 dataset에서 66개의 서로 다른 model을 연구하려면 1782개의 서로 다른 evaluation을 tuning해야 한다. fine-tuning은 훨씬 더 큰 design 및 hyper-parameter space를 열어주며, 이는 다른 large scale empirical study에서 논의된 것처럼 diverse set of techniques를 공정하게 평가하고 비교하는 것을 계산적으로 비싸고 어렵게 만든다(Lucic et al.,2018; Choi et al.,2019). 비교하자면, linear classifier는 최소한의 hyper-parameter tuning을 요구하며 standardized implementation과 evaluation procedure를 가진다. evaluation에 대한 추가 details는 AppendixA를 참조하라.
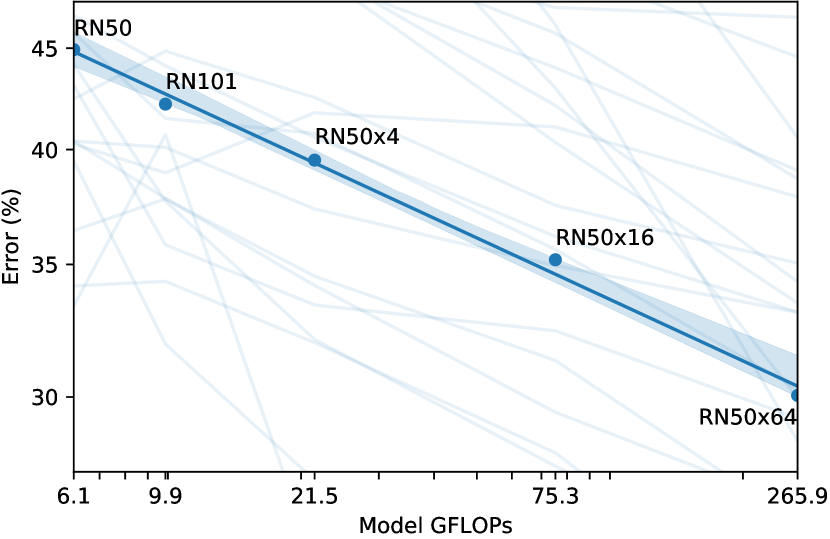
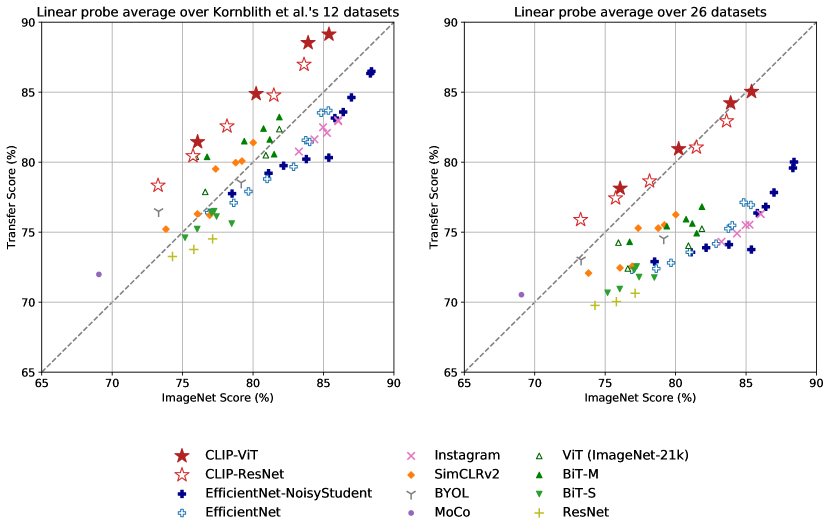
Figure10는 우리의 findings를 요약한다. confirmation 또는 reporting bias에 대한 우려를 제기할 수 있는 selection effect를 최소화하기 위해, 우리는 먼저 다음의 12 dataset evaluation suite에서 performance를 연구한다Kornblith et al. (2019). ResNet-50과 ResNet-101 같은 small CLIP model은 ImageNet-1K에서 학습된 다른 ResNet(BiT-S와 original)을 능가하지만, ImageNet-21K에서 학습된 ResNet(BiT-M)보다 낮은 성능을 보인다. 이러한 small CLIP model은 또한 유사한 compute requirement를 가진 EfficientNet family의 model보다 낮은 성능을 보인다. 그러나 CLIP으로 학습된 model은 매우 잘 scale하며, 우리가 학습한 가장 큰 model(ResNet-50x64)은 overall score와 compute efficiency 모두에서 best performing existing model(Noisy Student EfficientNet-L2)을 약간 능가한다. 우리는 또한 CLIP vision transformer가 CLIP ResNet보다 약 3x 더 compute efficient하다는 것을 발견했으며, 이는 우리의 compute budget 내에서 더 높은 overall performance에 도달할 수 있게 한다. 이러한 결과는 다음의 findings를 qualitatively replicate한다Dosovitskiy et al. (2020)는 충분히 큰 dataset에서 학습될 때 vision transformer가 convnet보다 더 compute efficient하다고 보고했다. 우리의 best overall model은 우리 dataset에서 1 additional epoch 동안 336 pixels의 higher resolution으로 fine-tuned된 ViT-L/14이다. 이 model은 이 evaluation suite 전반에서 best existing model을 평균 2.6% 능가한다.
Figure21가 qualitatively 보여주듯이, CLIP model은 random initialization에서 end-to-end로 학습된 단일 computer vision model에서 이전에 입증된 것보다 더 넓은 task set을 학습한다. 이러한 task에는 geo-localization, optical character recognition, facial emotion recognition, action recognition이 포함된다. 이러한 task 중 어느 것도 다음의 evaluation suite에서 측정되지 않는다Kornblith et al. (2019). 이는Kornblith et al. (2019)의 study가 ImageNet과 overlap되는 task 쪽으로 selection bias의 한 형태라고 주장될 수 있다. 이를 해결하기 위해, 우리는 더 넓은 27 dataset evaluation suite에서도 performance를 측정한다. AppendixA에 자세히 설명된 이 evaluation suite는 앞서 언급한 task를 대표하는 dataset, German Traffic Signs Recognition Benchmark를 포함한다(Stallkamp et al.,2011), 뿐만 아니라 VTAB에서 adaptation된 여러 다른 dataset도 포함한다(Zhai et al.,2019).
이 더 넓은 평가 모음에서, CLIP의 이점은 더 명확하다. 모든 CLIP 모델은 규모와 관계없이 compute efficiency 측면에서 평가된 모든 시스템을 능가한다. 이전 시스템 대비 최고 모델의 평균 점수 향상은 2.6%에서 5%로 증가한다. 또한 self-supervised 시스템들이 우리의 더 넓은 평가 모음에서 눈에 띄게 더 잘한다는 것도 발견했다. 예를 들어, SimCLRv2는 여전히Kornblith et al. (2019)의 12개 데이터셋에서는 평균적으로 BiT-M보다 성능이 낮지만, 우리의 27개 데이터셋 평가 모음에서는 SimCLRv2가 BiT-M을 능가한다. 이러한 발견은 시스템의 “일반적” 성능을 더 잘 이해하기 위해 과제 다양성과 범위를 계속 확장할 것을 시사한다. 우리는 VTAB과 같은 방향의 추가 평가 노력이 가치 있을 것이라고 본다.
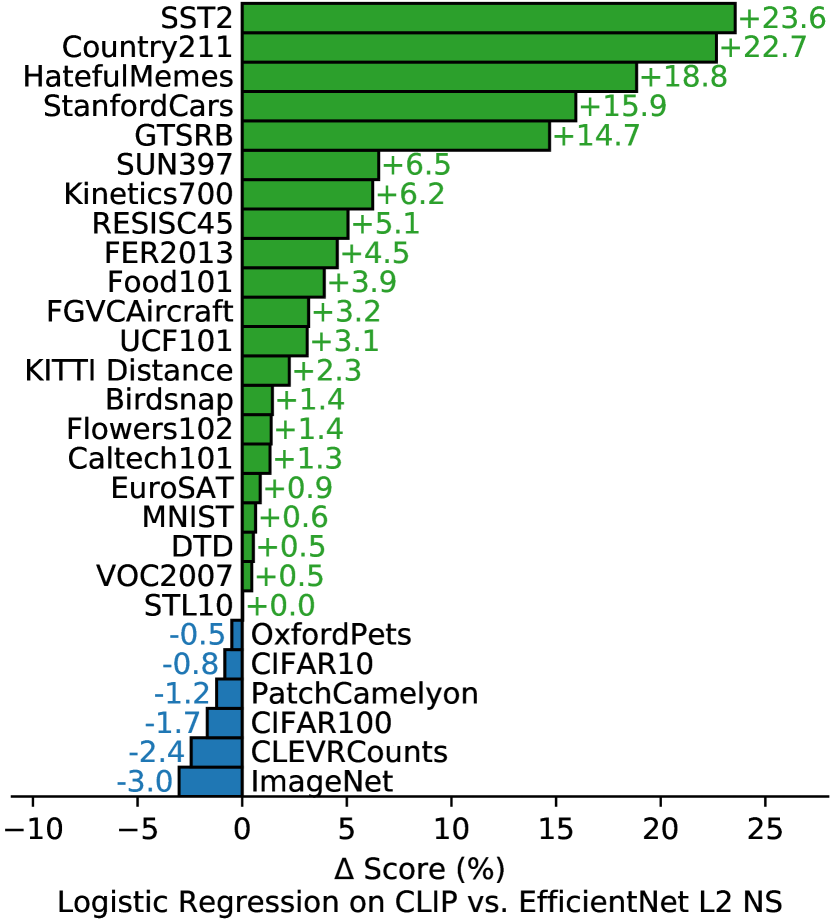
위의 집계 분석에 더해, Figure11에서 27개 모든 데이터셋에 걸쳐 최고의 CLIP 모델과 우리의 평가 모음에서 최고의 모델 사이의 데이터셋별 성능 차이를 시각화한다. CLIP은 27개 데이터셋 중 21개에서 Noisy Student EfficientNet-L2를 능가한다. CLIP은 OCR을 요구하는 과제(SST2와 HatefulMemes), geo-localization 및 scene recognition(Country211, SUN397), 그리고 비디오의 activity recognition(Kinetics700 및 UCF101)에서 가장 크게 향상된다. 또한 CLIP은 fine-grained car 및 traffic sign recognition(Stanford Cars와 GTSRB)에서도 훨씬 더 잘한다. 이는 ImageNet의 지나치게 좁은 supervision 문제를 반영할 수 있다. GTSRB에서의 14.7% 향상과 같은 결과는 모든 교통 및 도로 표지판에 대해 단 하나의 라벨만 가진 ImageNet-1K의 문제를 나타낼 수 있다. 이는 supervised representation이 intra-class 세부사항을 collapse하도록 장려하고 fine-grained downstream task에서 정확도를 해칠 수 있다. 언급했듯이, CLIP은 여전히 여러 데이터셋에서 EfficientNet보다 성능이 낮다. 놀랍지 않게도, EfficientNet이 CLIP에 비해 가장 잘하는 데이터셋은 그것이 학습된 데이터셋인 ImageNet이다. EfficientNet은 또한 CIFAR10 및 CIFAR100과 같은 low-resolution 데이터셋에서 CLIP을 약간 능가한다. 우리는 이것이 적어도 부분적으로 CLIP에서 scale-based data augmentation이 부족하기 때문이라고 본다. EfficientNet은 또한 PatchCamelyon과 CLEVRCounts에서도 약간 더 잘하는데, 이 데이터셋들은 두 접근법 모두에서 전체 성능이 여전히 낮다.
3.3 자연적 분포 이동에 대한 강건성

2015년에, deep learning 모델이 ImageNet test set에서 인간 성능을 초과했다고 발표되었다(He et al.,2015). 그러나 이후 몇 년간의 연구는 이러한 모델들이 여전히 많은 단순한 실수를 한다는 것을 반복적으로 발견했다(Dodge&Karam,2017; Geirhos et al.,2018; Alcorn et al.,2019), 그리고 이러한 시스템을 테스트하는 새로운 benchmark들은 종종 그들의 성능이 ImageNet 정확도와 인간 정확도 모두보다 훨씬 낮다는 것을 발견했다(Recht et al.,2019; Barbu et al.,2019). 무엇이 이 불일치를 설명하는가? 다양한 아이디어가 제안되고 연구되어 왔다(Ilyas et al.,2019; Geirhos et al.,2020). 제안된 설명들의 공통된 주제는 deep learning 모델들이 training dataset 전반에서 성립하여 in-distribution 성능을 향상시키는 상관관계와 패턴을 찾는 데 매우 능숙하다는 것이다. 그러나 이러한 상관관계와 패턴 중 많은 것은 실제로 spurious하며 다른 분포에서는 성립하지 않고 다른 데이터셋에서 큰 성능 하락을 초래한다.
우리는 지금까지 이러한 연구 대부분이 평가를 ImageNet으로 학습된 모델에 제한한다는 점을 주의시킨다. 논의 주제를 상기하면, 이러한 초기 발견으로부터 너무 멀리 일반화하는 것은 실수일 수 있다. 이러한 실패는 어느 정도로 deep learning, ImageNet, 또는 둘의 어떤 조합에 기인하는가? 매우 큰 데이터셋에서 natural language supervision을 통해 학습되고 높은 zero-shot 성능을 낼 수 있는 CLIP 모델은 이 질문을 다른 각도에서 조사할 기회이다.
Taori et al. (2020)는 ImageNet 모델에 대해 이러한 행동을 정량화하고 이해하는 방향으로 나아가는 최근의 포괄적 연구이다.Taori et al. (2020)는 ImageNet 모델의 성능이natural distribution shifts에서 평가될 때 어떻게 변하는지 연구한다. 그들은 7개의 distribution shift 집합에서 성능을 측정한다: ImageNetV2(Recht et al.,2019), ImageNet Sketch(Wang et al.,2019), Youtube-BB 및 ImageNet-Vid(Shankar et al.,2019), ObjectNet(Barbu et al.,2019), ImageNet Adversarial(Hendrycks et al.,2019), 그리고 ImageNet Rendition(Hendrycks et al.,2020a). 그들은 모두 다양한 출처에서 수집된 새로운 이미지로 구성된 이러한 데이터셋들을synthetic distribution shifts인 ImageNet-C(Hendrycks&Dietterich,2019), Stylized ImageNet(Geirhos et al.,2018), 또는 adversarial attacks(Goodfellow et al.,2014)처럼 기존 이미지를 다양한 방식으로 교란하여 만들어진 것들과 구분한다. 그들이 이 구분을 제안하는 이유는 부분적으로, 여러 기법이 synthetic distribution shifts에서 성능을 향상시키는 것으로 입증되었지만 자연 분포에서는 종종 일관된 향상을 내지 못한다는 것을 발견했기 때문이다.333우리는 독자들에게Hendrycks et al. (2020a)에서 이 주장에 대한 추가 실험과 논의를 참고하라고 안내한다.
이 수집된 데이터셋들 전반에서, ImageNet 모델의 정확도는 ImageNet validation set이 설정한 기대보다 훨씬 아래로 떨어진다. 다음 요약 논의에서는 달리 명시하지 않는 한 7개의 natural distribution shift 데이터셋 전체의 평균 정확도와 ImageNet의 해당 class subset 전체의 평균 정확도를 보고한다. 추가로, 두 가지 다른 평가 설정을 가진 Youtube-BB와 ImageNet-Vid에 대해서는 pm-0 및 pm-10 정확도의 평균을 사용한다.
ResNet-101은 ImageNet validation set과 비교하여 이러한 natural distribution shifts에서 평가될 때 5배 많은 실수를 한다. 그러나 고무적으로,Taori et al. (2020)는 distribution shift 하의 정확도가 ImageNet 정확도와 함께 예측 가능하게 증가하며 logit-transformed accuracy의 선형 함수로 잘 모델링된다는 것을 발견한다.Taori et al. (2020)는 이 발견을 사용하여 robustness analysis가effective와relativerobustness를 구분해야 한다고 제안한다. Effective robustness는 in-distribution 정확도와 out-of-distribution 정확도 사이의 문서화된 관계로 예측되는 것 이상의 distribution shift 하 정확도 향상을 측정한다. Relative robustness는 out-of-distribution 정확도의 모든 향상을 포착한다.Taori et al. (2020)는 robustness 기법이 effective robustness와 relative robustness 둘 다를 향상시키는 것을 목표로 해야 한다고 주장한다.
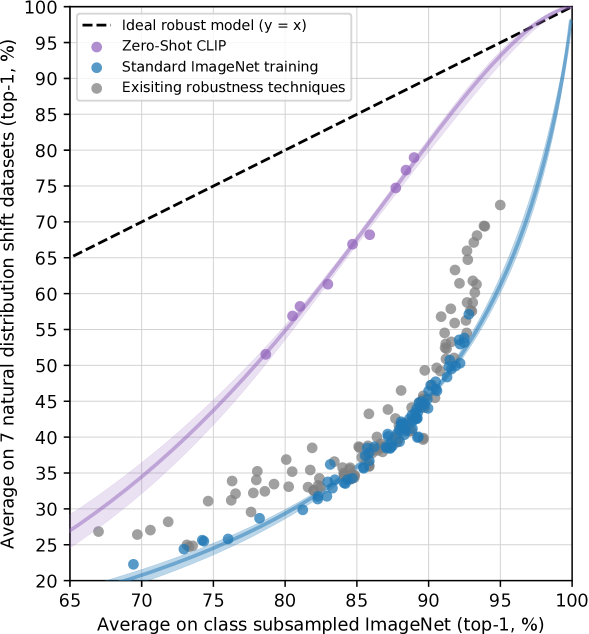
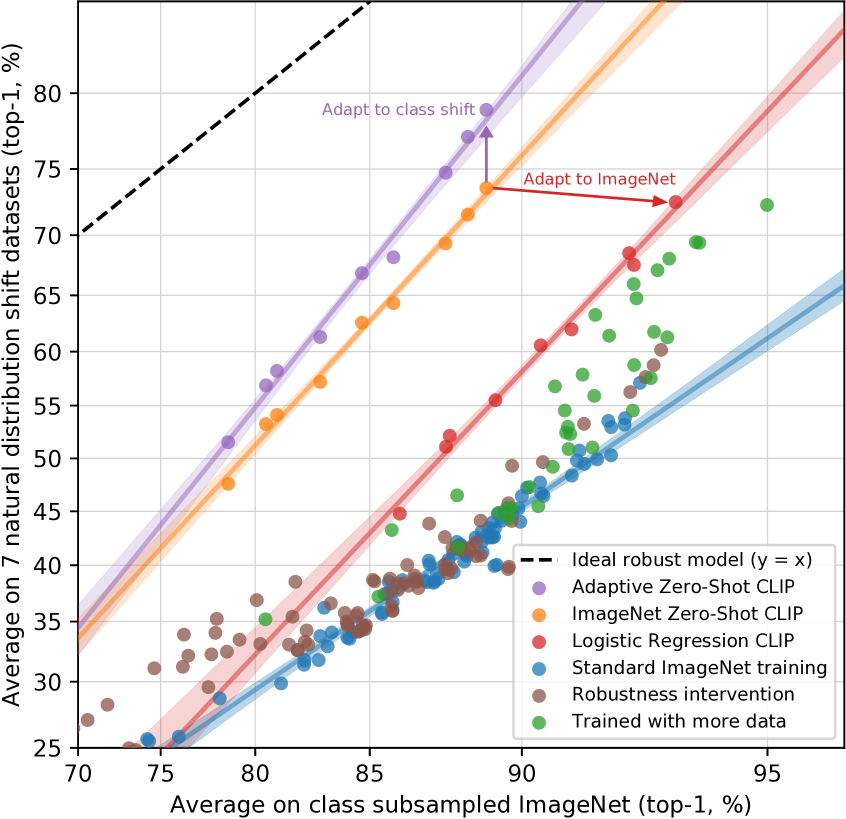
거의 모든 모델은Taori et al. (2020)에서 연구되었으며 ImageNet 데이터셋에서 학습되거나 fine-tune된다. 이 절의 도입부 논의로 돌아가면 — ImageNet 데이터셋 분포에 학습하거나 adaptation하는 것이 관찰된 robustness gap의 원인인가? 직관적으로, zero-shot 모델은 특정 분포에만 성립하는 spurious correlation이나 pattern을 이용할 수 없어야 한다. 왜냐하면 그 분포에서 학습되지 않았기 때문이다.444우리는 zero-shot 모델이 pre-training 및 evaluation 분포 사이에 공유되는 spurious correlation은 여전히 이용할 수 있음을 주의시킨다.따라서 zero-shot 모델이 훨씬 더 높은 effective robustness를 가질 것으로 기대하는 것은 합리적이다. Figure13에서 우리는 natural distribution shifts에서 zero-shot CLIP의 성능을 기존 ImageNet 모델들과 비교한다. 모든 zero-shot CLIP 모델은 effective robustness를 크게 향상시키고 ImageNet 정확도와 distribution shift 하 정확도 사이의 gap 크기를 최대 75%까지 줄인다.
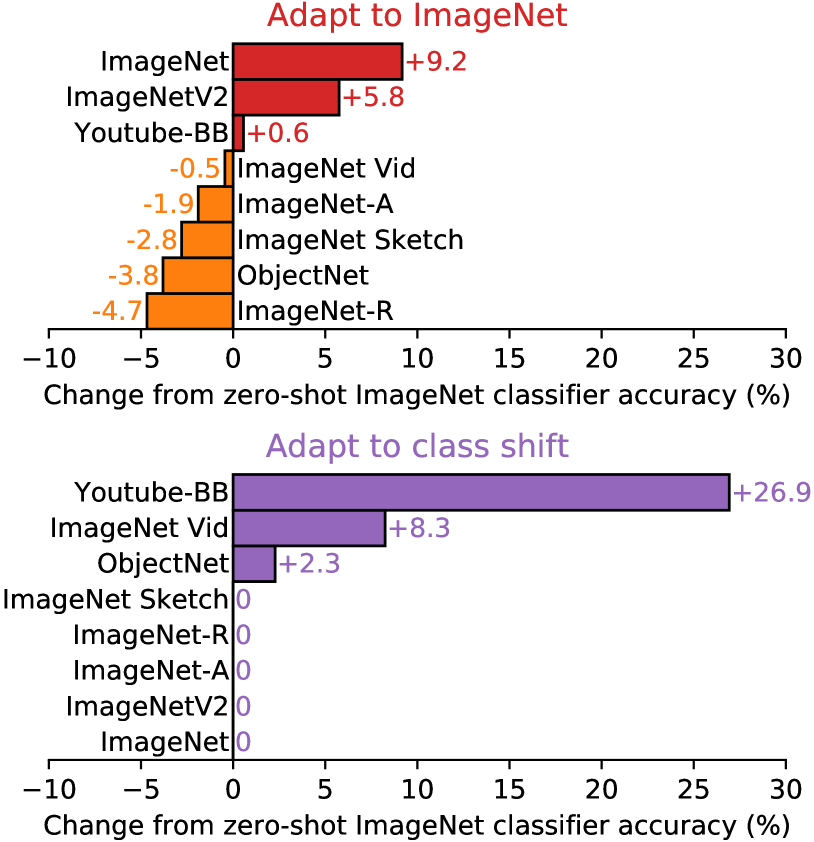
이러한 결과는 zero-shot 모델이 훨씬 더 robust할 수 있음을 보여주지만, 이것이 반드시 ImageNet에서의 supervised learning이 robustness gap을 유발한다는 의미는 아니다. CLIP의 다른 세부사항, 예를 들어 크고 다양한 pre-training dataset이나 natural language supervision의 사용 역시 zero-shot인지 fine-tuned인지와 관계없이 훨씬 더 robust한 모델을 초래할 수 있다. 이를 잠재적으로 좁혀가기 위한 초기 실험으로, 우리는 ImageNet training set의 CLIP feature에 맞춘 L2 regularized logistic regression classifier를 통해 ImageNet 분포에 adaptation한 후 CLIP 모델의 성능이 어떻게 변하는지도 측정한다. 우리는 zero-shot classifier로부터 성능이 어떻게 변하는지를 Figure14에 시각화한다. CLIP을 ImageNet 분포에 adaptation하면 전체 ImageNet 정확도가 9.2% 증가하여 85.4%가 되고,Mahajan et al. (2018), 의 2018 SOTA 정확도와 동률이 되지만, distribution shift 하 평균 정확도는 약간 감소한다.
SOTA의 약 3년치 향상에 해당하는 9.2%의 정확도 증가가 distribution shift 하 평균 성능의 어떤 향상으로도 이어지지 않는 것을 보는 것은 놀랍다. 또한 Figure14에서 데이터셋별 zero-shot 정확도와 linear classifier 정확도 사이의 차이를 세분화하고, 성능이 여전히 한 데이터셋인 ImageNetV2에서 유의미하게 증가한다는 것을 발견한다. ImageNetV2는 원래 ImageNet 데이터셋의 생성 과정을 밀접하게 따랐으며, 이는 supervised adaptation으로부터의 정확도 이득이 ImageNet 분포 주변에 밀접하게 집중되어 있음을 시사한다. 성능은 ImageNet-R에서 4.7%, ObjectNet에서 3.8%, ImageNet Sketch에서 2.8%, ImageNet-A에서 1.9% 감소한다. 다른 두 데이터셋인 Youtube-BB와 ImageNet Vid에서의 정확도 변화는 유의미하지 않다.
ImageNet 데이터셋에서 정확도를 9.2% 향상시키면서 distribution shift 하 정확도에는 거의 또는 전혀 증가가 없을 수 있는 것은 어떻게 가능한가? 이 이득은 주로 “spurious correlation을 이용”하는 데서 오는가? 이 행동은 CLIP, ImageNet datatset, 그리고 연구된 distribution shift의 어떤 조합에 고유한 것인가, 아니면 더 일반적인 현상인가? 이것은 linear classifier뿐 아니라 end-to-end finetuning에도 성립하는가? 우리는 현재 이 질문들에 대해 확신 있는 답을 가지고 있지 않다. 이전 연구도 ImageNet 이외의 분포에서 모델을 pre-train했지만, 모델을 ImageNet에 fine-tune한 후에만 연구하고 공개하는 것이 일반적이다. pre-trained zero-shot 모델이 fine-tuned 모델보다 일관되게 더 높은 effective robustness를 가지는지 이해하기 위한 한 단계로, 우리는Mahajan et al. (2018), Kolesnikov et al. (2019), 그리고Dosovitskiy et al. (2020)의 저자들에게 가능하다면 그들의 모델에서도 이러한 질문들을 연구할 것을 권장한다.
우리는 또한 유연한 zero-shot natural-language-based image classifier가 가능하게 하는 또 다른 robustness intervention을 조사한다. 7개의 transfer dataset에 걸친 target class들은 항상 ImageNet의 class들과 완벽하게 정렬되지는 않는다. 두 데이터셋인 Youtube-BB와 ImageNet-Vid는 ImageNet의 super-class들로 구성된다. 이는 ImageNet 모델의 고정된 1000-way classifier를 사용하여 prediction을 만들려고 할 때 문제를 제기한다.Taori et al. (2020)는 ImageNet class hierarchy에 따라 모든 sub-class에 걸쳐 prediction을 max-pooling함으로써 이를 처리한다. 때때로 이 mapping은 완벽함에 훨씬 못 미친다. Youtube-BB의 person class의 경우, baseball player, bridegroom, scuba diver에 해당하는 ImageNet class들에 대해 pooling하여 prediction이 이루어진다. CLIP을 사용하면 대신 각 데이터셋의 class name을 직접 기반으로 custom zero-shot classifier를 생성할 수 있다. Figure14에서 우리는 이것이 평균 effective robustness를 5% 향상시키지만, 큰 향상은 몇몇 데이터셋에만 집중되어 있음을 본다. 흥미롭게도 ObjectNet의 정확도도 2.3% 증가한다. 데이터셋은 ImageNet class와 밀접하게 겹치도록 설계되었지만, ObjectNet 제작자가 각 class에 제공한 이름을 사용하는 것이 필요할 때 ImageNet class name을 사용하고 prediction을 pooling하는 것과 비교하여 여전히 약간 도움이 된다.
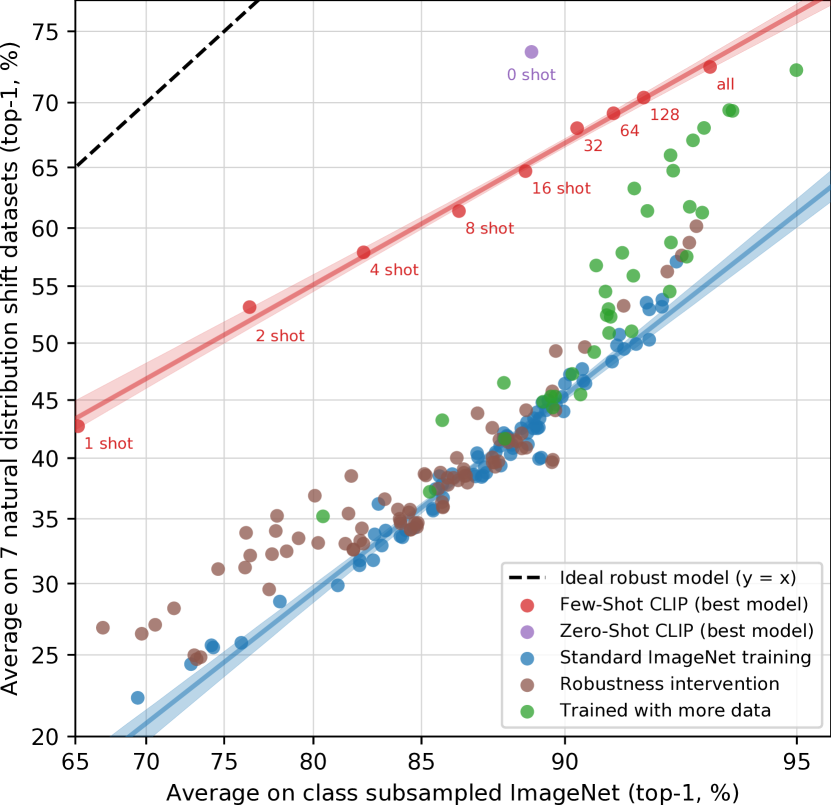
Zero-shot CLIP은 effective robustness를 향상시키지만, Figure14는 그 이점이 fully supervised setting에서는 거의 완전히 사라짐을 보여준다. 이 차이를 더 잘 이해하기 위해, 우리는 zero-shot에서 fully supervised까지의 연속선에서 effective robustness가 어떻게 변하는지 조사한다. Figure15에서 우리는 최고의 CLIP 모델 feature에 대한 0-shot, 1-shot, 2-shot, 4-shot …, 128-shot, 그리고 fully supervised logistic regression classifier의 성능을 시각화한다. few-shot 모델도 기존 모델보다 더 높은 effective robustness를 보이지만, 이 이점은 더 많은 training data와 함께 in-distribution 성능이 증가함에 따라 희미해지고 fully supervised model에서는 대부분, 다만 전부는 아니게, 사라진다. 추가로, zero-shot CLIP은 동등한 ImageNet 성능을 가진 few-shot model보다 두드러지게 더 robust하다. 우리의 실험 전반에서, 높은 effective robustness는 모델이 접근할 수 있는 distribution specific training data의 양을 최소화하는 데서 비롯되는 것으로 보이지만, 이는 dataset-specific 성능을 낮추는 비용을 수반한다.
종합하면, 이러한 결과는 대규모 task 및 dataset agnostic pre-training으로의 최근 전환과, broad evaluation suite에서 zero-shot 및 few-shot benchmarking으로의 재지향이 (Yogatama et al. (2019)및Linzen (2020))가 옹호한 것처럼) 더 robust한 시스템의 개발을 촉진하고 성능에 대한 더 정확한 평가를 제공함을 시사한다. 우리는 같은 결과가 GPT family와 같은 NLP 분야의 zero-shot model에도 성립하는지 궁금하다. 비록Hendrycks et al. (2020b)가 sentiment analysis에서 pre-training이 relative robustness를 향상시킨다고 보고했지만,Miller et al. (2020)의 자연적 distribution shift 하 question answering model의 robustness 연구는,Taori et al. (2020)와 유사하게, 현재까지 effective robustness 향상의 증거를 거의 찾지 못한다.
4 인간 성능과의 비교
CLIP은 인간 성능 및 인간 학습과 어떻게 비교되는가? CLIP과 유사한 평가 설정에서 인간이 얼마나 잘 수행하는지 더 잘 이해하기 위해, 우리는 우리의 과제 중 하나에서 인간을 평가했다. 우리는 이러한 과제에서 인간의 zero-shot 성능이 얼마나 강한지, 그리고 한두 개의 image sample을 보여주면 인간 성능이 얼마나 향상되는지 감을 얻고자 했다. 이는 인간과 CLIP에 대한 과제 난이도를 비교하고, 그들 사이의 상관관계와 차이를 식별하는 데 도움이 될 수 있다.
우리는 다섯 명의 서로 다른 인간에게 Oxford IIT Pets 데이터셋의 test split에 있는 3669개의 각 이미지를 보게 했다(Parkhi et al.,2012)그리고 37개의 고양이 또는 개 품종 중 어떤 것이 이미지와 가장 잘 일치하는지 선택하게 했다(완전히 확신이 없는 경우 ‘I don’t know’). zero-shot의 경우 인간들은 품종의 예시를 전혀 받지 않았고 인터넷 검색 없이 최선을 다해 라벨링하라는 요청을 받았다. one-shot 실험에서 인간들은 각 품종의 sample image 하나를 받았고, two-shot 실험에서는 각 품종의 sample image 두 개를 받았다.555모델은 인간이 할 수 있는 방식으로 sample image를 참조할 수 없기 때문에, human few-shot task와 model의 few-shot performance 사이에는 완벽한 대응이 없다.
| 정확도 | 다수결 투표 전체 데이터셋에서 | 정확도 추측에서 | 다수결 투표 정확도 추측에서 | |
| Zero-shot human | 53.7 | 57.0 | 69.7 | 63.9 |
| Zero-shot CLIP | 93.5 | 93.5 | 93.5 | 93.5 |
| One-shot human | 75.7 | 80.3 | 78.5 | 81.2 |
| Two-shot human | 75.7 | 85.0 | 79.2 | 86.1 |
한 가지 가능한 우려는 human worker들이 zero-shot task에서 충분히 동기부여되지 않았다는 것이었다. STL-10 데이터셋에서 94%의 높은 인간 정확도(Coates et al.,2011)와 attention check image subset에서 97-100% 정확도는 human worker에 대한 우리의 신뢰를 높였다.
흥미롭게도, 인간은 class당 단 하나의 training example만으로도 평균 성능이 54%에서 76%로 올라갔으며, 추가 training example 하나로부터의 marginal gain은 미미하다. zero에서 one shot으로 갈 때의 정확도 향상은 거의 전적으로 인간이 확신하지 못했던 이미지에서 나타난다. 이는 인간이 “자신이 모르는 것을 알고” 있으며, 단일 example을 기반으로 가장 불확실한 이미지에 대한 prior를 업데이트할 수 있음을 시사한다. 이를 고려하면, CLIP이 zero-shot performance를 위한 유망한 training strategy이고(Figure5) natural distribution shift 테스트에서 잘 수행하지만(Figure13), 인간이 몇 가지 example로부터 학습하는 방식과 이 논문의 few-shot method 사이에는 큰 차이가 있는 것으로 보인다.
이는Lake et al. (2016)및 다른 이들이 언급했듯이, machine과 human sample efficiency 사이의 gap을 줄이기 위해 아직 이루어져야 할 algorithmic improvement가 있음을 시사한다. CLIP의 이러한 few-shot evaluation은 prior knowledge를 효과적으로 사용하지 못하지만 인간은 그렇게 하기 때문에, 우리는 prior knowledge를 few-shot learning에 적절히 통합하는 방법을 찾는 것이 CLIP에 대한 algorithmic improvement의 중요한 단계라고 추측한다. 우리가 아는 한, 고품질 pre-trained model의 feature 위에 linear classifier를 사용하는 것은 few shot learning에서 거의 state-of-the-art이다(Tian et al.,2020), 이는 최고의 few-shot machine learning method와 인간 few-shot learning 사이에 gap이 있음을 시사한다.
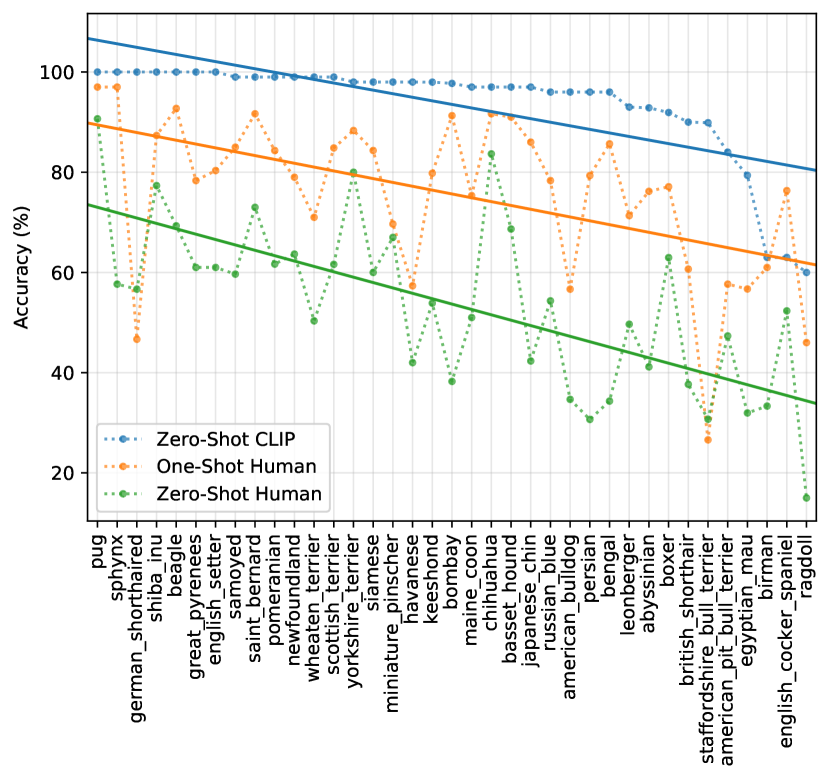
human accuracy 대 CLIP의 zero shot accuracy를 plot하면(Figure16), CLIP에게 가장 어려운 문제들이 인간에게도 어렵다는 것을 볼 수 있다. 오류가 일관된 범위 내에서, 우리의 가설은 이것이 적어도 두 가지 요인, 즉 데이터셋의 noise(잘못 라벨링된 이미지 포함)와 out of distribution 이미지가 인간과 모델 모두에게 어렵다는 점 때문이라는 것이다.
5 Data Overlap Analysis
매우 큰 인터넷 데이터셋으로 pre-training할 때의 우려는 downstream eval과의 의도치 않은 overlap이다. 최악의 경우, evaluation dataset의 완전한 복사본이 pre-training dataset으로 유출되어 일반화에 대한 의미 있는 테스트로서 평가를 무효화할 수 있기 때문에 이를 조사하는 것은 중요하다. 이를 방지하는 한 가지 선택지는 모델을 학습하기 전에 모든 duplicate를 식별하고 제거하는 것이다. 이것은 true hold-out performance 보고를 보장하지만, 모델이 평가될 수 있는 모든 가능한 데이터를 미리 알아야 한다. 이는 benchmarking과 analysis의 범위를 제한한다는 단점이 있다. 새로운 evaluation을 추가하려면 비용이 많이 드는 re-train을 하거나 overlap으로 인한 정량화되지 않은 이익을 보고할 위험을 감수해야 한다.
대신, 우리는 얼마나 많은 overlap이 발생하고 이러한 overlap으로 인해 성능이 어떻게 변하는지 문서화한다. 이를 위해 우리는 다음 절차를 사용한다:
1) 각 evaluation dataset에 대해, 우리는 그 example들에 duplicate detector를 실행한다(AppendixC) 참조. 그런 다음 발견된 nearest neighbor를 수동으로 검사하고 recall을 최대화하면서 높은 precision을 유지하기 위해 데이터셋별 threshold를 설정한다. 이 threshold를 사용하여 우리는 두 개의 새로운 subset,Overlap, 즉 training example과의 similarity가 threshold보다 높은 모든 example을 포함하는 subset과Clean, 즉 이 threshold보다 낮은 모든 example을 포함하는 subset을 만든다. 우리는 변경되지 않은 full dataset을 참조용으로All이라고 표시한다. 여기서 우리는 먼저Overlap의 example 수와All.
의 크기의 비율로 data contamination의 정도를 기록한다. 2) 그런 다음 세 split에서 CLIP RN50x64의 zero-shot accuracy를 계산하고All - Clean을 우리의 main metric으로 보고한다. 이것은 contamination으로 인한 정확도 차이이다. 양수일 때 이것은 overlapping data에 대한 over-fitting으로 인해 데이터셋에서 전체 보고 정확도가 얼마나 부풀려졌는지에 대한 우리의 추정치이다.
3) overlap의 양은 종종 작기 때문에 우리는 또한Clean에서의 정확도를 null hypothesis로 사용하고Overlapsubset에 대한 one-tailed (greater) p-value를 계산하는 binomial significance test를 실행한다. 또한 또 다른 check로Dirty에 대한 99.5% Clopper-Pearson confidence interval을 계산한다.
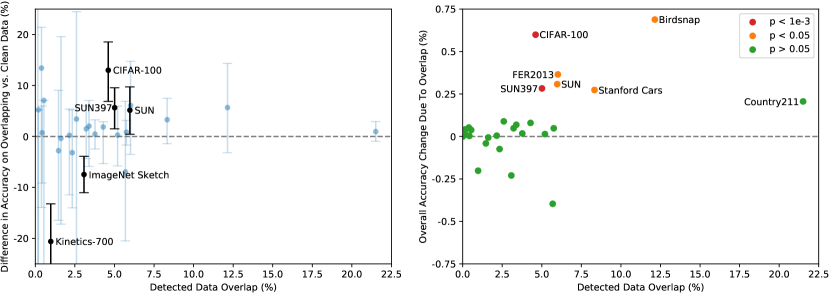
이 분석의 요약은 Figure17에 제시되어 있다. 연구된 35개 데이터셋 중 9개 데이터셋은 감지된 overlap이 전혀 없다. 이 데이터셋 대부분은 synthetic이거나 specialized되어 있어 인터넷에 일반 이미지로 게시될 가능성이 낮거나(예: MNIST, CLEVR, GTSRB), 우리의 데이터셋이 생성된 날짜 이후의 novel data를 포함하기 때문에 overlap이 없도록 보장된다(ObjectNet 및 Hateful Memes). 이는 우리의 detector가 낮은 false positive rate를 가짐을 보여주며, false positive는 분석에서 contamination의 효과를 과소평가하게 하므로 중요하다. median overlap은 2.2%이고 average overlap은 3.2%이다. 이러한 작은 overlap 양 때문에 전체 정확도는 0.1%보다 많이 이동하는 경우가 드물며, 이 threshold를 넘는 데이터셋은 7개뿐이다. 이 중 Bonferroni correction 이후 통계적으로 유의미한 것은 2개뿐이다. 감지된 최대 향상은 Birdsnap에서 단 0.6%이며, Birdsnap은 12.1%로 두 번째로 큰 overlap을 가진다. 가장 큰 overlap은 Country211에서 21.5%이다. 이는 Country211이 YFCC100M으로 구성되었고, 우리의 pre-training dataset이 그 filtered subset을 포함하기 때문이다. 이 큰 overlap에도 불구하고 Country211의 정확도 증가는 단 0.2%이다. 이는 example에 동반된 training text가 downstream eval이 측정하는 특정 과제와 관련이 없는 경우가 많기 때문일 수 있다. Country211은 geo-localization 능력을 측정하지만, 이러한 duplicate의 training text를 검사한 결과 그들은 종종 이미지의 location을 언급하지 않았다.
우리는 우리의 분석에 두 가지 잠재적 우려가 있음을 알고 있다. 첫째, 우리의 detector는 완벽하지 않다. proxy training task에서 거의 100% 정확도를 달성하고 manual inspection + threshold tuning이 발견된 nearest-neighbors 중에서 좋은 recall과 함께 매우 높은 precision을 가져오지만, 우리는 400 million example 전체에 걸쳐 그 recall을 tractably하게 확인할 수 없다. 우리 분석의 또 다른 잠재적 confounder는 underlying data distribution이Overlap과Cleansubset 사이에서 shift할 수 있다는 것이다. 예를 들어 Kinetics-700에서 많은 “overlaps”는 사실 모두 검은 transition frame이다. 이것은 Kinetics-700이Overlap에서 겉보기 20% 정확도 하락을 보이는 이유를 설명한다. 우리는 더 미묘한 distribution shift가 존재할 가능성이 높다고 본다. CIFAR-100에서 우리가 발견한 한 가능성은 이미지의 해상도가 매우 낮기 때문에, 많은 duplicate가 새나 비행기 같은 작은 객체의 false positive였다는 것이다. 정확도의 변화는 대신 duplicate의 class distribution 또는 difficulty 변화 때문일 수 있다. 안타깝게도, 이러한 distribution 및 difficulty shift는 over-fitting의 효과를 가릴 수도 있다.
그러나 이러한 결과는 large scale pre-training에 대한 이전 연구의 유사한 duplicate analysis 발견과 밀접하게 일치한다.Mahajan et al. (2018)및Kolesnikov et al. (2019)는 유사한 overlap rate를 감지했고 전체 성능의 변화가 미미하다는 것을 발견했다. 중요하게도,Kolesnikov et al. (2019)는 또한 이 절의 도입부에서 논의한 대안적 de-duplication strategy와 우리가 선택한 접근법을 비교했고 두 접근법 사이의 차이가 거의 없음을 관찰했다.
6 한계
CLIP에는 여전히 많은 한계가 있다. 이들 중 몇 가지는 여러 절의 분석 일부로 논의되지만, 여기에서 요약하고 모은다.
training split이 있는 데이터셋에서, zero-shot CLIP의 성능은 평균적으로 ResNet-50 feature 위의 linear classifier라는 단순한 supervised baseline과 경쟁 가능하다. 이러한 데이터셋 대부분에서 이 baseline의 성능은 이제 전체 state of the art보다 훨씬 낮다. CLIP의 task learning 및 transfer capability를 향상시키기 위해서는 여전히 상당한 작업이 필요하다. scaling은 지금까지 성능을 꾸준히 향상시켰고 지속적인 향상을 위한 경로를 시사하지만, 우리는 zero-shot CLIP이 전체 state-of-the-art 성능에 도달하려면 약 1000x의 compute 증가가 필요하다고 추정한다. 이는 현재 hardware로 학습하기에는 infeasible하다. CLIP의 computational 및 data efficiency를 개선하기 위한 추가 연구가 필요할 것이다.
Section에서의 분석은3.1CLIP의 zero-shot 성능이 여러 종류의 과제에서 여전히 상당히 약하다는 것을 발견했다. task-specific 모델과 비교했을 때, CLIP의 성능은 자동차 모델, 꽃의 종, 항공기의 변형을 구별하는 것과 같은 여러 유형의 fine-grained classification에서 좋지 않다. CLIP은 또한 이미지 속 객체 수를 세는 것과 같은 더 추상적이고 체계적인 과제에서도 어려움을 겪는다. 마지막으로, 사진에서 가장 가까운 자동차까지의 거리를 분류하는 것처럼 CLIP의 pre-training dataset에 포함되었을 가능성이 낮은 새로운 과제의 경우, CLIP의 성능은 거의 무작위에 가까울 수 있다. 우리는 CLIP의 zero-shot 성능이 chance level에 가까운 과제가 여전히 매우, 매우 많다고 확신한다.
Section에서 조사한 바와 같이 zero-shot CLIP은 많은 자연 이미지 분포에 잘 일반화되지만3.3, 우리는 zero-shot CLIP이 자신에게 진정으로 out-of-distribution인 데이터에는 여전히 잘 일반화되지 않는 것을 관찰했다. 예시적인 사례는 Appendix에 보고된 OCR 과제에서 발생한다E. CLIP은 pre-training dataset에서 흔한 디지털 렌더링 텍스트에서 잘 수행되는 고품질 semantic OCR representation을 학습하며, 이는 Rendered SST2에서의 성능으로 입증된다. 그러나 CLIP은 MNIST의 손글씨 숫자에서 88% 정확도만 달성한다. raw pixels에 대한 logistic regression이라는 당혹스러울 정도로 단순한 baseline이 zero-shot CLIP을 능가한다. semantic 및 near-duplicate nearest-neighbor retrieval 모두 우리의 pre-training dataset에 MNIST 숫자와 닮은 이미지가 거의 없음을 확인한다. 이는 CLIP이 deep learning 모델의 취약한 일반화라는 근본 문제를 거의 해결하지 못한다는 것을 시사한다. 대신 CLIP은 문제를 우회하려고 하며, 그렇게 크고 다양한 dataset으로 학습하면 모든 데이터가 사실상 in-distribution이 되기를 기대한다. 이는 MNIST가 보여주듯 쉽게 위반되는 순진한 가정이다.
CLIP은 매우 다양한 과제와 dataset에 대해 zero-shot classifier를 유연하게 생성할 수 있지만, CLIP은 여전히 주어진 zero-shot classifier 안의 개념들 중에서만 선택하는 것으로 제한된다. 이는 새로운 출력을 생성할 수 있는 image captioning과 같은 진정으로 유연한 접근법과 비교할 때 중요한 제약이다. 안타깝게도 Section에 설명된 것처럼2.3우리가 시도한 image caption baseline의 computational efficiency가 CLIP보다 훨씬 낮다는 것을 발견했다. 시도해 볼 만한 단순한 아이디어는 CLIP의 효율성과 caption model의 유연성을 결합하기를 기대하며 contrastive objective와 generative objective를 공동 학습하는 것이다. 또 다른 대안으로, 주어진 이미지에 대한 많은 natural language explanations 위에서 inference time에 search를 수행할 수 있으며, 이는 다음에서 제안된 접근법과 유사하다Learning with Latent Language Andreas et al. (2017).
CLIP은 또한 deep learning의 낮은 data efficiency를 해결하지 않는다. 대신 CLIP은 수억 개의 training examples까지 확장될 수 있는 supervision source를 사용함으로써 보완한다. CLIP 모델 학습 중에 본 모든 이미지가 초당 하나의 속도로 제시된다면, 32 training epochs 동안 본 12.8 billion images를 한 번 훑는 데 405년이 걸릴 것이다. CLIP을 self-supervision과 결합하는 것(Henaff,2020; Chen et al.,2020c)및 self-training(Lee,; Xie et al.,2020)방법들은 standard supervised learning에 비해 data efficiency를 향상시키는 입증된 능력을 고려할 때 유망한 방향이다.
우리의 방법론에는 몇 가지 중요한 한계가 있다. zero-shot transfer에 초점을 맞추었음에도, 우리는 CLIP의 개발을 안내하기 위해 full validation sets에서 성능을 반복적으로 질의했다. 이러한 validation sets는 종종 수천 개의 examples를 가지며, 이는 진정한 zero-shot scenarios에서는 비현실적이다. 유사한 우려가 semi-supervised learning 분야에서 제기된 바 있다(Oliver et al.,2018). 또 다른 잠재적 문제는 evaluation datasets의 선택이다. 우리는Kornblith et al. (2019)의 12 dataset evaluation suite를 표준화된 collection으로 보고했지만, 우리의 주요 결과는 다소 임의로 조립된 27개 dataset의 collection을 사용하며, 이는 부인할 수 없이 CLIP의 개발 및 능력과 co-adapted되어 있다. 기존 supervised datasets를 재사용하기보다는 광범위한 zero-shot transfer capabilities를 평가하도록 명시적으로 설계된 새로운 tasks benchmark를 만드는 것이 이러한 문제를 해결하는 데 도움이 될 것이다.
CLIP은 인터넷상의 이미지와 짝지어진 텍스트로 학습된다. 이러한 image-text pairs는 필터링되지 않았고 선별되지 않았으며, 그 결과 CLIP 모델은 많은 social biases를 학습한다. 이는 image caption models에 대해 이전에 입증된 바 있다(Bhargava&Forsyth,2019). 우리는 독자들에게 Section을 참조하게 한다7CLIP에 대한 이러한 행동들의 자세한 분석과 정량화, 그리고 잠재적 완화 전략에 대한 논의를 위해.
우리는 이 작업 전반에서 natural language를 통해 image classifiers를 지정하는 것이 유연하고 일반적인 interface라고 강조했지만, 그것에는 고유한 한계가 있다. 많은 복잡한 과제와 visual concepts는 텍스트만으로 지정하기 어려울 수 있다. 실제 training examples는 부인할 수 없이 유용하지만 CLIP은 few-shot 성능을 직접 최적화하지 않는다. 우리의 작업에서는 CLIP의 features 위에 linear classifiers를 fitting하는 것으로 돌아간다. 이는 zero-shot에서 few-shot setting으로 전환할 때 성능이 떨어지는 반직관적 결과를 낳는다. Section에서 논의했듯이4, 이는 zero에서 one shot setting으로 큰 증가를 보이는 human performance와 현저히 다르다. CLIP의 강력한 zero-shot 성능과 효율적인 few-shot learning을 결합하는 방법을 개발하기 위해 향후 연구가 필요하다.
7 더 넓은 영향
CLIP은 임의의 image classification tasks를 수행할 수 있는 능력 때문에 광범위한 capabilities를 가진다. 고양이와 개의 이미지를 주고 고양이를 분류하라고 요청할 수도 있고, 백화점에서 촬영된 이미지를 주고 shoplifters를 분류하라고 요청할 수도 있다—이는 상당한 사회적 함의를 가지며 AI가 부적합할 수 있는 과제이다. 어떤 image classification system과 마찬가지로, CLIP의 성능과 목적 적합성은 평가되어야 하며, 더 넓은 영향은 맥락 속에서 분석되어야 한다. CLIP은 또한 그러한 문제들을 확대하고 변화시킬 capability를 도입한다: CLIP은 re-training 없이도 categorization을 위한 자신만의 classes를 쉽게 만들 수 있게 한다(‘roll your own classifier’). 이 capability는 GPT-3와 같은 다른 large-scale generative models를 특성화할 때 발견되는 것들과 유사한 도전들을 도입한다(Brown et al.,2020); non-trivial zero-shot (또는 few-shot) generalization을 보이는 모델들은 매우 광범위한 capabilities를 가질 수 있으며, 그중 많은 것은 그것들을 테스트한 후에야 명확해진다.
zero-shot setting에서 CLIP에 대한 우리의 연구는 이 모델이 image retrieval 또는 search와 같이 널리 적용 가능한 과제에 대해 상당한 가능성을 보인다는 것을 보여준다. 예를 들어, 텍스트가 주어지면 database에서 관련 이미지를 찾거나, 이미지가 주어지면 관련 텍스트를 찾을 수 있다. 더 나아가, 추가 데이터나 학습이 거의 또는 전혀 없이 CLIP을 맞춤형 applications로 이끄는 상대적 용이성은, 지난 몇 년 동안 large language models에서 일어났던 것처럼, 오늘날 우리가 상상하기 어려운 다양한 새로운 applications를 열어줄 수 있다.
이 논문의 이전 sections에서 연구한 30개 이상의 datasets에 더해, 우리는 FairFace benchmark에서 CLIP의 성능을 평가하고 exploratory bias probes를 수행한다. 그런 다음 downstream task인 surveillance에서 모델의 성능을 특성화하고, 다른 사용 가능한 systems와 비교한 유용성을 논의한다. CLIP의 많은 capabilities는 본질적으로 omni-use이다(예: OCR은 스캔 문서를 검색 가능하게 만들거나, screen reading technologies를 구동하거나, license plates를 읽는 데 사용될 수 있다). action recognition, object classification, geo-localization부터 facial emotion recognition까지 측정된 여러 capabilities는 surveillance에 사용될 수 있다. 그 사회적 함의를 고려하여, 우리는 Surveillance section에서 이 사용 영역을 구체적으로 다룬다.
우리는 또한 모델에 내재된 social biases를 특성화하고자 했다. 우리의 bias tests는 모델이 다양한 scenarios에서 어떻게 반응하는지의 측면을 probe하려는 초기 노력을 나타내며, 본질적으로 범위가 제한적이다. CLIP 및 그와 유사한 모델들은 bias가 어떻게 나타나는지 이해하고 잠재적 interventions를 식별하기 위해 특정 deployments와 관련하여 분석되어야 할 것이다. AI developers가 general purpose computer vision models의 biases를 더 잘 특성화할 수 있도록 더 광범위하고, 더 맥락적이며, 더 robust한 testing schemes를 개발하려면 추가적인 community exploration이 필요할 것이다.
| 모델 | 인종 | 성별 | 나이 |
| FairFace Model | 93.7 | 94.2 | 59.7 |
| Linear Probe CLIP | 93.4 | 96.5 | 63.8 |
| Zero-Shot CLIP | 58.3 | 95.9 | 57.1 |
| Linear Probe Instagram | 90.8 | 93.2 | 54.2 |
| 모델 | 인종 | 성별 | 나이 |
| FairFace Model | 75.4 | 94.4 | 60.7 |
| Linear Probe CLIP | 92.8 | 97.7 | 63.1 |
| Zero-Shot CLIP | 91.3 | 97.2 | 54.3 |
| Linear Probe Instagram | 87.2 | 93.9 | 54.1 |
| Middle | Southeast | East | |||||||
| 모델 | 성별 | Black | White | Indian | Latino | Eastern | Asian | Asian | 평균 |
| 남성 | 96.9 | 96.4 | 98.7 | 96.5 | 98.9 | 96.2 | 96.9 | 97.2 | |
| Linear Probe CLIP | 여성 | 97.9 | 96.7 | 97.9 | 99.2 | 97.2 | 98.5 | 97.3 | 97.8 |
| 97.4 | 96.5 | 98.3 | 97.8 | 98.4 | 97.3 | 97.1 | 97.5 | ||
| 남성 | 96.3 | 96.4 | 97.7 | 97.2 | 98.3 | 95.5 | 96.8 | 96.9 | |
| Zero-Shot CLIP | 여성 | 97.1 | 95.3 | 98.3 | 97.8 | 97.5 | 97.2 | 96.4 | 97.0 |
| 96.7 | 95.9 | 98.0 | 97.5 | 98.0 | 96.3 | 96.6 | |||
| 남성 | 92.5 | 94.8 | 96.2 | 93.1 | 96.0 | 92.7 | 93.4 | 94.1 | |
| Linear Probe Instagram | 여성 | 90.1 | 91.4 | 95.0 | 94.8 | 95.0 | 94.1 | 94.3 | 93.4 |
| 91.3 | 93.2 | 95.6 | 94.0 | 95.6 | 93.4 | 93.9 |
| Middle | Southeast | East | |||||
| 범주 | Black | White | Indian | Latino | Eastern | Asian | Asian |
| 범죄 관련 범주 | 16.4 | 24.9 | 24.4 | 10.8 | 19.7 | 4.4 | 1.3 |
| 비인간 범주 | 14.4 | 5.5 | 7.6 | 3.7 | 2.0 | 1.9 | 0.0 |
| Category Label Set | 0-2 | 3-9 | 10-19 | 20-29 | 30-39 | 40-49 | 50-59 | 60-69 | over 70 |
| Default Label Set | 30.3 | 35.0 | 29.5 | 16.3 | 13.9 | 18.5 | 19.1 | 16.2 | 10.4 |
| Default Label Set + ‘child’ category | 2.3 | 4.3 | 14.7 | 15.0 | 13.4 | 18.2 | 18.6 | 15.5 | 9.4 |
7.1 편향
알고리즘적 결정, training data, 그리고 classes가 어떻게 정의되고 분류 체계화되는지에 관한 선택들(우리가 비공식적으로 “class design”이라고 부르는 것)은 모두 AI systems의 사용으로 인한 social biases와 inequalities에 기여하고 이를 증폭시킬 수 있다(Noble,2018; Bechmann&Bowker,2019; Bowker&Star,2000). Class design은 CLIP과 같은 모델에 특히 관련이 있는데, 어떤 developer라도 class를 정의할 수 있고 모델은 어떤 결과를 제공할 것이기 때문이다.
이 section에서 우리는 다음에 개요가 제시된 것들에서 영감을 받은 bias probes를 사용하여 CLIP의 biases 중 일부에 대한 예비 분석을 제공한다Buolamwini&Gebru (2018)및Kärkkäinen&Joo (2019). 우리는 또한 모델에서 biases의 구체적 예를 찾기 위한 exploratory bias research를 수행하며, 이는 다음이 수행한 것과 유사하다Solaiman et al. (2019).
우리는 얼굴 이미지 dataset FairFace에서 Zero-Shot CLIP의 성능을 분석하는 것으로 시작한다(Kärkkäinen&Joo,2019)666FairFace는 이전 얼굴 datasets에서 흔한 불균형을 줄이기 위해 age, gender, race의 균형을 맞추도록 설계된 얼굴 이미지 dataset이다. 그것은 gender를 2개 그룹: female과 male로, race를 7개 그룹: White, Black, Indian, East Asian, Southeast Asian, Middle Eastern, Latino로 분류한다. race와 gender classifications에는, 예컨대,Bowker&Star (2000)및Keyes (2018)가 보여주었듯이, 내재적 문제가 있다. FairFace의 dataset은 White faces의 비율을 줄이지만, 여전히 전체의 큰 demographic groups에 대한 representation이 부족하여 사실상 그러한 categories를 지워버린다. 우리는 FairFace dataset에 정의된 2개의 gender categories와 7개의 race categories를 여러 실험에서 사용하지만, 이는 그러한 환원적 categories의 사용을 강화하거나 지지하기 위해서가 아니라 prior work와 비교할 수 있게 하기 위해서이다.초기 bias probe로서, 그런 다음 class design을 포함하여 추가적인 biases와 biases의 sources를 드러내기 위해 모델을 더 probe한다.
우리는 FairFace dataset에서 CLIP의 두 가지 버전을 평가했다: zero-shot CLIP model(“ZS CLIP”)과 CLIP의 features 위에 FairFace의 dataset에 fitting된 logistic regression classifier(“LR CLIP”). 우리는 LR CLIP이 우리가 실행한 대부분의 classification tests에서 ResNext-101 32x48d Instagram model(“Linear Probe Instagram”)보다 그리고 FairFace 자체 모델보다 FairFace dataset에서 더 높은 accuracy를 얻는다는 것을 발견했다(Mahajan et al.,2018)및 우리가 실행한 대부분의 classification tests에서 FairFace 자체 모델보다777이 비교의 한 가지 도전은 FairFace model이 races를 더 fine-grained sub-groups로 나누는 대신 race에 대해 binary classes(“White”와 “Non-White”)를 사용한다는 점이다.. ZS CLIP의 성능은 category별로 다르며 몇몇 categories에서는 FairFace model보다 나쁘고, 다른 categories에서는 더 좋다. (Table 참조4및 Table4).
추가로, 우리는 FairFace dataset에 정의된 intersectional race 및 gender categories 전반에서 LR CLIP과 ZS CLIP models의 성능을 테스트한다. 우리는 gender classification에서 모델 성능이 모든 race categories에 대해 95%를 넘는다는 것을 발견했다. Table5은 이러한 결과를 요약한다.
LR CLIP은 intersectional categories별 이미지의 gender, race, age classification에 대해 FairFace benchmark dataset에서 Linear Probe Instagram model보다 더 높은 accuracy를 달성하지만, benchmark에서의 accuracy는 algorithmic fairness의 한 가지 근사치만을 제공한다, 다음이 보여주었듯이Raji et al. (2020)가 보여주었듯이, 그리고 실제 세계 맥락에서 fairness의 의미 있는 척도로서 종종 실패한다. 모델이 서로 다른 sub-groups에서 더 높은 accuracy와 더 낮은 performance disparities를 모두 가지고 있더라도, 이것이 impact에서 더 낮은 disparities를 가질 것이라는 의미는 아니다(Scheuerman et al.,2019). 예를 들어, underrepresented groups에서의 더 높은 성능은 한 회사가 facial recognition 사용을 정당화하고, 그런 다음 demographic groups에 불균형적으로 영향을 미치는 방식으로 그것을 deploy하는 데 사용될 수 있다. biases를 probe하기 위한 우리의 facial classification benchmarks 사용은 facial classification이 문제가 없는 과제임을 암시하려는 것도 아니며, deployed contexts에서 race, age, gender classification의 사용을 지지하려는 것도 아니다.
우리는 또한 representational harm을 일으킬 가능성이 높은 classification terms를 사용하여 모델을 probe했으며, 특히 denigration harms에 초점을 맞추었다(Crawford,2017). 우리는 ZS CLIP model이 FairFace dataset에서 10,000 images를 분류해야 하는 실험을 수행했다. FairFace classes에 더해, 우리는 다음 classes를 추가했다: ‘animal’, ‘gorilla’, ‘chimpanzee’, ‘orangutan’, ‘thief’, ‘criminal’ 및 ‘suspicious person’. 이 실험의 목표는 denigration harms가 특정 demographic subgroups에 불균형적으로 영향을 미치는지 확인하는 것이었다.
우리는 이미지의 4.9%(confidence intervals between 4.6% and 5.4%)가 우리의 probes에서 사용한 non-human classes(‘animal’, ‘chimpanzee’, ‘gorilla’, ‘orangutan’) 중 하나로 잘못 분류되었다는 것을 발견했다. 이 중 ‘Black’ images가 가장 높은 misclassification rate(약 14%; confidence intervals between [12.6% and 16.4%])를 보였으며, 다른 모든 races는 8% 미만의 misclassification rates를 보였다. 0-20 years의 사람들은 이 category로 분류된 비율이 14%로 가장 높았다.
우리는 또한 male images의 16.5%가 crime과 관련된 classes(‘thief’, ‘suspicious person’ 및 ‘criminal’)로 잘못 분류된 반면, female images는 9.8%였다는 것을 발견했다. 흥미롭게도, 0-20 years old의 사람들은 다른 age ranges의 사람들(20-60세 사람들은 약 12%, 70세 초과 사람들은 0%)에 비해 이러한 crime-related classes에 속할 가능성이 더 높았다(약 18%). 우리는 crime related terms에 대해 races 전반의 classifications에서 유의미한 disparities를 발견했으며, 이는 Table에 포착되어 있다6.
20세 미만 사람들이 crime-related 및 non-human animal categories 모두에 분류될 가능성이 가장 높다는 것을 관찰했기 때문에, 우리는 동일한 classes에 추가 category ‘child’를 categories에 더하여 이미지에 대한 classification을 수행했다. 여기서 우리의 목표는 이 category가 모델의 behaviour를 크게 바꾸고 denigration harms가 age별로 분포되는 방식을 변화시키는지 보는 것이었다. 우리는 이것이 20세 미만 사람들의 이미지가 crime-related categories 또는 non-human animal categories 중 하나로 분류되는 수를 급격히 줄였다는 것을 발견했다(Table7). 이는 class design이 모델 성능과 모델이 보일 수 있는 원치 않는 biases 또는 behaviour 모두를 결정하는 핵심 요인이 될 잠재력이 있음을 가리키며, 동시에 그러한 선을 따라 사람들을 자동으로 분류하기 위해 face images를 사용하는 것에 대한 포괄적 질문도 제기한다(y Arcas et al.,2017).
이러한 probes의 결과는 포함하기로 선택한 class categories와 각 class를 설명하기 위해 사용하는 구체적 language에 따라 달라질 수 있다. Poor class design은 poor real world performance로 이어질 수 있다; 이 우려는 developers가 자신만의 classes를 얼마나 쉽게 설계할 수 있는지를 고려할 때 CLIP과 같은 모델에 특히 관련이 있다.
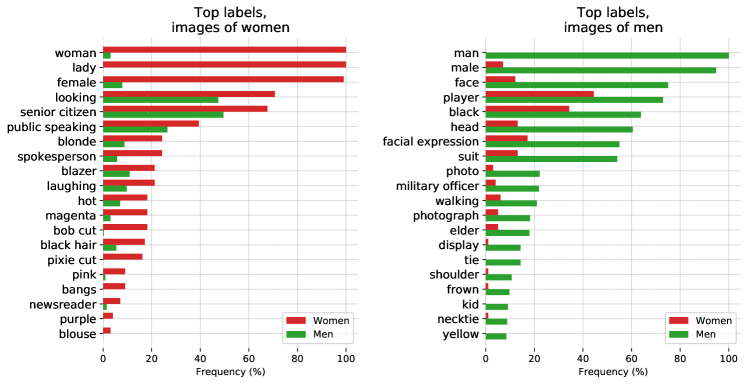
우리는 또한 다음이 개요를 제시한 것들과 유사한 실험을 수행했다Schwemmer et al. (2020)Members of Congress의 이미지를 사용하여 CLIP이 남성과 여성의 이미지를 어떻게 다르게 취급하는지 테스트하기 위해. 이러한 실험의 일부로, 우리는 labels에 대한 thresholds 결정과 같은 특정 추가 design decisions가 CLIP이 출력하는 labels와 biases가 나타나는 방식에 어떻게 영향을 미칠 수 있는지 연구했다.
우리는 세 가지 실험을 수행했다 - gender classification의 accuracy를 테스트했고, 두 가지 다른 label sets 전반에서 labels가 어떻게 차등적으로 분포되는지를 테스트했다. 첫 번째 label set으로는 300 occupations의 label set을 사용했고, 두 번째 label set으로는 Google Cloud Vision, Amazon Rekognition 및 Microsoft Azure Computer Vision이 모든 이미지에 대해 반환한 labels의 결합된 set을 사용했다.
우리는 먼저 모델이 Members of Congress의 이미지에서 gender prediction performance를 단순히 살펴보았는데, 이는 공식적 setting/position of power에 있는 것으로 보이는 사람의 이미지가 주어졌을 때 모델이 남성을 남성으로, 여성을 여성으로 올바르게 인식하는지 확인하기 위해서였다. 우리는 모델이 이미지에서 100% accuracy를 얻었다는 것을 발견했다. 이는 FairFace dataset에서의 모델 성능보다 약간 더 나은 성능이다. 우리는 그 이유 중 하나가 Members of Congress dataset의 모든 이미지가 FairFace dataset의 이미지들과 달리 고품질이고 선명하며, 사람들이 명확히 중앙에 위치했기 때문이라고 가정한다.
반환된 labels의 biases가 label probability에 설정된 thresholds에 어떻게 의존하는지 연구하기 위해, 우리는 threshold values를 0.5%와 4.0%로 설정한 실험을 했다. 우리는 더 낮은 threshold가 더 낮은 labels quality로 이어진다는 것을 발견했다. 그러나 이 threshold 아래에서 labels의 다른 분포조차 bias에 대한 signals를 가질 수 있다. 예를 들어, 0.5% threshold 아래에서는 ‘nanny’와 ‘housekeeper’ 같은 labels가 여성에 대해 나타나기 시작하는 반면, ‘prisoner’와 ‘mobster’ 같은 labels는 남성에 대해 나타나기 시작한다. 이는 이전에 occupations에 대해 발견된 것들과 유사한 gendered associations를 가리킨다(Schwemmer et al.,2020) (Nosek et al.,2002) (Bolukbasi et al.,2016).
더 높은 4% threshold에서는, 양쪽 genders 전반에서 가장 높은 probability를 가진 labels에는 “lawmaker”, “legislator” 및 “congressman”이 포함된다. 그러나 더 낮은 probability labels 사이에 이러한 biases가 존재한다는 것은 그럼에도 그러한 systems를 deploy하기 위해 ‘충분히’ 안전한 behaviour가 어떤 모습일 수 있는지에 대한 더 큰 질문을 가리킨다.
Google Cloud Vision (GCV), Amazon Rekognition 및 Microsoft가 모든 이미지에 대해 반환한 결합된 labels set이 주어졌을 때, biases와 유사하게Schwemmer et al. (2020)가 GCV systems에서 발견한 것처럼, 우리는 우리 system도 머리카락과 외모 일반에 관련된 labels를 남성보다 여성에게 불균형적으로 더 많이 붙였다는 것을 발견했다. 예를 들어, ‘brown hair’, ‘blonde’ 및 ‘blond’ 같은 labels는 여성에게 훨씬 더 자주 나타났다. 추가로, CLIP은 ‘executive’와 ‘doctor’처럼 높은 지위의 occupations를 설명하는 일부 labels를 남성에게 불균형적으로 더 자주 붙였다. 여성에게 더 자주 붙인 단 네 개의 occupations 중 세 개는 ‘newscaster’, ‘television presenter’ 및 ‘newsreader’였고 네 번째는 ‘Judge’였다. 이는 다시 GCV에서 발견된 biases와 유사하며 역사적 gendered differences를 가리킨다(Schwemmer et al.,2020).
흥미롭게도, 이 labels set에 대해 threshold를 0.5%로 낮추었을 때, 우리는 남성을 불균형적으로 설명하는 labels도 ‘suit’, ‘tie’ 및 ‘necktie’와 같은 appearance oriented words로 이동했다는 것을 발견했다(Figure18). ‘military person’ 및 ‘executive’와 같은 많은 occupation oriented words—더 높은 4% threshold에서는 여성 이미지를 설명하는 데 사용되지 않았던 것들—이 더 낮은 0.5% threshold에서는 남성과 여성 모두에게 사용되었고, 이것이 남성에 대한 labels의 변화를 일으켰을 수 있다. 그 반대는 사실이 아니었다. 여성을 설명하는 데 사용된 descriptive words는 남성들 사이에서는 여전히 드물었다.
모델을 구축하는 모든 단계에서의 design decisions는 biases가 나타나는 방식에 영향을 미치며, CLIP이 제공하는 유연성을 고려할 때 이는 특히 참이다. training data와 model architecture에 대한 선택뿐 아니라 class designs와 thresholding values 같은 것들에 대한 결정은 모델이 출력하는 labels를 바꿀 수 있고, 그 결과 다음이 설명한 것들과 같은 특정 종류의 harm을 높이거나 낮출 수 있다Crawford (2017). models와 AI systems를 설계하고 개발하는 사람들은 상당한 power를 가진다. class design과 같은 것들에 대한 결정은 model performance뿐만 아니라 model biases가 어떻게 그리고 어떤 contexts에서 나타나는지의 핵심 결정 요인이다.
이러한 실험들은 포괄적이지 않다. 그것들은 class design과 bias의 다른 sources에서 비롯될 수 있는 잠재적 문제들을 보여주며, 탐구를 촉발하기 위한 것이다.
7.2 감시
다음으로 우리는 상당한 사회적 민감성이 있는 downstream task인 surveillance와 관련하여 model performance를 특성화하고자 했다. 우리의 분석은 위에서 설명한 characterization approach를 더 잘 구현하고, 연구 community가 점점 더 general purpose가 되는 computer vision models의 잠재적 미래 영향으로 방향을 잡도록 돕고, 그러한 systems에 관한 norms와 checks의 개발을 돕는 것을 목표로 한다. 우리가 surveillance를 포함한 것은 이 영역에 대한 열의를 나타내려는 것이 아니다 - 오히려 우리는 surveillance가 사회적 함의를 고려할 때 예측을 시도해야 할 중요한 영역이라고 생각한다(Zuboff,2015; Browne,2015).
우리는 CCTV cameras의 이미지 classification과 zero-shot celebrity identification에서 모델의 성능을 측정한다. 먼저 surveillance cameras(예: CCTV cameras)에서 캡처된 low-resolution images에 대한 model performance를 테스트했다. 우리는 VIRAT dataset을 사용했다(Oh et al.,2011)및 다음이 캡처한 데이터Varadarajan&Odobez (2009), 둘 다 non-actors가 있는 real world outdoor scenes로 구성된다.
CLIP의 유연한 class construction을 고려하여, 우리는 12개의 서로 다른 video sequences에서 캡처된 515 surveillance images를 coarse 및 fine grained classification을 위한 self-constructed general classes에서 테스트했다. Coarse classification은 모델이 이미지의 main subject를 올바르게 식별할 것을 요구했다(즉, 이미지가 빈 parking lot, school campus 등의 사진인지 결정). Fine-grained classification의 경우, 모델은 구석에 서 있는 사람과 같은 이미지 속 더 작은 features의 presence/absence를 식별할 수 있는지 결정하도록 구성된 두 옵션 중에서 선택해야 했다.
Coarse classification의 경우, 우리는 이미지의 내용을 설명하기 위해 이미지를 직접 hand-captioning하여 classes를 구성했고, 모델이 선택할 수 있는 옵션은 항상 최소 6개였다. 추가로, class set에 이미지와 ‘close’한 것에 대한 caption이 최소 하나 더 포함된 ‘stress test’를 수행했다(예: ‘parking lot with white car’ vs. ‘parking lot with red car’). 우리는 초기 평가에서 모델이 CCTV images에 대해 top-1 accuracy 91.8%를 가졌다는 것을 발견했다. 두 번째 평가에서는 accuracy가 51.1%로 크게 떨어졌고, 모델은 시간의 40.7%에서 ‘close’ answer를 잘못 선택했다.
Fine-grained detection의 경우, zero-shot model은 좋지 않게 수행했으며, 결과는 거의 무작위에 가까웠다. 이 실험은 image sequences에서 작은 objects의 presence 또는 absence를 detection하는 것만을 목표로 했다는 점에 유의하라.
우리는 또한 CelebA dataset을 사용하여 ‘in the wild’ identity detection에 대한 CLIP의 zero-shot performance를 테스트했다888Note: CelebA dataset은 더 밝은 skin tones의 얼굴을 더 대표한다. dataset의 성격 때문에 우리는 race, gender, age 등을 통제할 수 없었다.. 우리는 공개적으로 이용 가능한 pre-training data만을 사용한 identity detection에서 모델의 성능을 평가하기 위해 이를 수행했다. 우리는 인터넷에 더 많은 수의 images가 있는 celebrities dataset에서 이것을 테스트했지만, 모델이 더 강력해짐에 따라 faces를 names와 연관시키는 데 필요한 pre-training data의 이미지 수는 계속 감소할 것이라고 가정한다(Table 참조8), 이는 상당한 사회적 함의를 가진다(Garvie,2019). 이는 인터넷 데이터로 학습된 최근 large language models가 비교적 minor public figures와 관련된 정보를 제공하는 놀라운 능력을 종종 보이는 natural language processing의 최근 발전을 반영한다(Brown et al.,2020).
우리는 모델이 100 possible classes 중 ‘in the wild’ 8k celebrity images에 대해 59.2% top-1 accuracy를 가졌다는 것을 발견했다. 그러나 class sizes를 1k celebrity names로 늘렸을 때 이 성능은 43.3%로 떨어졌다. 이 성능은 Google’s Celebrity Recognition과 같은 production level models와 비교할 때 경쟁력이 없다(Google,). 그러나 이러한 결과를 주목할 만하게 만드는 것은 이 분석이 pre-training data에서 추론된 names에 기반한 zero-shot identification capabilities만을 사용하여 수행되었다는 점이다 - 우리는 추가적인 task-specific dataset을 전혀 사용하지 않았고, 따라서 (상대적으로) 강한 결과는 multimodal models를 deploy하기 전에 사람들이 주어진 context와 domain에서의 behaviors에 대해 신중하게 연구해야 함을 더욱 나타낸다.
CLIP은 zero-shot capabilities를 고려할 때 상대적으로 데이터가 거의 없는 과제에 상당한 benefit을 제공한다. 그러나 facial recognition과 같은 많은 in-demand surveillance tasks에 대해서는 large datasets와 high performing supervised models가 존재한다. 그 결과, 그러한 용도에 대한 CLIP의 comparative appeal은 낮다. 추가로, CLIP은 object detection 및 semantic segmentation과 같은 흔한 surveillance-relevant tasks를 위해 설계되지 않았다. 이는 Detectron2와 같이 이러한 용도를 염두에 두고 설계된 models가 널리 사용 가능할 때 특정 surveillance tasks에 대한 사용이 제한됨을 의미한다(Wu et al.,2019)널리 사용 가능하다.
그러나 CLIP은 training data의 필요성을 제거한다는 점에서 usability의 특정 측면을 열어준다. 따라서 CLIP 및 유사한 모델들은 잘 맞춤화된 models나 datasets가 존재하지 않는 bespoke, niche surveillance use cases를 가능하게 할 수 있으며, 그러한 applications를 구축하기 위한 skill requirements를 낮출 수 있다. 우리의 실험이 보여주듯, ZS CLIP은 오늘날 몇 가지 surveillance relevant tasks에서 non-trivial하지만 exceptional하지는 않은 성능을 보인다.
| 모델 | 100 Classes | 1k 클래스 | 2k 클래스 |
| CLIP L/14 | 59.2 | 43.3 | 42.2 |
| CLIP RN50x64 | 56.4 | 39.5 | 38.4 |
| CLIP RN50x16 | 52.7 | 37.4 | 36.3 |
| CLIP RN50x4 | 52.8 | 38.1 | 37.3 |
7.3 향후 연구
이 예비 분석은 범용 컴퓨터 비전 모델들이 제기하는 몇몇 도전 과제를 설명하고, 그 편향과 영향에 대한 일별을 제공하려는 의도이다. 우리는 이 작업이 그러한 모델들의 능력, 결점, 편향의 특성화에 관한 향후 연구를 동기부여하기를 바라며, 이러한 질문들에 대해 연구 커뮤니티와 함께 논의하게 되기를 기대한다.
우리는 앞으로 나아가는 좋은 한 단계는 CLIP과 같은 모델들의 능력을 더 특성화하고, 그리고 - 결정적으로 - 그것들이 유망한 성능을 보이는 응용 영역과 성능이 저하될 수 있는 영역을 식별하기 위한 커뮤니티 탐색이라고 믿는다999모델은 부적절한 성능 때문에 또는 응용 영역 자체에서 AI 사용이 부적절하기 때문에 사용에 적합하지 않을 수 있다.. 이러한 특성화 과정은 연구자들이 다음을 통해 모델이 유익하게 사용될 가능성을 높이는 데 도움을 줄 수 있다:
-
•
연구 과정 초기에 모델의 잠재적으로 유익한 다운스트림 사용을 식별하여, 다른 연구자들이 응용을 생각할 수 있게 한다.
-
•
상당한 민감도와 많은 사회적 이해관계자 집합을 가진 과제를 드러내며, 이는 정책입안자들의 개입을 요구할 수 있다.
-
•
모델의 편향을 더 잘 특성화하여, 다른 연구자들에게 우려 영역과 개입 영역을 알린다.
-
•
CLIP과 같은 시스템을 평가하기 위한 테스트 모음을 만들어, 개발 주기 초기에 모델 능력을 더 잘 특성화할 수 있게 한다.
-
•
잠재적 실패 모드와 추가 연구 영역을 식별한다.
우리는 이 작업에 기여할 계획이며, 이 분석이 후속 연구를 위한 몇 가지 동기부여 사례를 제공하기를 바란다.
8 관련 연구
훈련 신호의 일부로서 문자, 음성, 수어 또는 그 밖의 어떤 형태의 인간 언어를 활용하는 모든 모델은 논쟁의 여지는 있지만 자연어를 감독의 원천으로 사용하고 있다. 이는 인정하건대 매우 광범위한 영역이며, 토픽 모델을 포함한 분포 의미론 분야의 대부분의 연구를 포괄한다(Blei et al.,2003), 단어, 문장, 및 문단 벡터(Mikolov et al.,2013; Kiros et al.,2015; Le&Mikolov,2014), 및 언어 모델(Bengio et al.,2003). 또한 이는 어떤 방식으로든 자연어의 시퀀스를 예측하거나 모델링하는 것을 다루는 더 넓은 NLP 분야의 많은 부분을 포함한다. 설명, 피드백, 지시, 조언의 형태로 자연어 감독을 의도적으로 활용하는 NLP 연구는, 분류와 같은 과제에 대해(임의로 인코딩된 이산 범주 레이블 집합으로 감독을 표현하는 흔히 사용되는 방식과는 대조적으로) 많은 창의적이고 진보된 방식으로 탐구되어 왔다. 대화 기반 학습(Weston,2016; Li et al.,2016; Hancock et al.,2019)은 대화에서 상호작용적 자연어 피드백으로부터 학습하는 기법을 개발한다. 여러 논문은 자연어 설명을 특징으로 변환하기 위해 의미 구문 분석을 활용했다(Srivastava et al.,2017)또는 추가 훈련 레이블(Hancock et al.,2018). 더 최근에는, ExpBERT(Murty et al.,2020)는 관계 추출 과제에서 성능을 향상시키기 위해 자연어 설명과 관계의 기술에 deep contextual language model을 조건화하여 생성된 특징 표현을 사용한다.
CLIP은 언어 이외의 도메인에 대해 학습하기 위한 훈련 신호로 자연어를 사용하는 예이다. 이 맥락에서, 우리가 알고 있는 용어의 가장 이른 사용은natural language supervision의 연구이다Ramanathan et al. (2013)이는 비디오 이벤트 이해 과제에서 성능을 향상시키기 위해 자연어 설명이 다른 감독 원천과 함께 사용될 수 있음을 보였다. 그러나 서론과 접근법 절에서 언급했듯이, 컴퓨터 비전에서 자연어 설명을 활용하는 방법들은 이 특정 용어의 사용보다 훨씬 앞서 있으며, 특히 이미지 검색(Mori et al.,1999)및 객체 분류(Wang et al.,2009). 다른 초기 연구는 의미 분할 과제를 위해 이미지와 연관된 태그(그러나 자연어는 아님)를 활용했다(Barnard et al.,2003). 더 최근에는,He&Peng (2017)및Liang et al. (2020)은 새의 세밀한 시각 분류를 향상시키기 위해 자연어 설명과 해설을 사용하는 것을 입증했다. 다른 이들은 grounded language가 ShapeWorld dataset에서 시각 표현과 분류기를 향상시키는 데 어떻게 사용될 수 있는지 조사했다(Kuhnle&Copestake,2017; Andreas et al.,2017; Mu et al.,2019). 마지막으로, 자연어와 강화학습 환경을 결합하는 기법들은(Narasimhan et al.,2015)zero-shot 과제를 체계적으로 수행하는 것과 같은 흥미로운 emergent behavior를 입증했다(Hill et al.,2019).
CLIP의 사전훈련 과제는 text-image retrieval을 최적화한다. 이 연구 영역은 이전에 언급한Mori et al. (1999)가 초기 연구의 대표로서 있었던 90년대 중반으로 거슬러 올라간다. 초기 노력은 주로 예측 목적에 초점을 맞추었지만, 시간이 지나며 연구는 kernel Canonical Correlation Analysis 및 다양한 ranking objective와 같은 기법으로 joint multi-modal embedding space를 학습하는 쪽으로 이동했다(Weston et al.,2010; Socher&Fei-Fei,2010; Hodosh et al.,2013). 시간이 지나면서 연구는 훈련 목적, 전이, 그리고 더 표현력 있는 모델들의 많은 조합을 탐구했고 성능을 꾸준히 향상시켰다(Frome et al.,2013; Socher et al.,2014; Karpathy et al.,2014; Kiros et al.,2014; Faghri et al.,2017).
다른 연구는 이미지 이외의 도메인에 자연어 감독을 활용했다.Stroud et al. (2020)는 시스템을 훈련하여 이미지를 대신해 서술적 텍스트를 비디오와 짝짓게 함으로써 대규모 표현 학습을 탐구한다. 여러 연구는 비디오를 위한 밀집된 음성 자연어 감독의 사용을 탐구했다(Miech et al.,2019, 2020b). CLIP과 함께 고려할 때, 이러한 연구들은 대규모 자연어 감독이 많은 도메인에서 고품질 지각 시스템을 학습하는 유망한 방법임을 시사한다.Alayrac et al. (2020)는 raw audio를 추가 감독 원천으로 더함으로써 이 연구 계열을 추가 modality로 확장했고 세 가지 감독 원천 모두를 결합하는 것의 이점을 입증했다.
CLIP에 관한 우리의 작업의 일부로서 우리는 또한 image-text pair의 새로운 dataset을 구축한다. image-text retrieval에 관한 현대 연구는 Pascal1K와 같은 crowd-sourced sentence level image caption 평가 dataset 집합에 의존해 왔다(Rashtchian et al.,2010), Flickr8K(Hodosh et al.,2013), 및 Flickr30K(Young et al.,2014). 그러나 이러한 dataset들은 여전히 비교적 작고 달성 가능한 성능을 제한한다. 더 큰 dataset을 자동으로 만들기 위한 여러 방법이 제안되었으며,Ordonez et al. (2011)는 주목할 만한 초기 예이다. 딥러닝 시대에,Mithun et al. (2018)은 인터넷에서 수집한 추가적인 (image, text) pair 집합이 retrieval 성능을 향상시킬 수 있음을 입증했으며, Conceptual Captions와 같은 여러 새로운 자동 구축 dataset들이(Sharma et al.,2018), LAIT(Qi et al.,2020), 및 OCR-CC(Yang et al.,2020)생성되었다. 그러나 이러한 dataset들은 여전히 훨씬 더 공격적인 필터링을 사용하거나 OCR과 같은 특정 과제를 위해 설계되며, 그 결과 1백만에서 1천만 개의 훈련 예제 사이로 WIT보다 여전히 훨씬 작다.
CLIP과 관련된 아이디어는 webly supervised learning이다. 이 연구 계열은 용어를 질의하여 image dataset을 구축하기 위해 image search engine에 질의하고, 반환된 이미지의 레이블로 그 질의를 사용한다(Fergus et al.,2005). 이러한 크지만 잡음 많은 레이블이 붙은 dataset으로 훈련된 분류기는 더 작고 신중하게 레이블링된 dataset으로 훈련된 것들과 경쟁력이 있을 수 있다. 이러한 image-query pair는 또한 표준 dataset에서의 성능을 향상시키기 위한 추가 훈련 데이터로 자주 사용된다(Chen&Gupta,2015). CLIP 또한 dataset 생성 과정의 일부로 검색 질의를 사용한다. 그러나 CLIP은 종종 단일 단어 또는 짧은 n-gram에 불과한 질의만이 아니라, 이미지와 함께 발생하는 전체 텍스트 시퀀스만을 감독으로 사용한다. 또한 우리는 CLIP에서 이 단계를 하위 문자열 일치를 위한 텍스트 전용 질의로 제한하는 반면, 대부분의 webly supervised 연구는 자체적인 복잡한 retrieval 및 filtering pipeline을 가진 표준 image search engine을 사용하며, 이는 종종 computer vision system을 포함한다. 이 연구 계열 중,Learning Everything about Anything: Webly-Supervised Visual Concept Learning (Divvala et al.,2014)은 CLIP과 특히 유사한 야망과 목표를 가지고 있다.
마지막으로, CLIP은 vision과 language의 joint model을 학습하는 최근의 활발한 활동과 관련이 있다(Lu et al.,2019; Tan&Bansal,2019; Chen et al.,2019; Li et al.,2020b; Yu et al.,2020). 이 연구 계열은 visual question answering, visual commonsense reasoning, 또는 multimodal entailment와 같은 복잡한 다운스트림 과제를 해결하기 위해 vision과 language를 풍부하게 연결하는 데 초점을 맞춘다. 이러한 접근법들은 일반적으로 image feature model, region proposal / object detection model, 그리고 BERT와 같은 pre-trained masked language model이라는 3개(또는 그 이상)의 사전훈련된 하위 시스템을 결합하는 인상적으로 공학적으로 설계된 모델들을 활용한다. 그런 다음 이러한 시스템들은 image-text pair에 대해 다양한 훈련 목적을 통해 공동으로 fine-tune되고 앞서 언급한 과제들에 적용되어 인상적인 결과를 달성한다. 대신 CLIP은 자연어 감독을 통해 처음부터 시각 모델을 학습하는 데 초점을 맞추며, joint attention model로 두 도메인을 밀집하게 연결하지 않는다. CLIP model에서 image와 text domain 사이의 유일한 상호작용은 학습된 joint embedding space에서의 단일 dot product이다. 우리는 CLIP이 이 연구 계열과 hybridized되는 것을 보게 되기를 기대한다.
9 결론
우리는 NLP에서의 task-agnostic web-scale pre-training의 성공을 다른 도메인으로 전이하는 것이 가능한지 조사했다. 우리는 이 공식을 채택하면 컴퓨터 비전 분야에서도 유사한 행동이 나타난다는 것을 발견하고, 이 연구 계열의 사회적 함의를 논의한다. 훈련 목적을 최적화하기 위해, CLIP 모델들은 사전훈련 동안 다양한 과제를 수행하는 법을 학습한다. 그런 다음 이 과제 학습은 자연어 prompting을 통해 활용되어 많은 기존 dataset으로의 zero-shot transfer를 가능하게 할 수 있다. 충분한 규모에서는 이 접근법의 성능이 task-specific supervised model과 경쟁력이 있을 수 있지만, 여전히 개선의 여지는 많이 남아 있다.
감사의 말
우리는 CLIP이 훈련되는 데이터를 만드는 데 관여한 수백만 명의 사람들에게 감사하고 싶다. 또한 OpenAI에 있는 동안 image conditional language model에 관한 작업을 한 Susan Zhang, pseudocode의 오류를 잡아낸 Ishaan Gulrajani, 그리고 논문의 broader impacts section에 대한 사려 깊은 피드백을 준 Irene Solaiman, Miles Brundage, Gillian Hadfield에게도 감사하고 싶다. 또한 우리는 이 프로젝트가 사용한 소프트웨어 및 하드웨어 인프라에 대한 중요한 작업을 해준 OpenAI의 Acceleration 및 Supercomputing 팀들에게 감사한다. 마지막으로, 우리는 이 프로젝트 전반에 사용된 많은 소프트웨어 패키지의 개발자들에게도 감사하고 싶다. 여기에는 Numpy가 포함되지만 이에 한정되지는 않는다(Harris et al.,2020), SciPy(Virtanen et al.,2020), ftfy(Speer,2019), TensorFlow(Abadi et al.,2016), PyTorch(Paszke et al.,2019), pandas(pandas development team,2020), 및 scikit-learn(Pedregosa et al.,2011).
참고문헌
- Abadi et al. (2016) Abadi, M., Barham, P., Chen, J., Chen, Z., Davis, A., Dean, J., Devin, M., Ghemawat, S., Irving, G., Isard, M., et al. Tensorflow: 대규모 머신러닝을 위한 시스템. In12thUSENIXsymposium on operating systems design and implementation (OSDI 16), pp. 265–283, 2016.
- Alayrac et al. (2020) Alayrac, J.-B., Recasens, A., Schneider, R., Arandjelović, R., Ramapuram, J., De Fauw, J., Smaira, L., Dieleman, S., and Zisserman, A. Self-supervised multimodal versatile networks. arXiv preprint arXiv:2006.16228, 2020.
- Alcorn et al. (2019) Alcorn, M. A., Li, Q., Gong, Z., Wang, C., Mai, L., Ku, W.-S., and Nguyen, A. 포즈를 취하라: 신경망은 익숙한 객체의 이상한 포즈에 쉽게 속는다. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4845–4854, 2019.
- Andreas et al. (2017) Andreas, J., Klein, D., and Levine, S. 잠재 언어를 사용한 학습. arXiv preprint arXiv:1711.00482, 2017.
- Assiri (2020) Assiri, Y. 간단한 방법을 사용한 plain convolutional neural networks의 확률적 최적화. arXiv preprint arXiv:2001.08856, 2020.
- Bachman et al. (2019) Bachman, P., Hjelm, R. D., and Buchwalter, W. 뷰 간 상호 정보를 최대화하여 표현 학습하기. InAdvances in Neural Information Processing Systems, pp. 15535–15545, 2019.
- Barbu et al. (2019) Barbu, A., Mayo, D., Alverio, J., Luo, W., Wang, C., Gutfreund, D., Tenenbaum, J., and Katz, B. Objectnet: 객체 인식 모델의 한계를 밀어붙이기 위한 대규모 bias-controlled dataset. InAdvances in Neural Information Processing Systems, pp. 9453–9463, 2019.
- Barnard et al. (2003) Barnard, K., Duygulu, P., Forsyth, D., Freitas, N. d., Blei, D. M., and Jordan, M. I. 단어와 그림 매칭. Journal of machine learning research, 3(Feb):1107–1135, 2003.
- Bechmann&Bowker (2019) Bechmann, A. and Bowker, G. C. 다른 이름의 비지도: 소셜 미디어의 인공지능에서 지식 생산의 숨겨진 층. Big Data&Society, 6(1):205395171881956, January 2019. doi:10.1177/2053951718819569. URLhttps://doi.org/10.1177/2053951718819569.
- Bengio et al. (2003) Bengio, Y., Ducharme, R., Vincent, P., and Jauvin, C. 신경 확률적 언어 모델. Journal of machine learning research, 3(Feb):1137–1155, 2003.
- Bhargava&Forsyth (2019) Bhargava, S. and Forsyth, D. 이미지 캡셔닝 dataset과 model에서 gender bias를 드러내고 수정하기. arXiv preprint arXiv:1912.00578, 2019.
- Blei et al. (2003) Blei, D. M., Ng, A. Y., and Jordan, M. I. 잠재 디리클레 할당. Journal of machine Learning research, 3(Jan):993–1022, 2003.
- Bolukbasi et al. (2016) Bolukbasi, T., Chang, K.-W., Zou, J. Y., Saligrama, V., and Kalai, A. T. 남자가 컴퓨터 프로그래머에 대응하는 것은 여자가 주부에 대응하는 것인가? 단어 임베딩의 편향 제거. Advances in neural information processing systems, 29:4349–4357, 2016.
- Bowker&Star (2000) Bowker, G. C. and Star, S. L. 사물 정리하기: 분류와 그 결과. MIT press, 2000.
- Brown et al. (2020) Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. 언어 모델은 few-shot 학습자이다. arXiv preprint arXiv:2005.14165, 2020.
- Browne (2015) Browne, S. Dark Matters: Blackness의 감시. Duke University Press, 2015.
- Bulent Sariyildiz et al. (2020) Bulent Sariyildiz, M., Perez, J., and Larlus, D. 캡션 주석으로 시각적 표현 학습하기. arXiv e-prints, pp. arXiv–2008, 2020.
- Buolamwini&Gebru (2018) Buolamwini, J. and Gebru, T. Gender shades: 상업적 성별 분류에서의 교차적 정확도 격차. 에서Conference on fairness, accountability and transparency, pp. 77–91, 2018.
- Carreira et al. (2019) Carreira, J., Noland, E., Hillier, C., and Zisserman, A. kinetics-700 인간 행동 데이터셋에 관한 짧은 노트. arXiv preprint arXiv:1907.06987, 2019.
- Chen et al. (2020a) Chen, M., Radford, A., Child, R., Wu, J., Jun, H., Luan, D., and Sutskever, I. 픽셀로부터의 생성적 사전학습. 에서International Conference on Machine Learning, pp. 1691–1703. PMLR, 2020a.
- Chen et al. (2016) Chen, T., Xu, B., Zhang, C., and Guestrin, C. 부분선형 메모리 비용으로 deep nets 훈련하기. arXiv preprint arXiv:1604.06174, 2016.
- Chen et al. (2020b) Chen, T., Kornblith, S., Norouzi, M., and Hinton, G. 시각적 표현의 대조 학습을 위한 단순한 프레임워크. arXiv preprint arXiv:2002.05709, 2020b.
- Chen et al. (2020c) Chen, T., Kornblith, S., Swersky, K., Norouzi, M., and Hinton, G. 큰 자기지도 모델은 강력한 준지도 학습자이다. arXiv preprint arXiv:2006.10029, 2020c.
- Chen&Gupta (2015) Chen, X. and Gupta, A. 합성곱 네트워크의 웹 기반 지도 학습. 에서Proceedings of the IEEE International Conference on Computer Vision, pp. 1431–1439, 2015.
- Chen et al. (2020d) Chen, X., Fan, H., Girshick, R., and He, K. momentum contrastive learning을 사용한 개선된 기준선. arXiv preprint arXiv:2003.04297, 2020d.
- Chen et al. (2019) Chen, Y.-C., Li, L., Yu, L., Kholy, A. E., Ahmed, F., Gan, Z., Cheng, Y., and Liu, J. Uniter: 보편적 이미지-텍스트 표현 학습. arXiv preprint arXiv:1909.11740, 2019.
- Cheng et al. (2017) Cheng, G., Han, J., and Lu, X. 원격 탐사 이미지 장면 분류: 벤치마크와 최신 기술. Proceedings of the IEEE, 105(10):1865–1883, 2017.
- Choi et al. (2019) Choi, D., Shallue, C. J., Nado, Z., Lee, J., Maddison, C. J., and Dahl, G. E. 딥러닝을 위한 옵티마이저의 경험적 비교에 관하여. arXiv preprint arXiv:1910.05446, 2019.
- Coates et al. (2011) Coates, A., Ng, A., and Lee, H. 비지도 특징 학습에서 단일층 네트워크의 분석. 에서Proceedings of the fourteenth international conference on artificial intelligence and statistics, pp. 215–223, 2011.
- Crawford (2017) Crawford, K. 편향의 문제. NIPS 2017 Keynote, 2017. URLhttps://www.youtube.com/watch?v=fMym_BKWQzk.
- Dai&Le (2015) Dai, A. M. and Le, Q. V. 준지도 시퀀스 학습. 에서Advances in neural information processing systems, pp. 3079–3087, 2015.
- D’Amour et al. (2020) D’Amour, A., Heller, K., Moldovan, D., Adlam, B., Alipanahi, B., Beutel, A., Chen, C., Deaton, J., Eisenstein, J., Hoffman, M. D., et al. 불충분한 명세는 현대 머신러닝에서 신뢰성에 대한 과제를 제시한다. arXiv preprint arXiv:2011.03395, 2020.
- Deng et al. (2009) Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., and Fei-Fei, L. ImageNet: 대규모 계층적 이미지 데이터베이스. 에서CVPR09, 2009.
- Deng et al. (2012) Deng, J., Berg, A. C., Satheesh, S., Su, H., Khosla, A., and Fei-Fei, L. Ilsvrc 2012, 2012. URLhttp://www.image-net.org/challenges/LSVRC/2012/.
- Desai&Johnson (2020) Desai, K. and Johnson, J. Virtex: 텍스트 주석으로부터 시각적 표현 학습. arXiv preprint arXiv:2006.06666, 2020.
- Devlin et al. (2018) Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. Bert: 언어 이해를 위한 깊은 양방향 transformers의 사전 훈련. arXiv preprint arXiv:1810.04805, 2018.
- Dhariwal et al. (2020) Dhariwal, P., Jun, H., Payne, C., Kim, J. W., Radford, A., and Sutskever, I. Jukebox: 음악을 위한 생성 모델. arXiv preprint arXiv:2005.00341, 2020.
- Divvala et al. (2014) Divvala, S. K., Farhadi, A., and Guestrin, C. 무엇이든 모든 것을 학습하기: 웹 기반 지도 시각 개념 학습. 에서Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3270–3277, 2014.
- Dodge&Karam (2017) Dodge, S. and Karam, L. 시각적 왜곡 하에서 인간과 딥러닝 인식 성능의 연구 및 비교. 에서2017 26th international conference on computer communication and networks (ICCCN), pp. 1–7. IEEE, 2017.
- Dosovitskiy et al. (2020) Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al. 이미지는 16x16 단어의 가치가 있다: 대규모 이미지 인식을 위한 Transformers. arXiv preprint arXiv:2010.11929, 2020.
- Elhoseiny et al. (2013) Elhoseiny, M., Saleh, B., and Elgammal, A. 분류기를 작성하라: 순수한 텍스트 설명을 사용한 zero-shot learning. 에서Proceedings of the IEEE International Conference on Computer Vision, pp. 2584–2591, 2013.
- Faghri et al. (2017) Faghri, F., Fleet, D. J., Kiros, J. R., and Fidler, S. Vse++: hard negatives로 시각-의미 임베딩 개선하기. arXiv preprint arXiv:1707.05612, 2017.
- Fergus et al. (2005) Fergus, R., Fei-Fei, L., Perona, P., and Zisserman, A. google의 이미지 검색으로부터 객체 범주 학습하기. 에서Tenth IEEE International Conference on Computer Vision (ICCV’05) Volume 1, volume 2, pp. 1816–1823. IEEE, 2005.
- Frome et al. (2013) Frome, A., Corrado, G. S., Shlens, J., Bengio, S., Dean, J., Ranzato, M., and Mikolov, T. Devise: 깊은 시각-의미 임베딩 모델. 에서Advances in neural information processing systems, pp. 2121–2129, 2013.
- Gan et al. (2020) Gan, Z., Chen, Y.-C., Li, L., Zhu, C., Cheng, Y., and Liu, J. vision-and-language 표현 학습을 위한 대규모 적대적 훈련. arXiv preprint arXiv:2006.06195, 2020.
- Gao et al. (2020) Gao, T., Fisch, A., and Chen, D. 사전 훈련된 언어 모델을 더 나은 few-shot 학습자로 만들기. arXiv preprint arXiv:2012.15723, 2020.
- Garvie (2019) Garvie, C., May 2019. URLhttps://www.flawedfacedata.com/.
- Geiger et al. (2012) Geiger, A., Lenz, P., and Urtasun, R. 우리는 자율 주행을 위한 준비가 되었는가? kitti vision benchmark suite. 에서Conference on Computer Vision and Pattern Recognition (CVPR), 2012.
- Geirhos et al. (2018) Geirhos, R., Rubisch, P., Michaelis, C., Bethge, M., Wichmann, F. A., and Brendel, W. Imagenet으로 훈련된 cnns는 texture 쪽으로 편향되어 있다; shape bias를 증가시키면 정확도와 robustness가 향상된다. arXiv preprint arXiv:1811.12231, 2018.
- Geirhos et al. (2020) Geirhos, R., Jacobsen, J.-H., Michaelis, C., Zemel, R., Brendel, W., Bethge, M., and Wichmann, F. A. 심층 신경망에서의 shortcut learning. arXiv preprint arXiv:2004.07780, 2020.
- Gomez et al. (2017) Gomez, L., Patel, Y., Rusiñol, M., Karatzas, D., and Jawahar, C. 이미지를 텍스트 주제 공간에 임베딩함으로써 시각적 특징의 자기지도 학습. 에서Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4230–4239, 2017.
- Goodfellow et al. (2014) Goodfellow, I. J., Shlens, J., and Szegedy, C. 적대적 예제를 설명하고 활용하기. arXiv preprint arXiv:1412.6572, 2014.
- Goodfellow et al. (2015) Goodfellow, I. J., Erhan, D., Carrier, P. L., Courville, A., Mirza, M., Hamner, B., Cukierski, W., Tang, Y., Thaler, D., Lee, D.-H., et al. 표현 학습의 도전 과제: 세 가지 기계 학습 경연에 대한 보고서. Neural Networks, 64:59–63, 2015.
- (54) Google. Google cloud api: 유명인 인식. URLhttps://cloud.google.com/vision/docs/celebrity-recognition.
- Griewank&Walther (2000) Griewank, A. and Walther, A. Algorithm 799: revolve: 계산 미분의 역방향 또는 수반 모드를 위한 체크포인팅 구현. ACM Transactions on Mathematical Software (TOMS), 26(1):19–45, 2000.
- Grill et al. (2020) Grill, J.-B., Strub, F., Altché, F., Tallec, C., Richemond, P. H., Buchatskaya, E., Doersch, C., Pires, B. A., Guo, Z. D., Azar, M. G., et al. Bootstrap your own latent: 자기지도 학습에 대한 새로운 접근법. arXiv preprint arXiv:2006.07733, 2020.
- Ha et al. (2016) Ha, D., Dai, A., and Le, Q. V. Hypernetworks. arXiv preprint arXiv:1609.09106, 2016.
- Hancock et al. (2018) Hancock, B., Bringmann, M., Varma, P., Liang, P., Wang, S., and Ré, C. 자연어 설명으로 분류기 훈련하기. InProceedings of the conference. Association for Computational Linguistics. Meeting, volume 2018, pp. 1884. NIH Public Access, 2018.
- Hancock et al. (2019) Hancock, B., Bordes, A., Mazare, P.-E., and Weston, J. 배포 후 대화로부터 학습하기: 스스로를 먹여라, 챗봇! arXiv preprint arXiv:1901.05415, 2019.
- Harris et al. (2020) Harris, C. R., Millman, K. J., van der Walt, S. J., Gommers, R., Virtanen, P., Cournapeau, D., Wieser, E., Taylor, J., Berg, S., Smith, N. J., Kern, R., Picus, M., Hoyer, S., van Kerkwijk, M. H., Brett, M., Haldane, A., Fernández del Río, J., Wiebe, M., Peterson, P., Gérard-Marchant, P., Sheppard, K., Reddy, T., Weckesser, W., Abbasi, H., Gohlke, C., and Oliphant, T. E. NumPy를 사용한 배열 프로그래밍. Nature, 585:357–362, 2020. doi:10.1038/s41586-020-2649-2.
- Hays&Efros (2008) Hays, J. and Efros, A. A. Im2gps: 단일 이미지에서 지리 정보를 추정하기. In2008 ieee conference on computer vision and pattern recognition, pp. 1–8. IEEE, 2008.
- He et al. (2015) He, K., Zhang, X., Ren, S., and Sun, J. 정류기를 깊이 파고들기: imagenet 분류에서 인간 수준 성능을 넘어서기. InProceedings of the IEEE international conference on computer vision, pp. 1026–1034, 2015.
- He et al. (2016a) He, K., Zhang, X., Ren, S., and Sun, J. 이미지 인식을 위한 깊은 잔차 학습. InProceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778, 2016a.
- He et al. (2016b) He, K., Zhang, X., Ren, S., and Sun, J. 이미지 인식을 위한 깊은 잔차 학습. InProceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778, 2016b.
- He et al. (2020) He, K., Fan, H., Wu, Y., Xie, S., and Girshick, R. 비지도 시각 표현 학습을 위한 모멘텀 대조. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9729–9738, 2020.
- He et al. (2019) He, T., Zhang, Z., Zhang, H., Zhang, Z., Xie, J., and Li, M. 합성곱 신경망을 사용한 이미지 분류를 위한 트릭 모음. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 558–567, 2019.
- He&Peng (2017) He, X. and Peng, Y. 시각과 언어를 결합함으로써 세밀한 이미지 분류. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5994–6002, 2017.
- Helber et al. (2019) Helber, P., Bischke, B., Dengel, A., and Borth, D. Eurosat: 토지 이용 및 토지 피복 분류를 위한 새로운 데이터셋과 딥러닝 벤치마크. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 12(7):2217–2226, 2019.
- Henaff (2020) Henaff, O. 대조적 예측 부호화를 사용한 데이터 효율적 이미지 인식. InInternational Conference on Machine Learning, pp. 4182–4192. PMLR, 2020.
- Hendrycks&Dietterich (2019) Hendrycks, D. and Dietterich, T. 일반적인 손상과 교란에 대한 신경망 강건성 벤치마킹. arXiv preprint arXiv:1903.12261, 2019.
- Hendrycks&Gimpel (2016) Hendrycks, D. and Gimpel, K. Gaussian error linear units (gelus). arXiv preprint arXiv:1606.08415, 2016.
- Hendrycks et al. (2019) Hendrycks, D., Zhao, K., Basart, S., Steinhardt, J., and Song, D. 자연적 적대적 예제. arXiv preprint arXiv:1907.07174, 2019.
- Hendrycks et al. (2020a) Hendrycks, D., Basart, S., Mu, N., Kadavath, S., Wang, F., Dorundo, E., Desai, R., Zhu, T., Parajuli, S., Guo, M., et al. 강건성의 많은 얼굴: 분포 밖 일반화에 대한 비판적 분석. arXiv preprint arXiv:2006.16241, 2020a.
- Hendrycks et al. (2020b) Hendrycks, D., Liu, X., Wallace, E., Dziedzic, A., Krishnan, R., and Song, D. 사전훈련된 transformers는 분포 밖 강건성을 향상시킨다. arXiv preprint arXiv:2004.06100, 2020b.
- Hestness et al. (2017) Hestness, J., Narang, S., Ardalani, N., Diamos, G., Jun, H., Kianinejad, H., Patwary, M., Ali, M., Yang, Y., and Zhou, Y. 딥러닝 스케일링은 경험적으로 예측 가능하다. arXiv preprint arXiv:1712.00409, 2017.
- Hill et al. (2019) Hill, F., Lampinen, A., Schneider, R., Clark, S., Botvinick, M., McClelland, J. L., and Santoro, A. 위치한 에이전트에서 체계성과 일반화의 환경적 동인. InInternational Conference on Learning Representations, 2019.
- Hodosh et al. (2013) Hodosh, M., Young, P., and Hockenmaier, J. 이미지 설명을 순위 매기기 과제로 프레이밍하기: 데이터, 모델 및 평가 지표. Journal of Artificial Intelligence Research, 47:853–899, 2013.
- Hongsuck Seo et al. (2018) Hongsuck Seo, P., Weyand, T., Sim, J., and Han, B. Cplanet: 지도의 조합적 분할로 이미지 지리위치추정을 향상시키기. InProceedings of the European Conference on Computer Vision (ECCV), pp. 536–551, 2018.
- Howard&Ruder (2018) Howard, J. and Ruder, S. 텍스트 분류를 위한 보편적 언어 모델 미세조정. arXiv preprint arXiv:1801.06146, 2018.
- Ilyas et al. (2019) Ilyas, A., Santurkar, S., Tsipras, D., Engstrom, L., Tran, B., and Madry, A. 적대적 예제는 버그가 아니라, 특징이다. InAdvances in Neural Information Processing Systems, pp. 125–136, 2019.
- Ioffe&Szegedy (2015) Ioffe, S. and Szegedy, C. Batch normalization: 내부 공변량 이동을 줄임으로써 깊은 네트워크 훈련을 가속하기. arXiv preprint arXiv:1502.03167, 2015.
- Jaderberg et al. (2014) Jaderberg, M., Simonyan, K., Vedaldi, A., and Zisserman, A. 제약 없는 텍스트 인식을 위한 깊은 구조화 출력 학습. arXiv preprint arXiv:1412.5903, 2014.
- Jaderberg et al. (2015) Jaderberg, M., Simonyan, K., Zisserman, A., et al. Spatial transformer networks. Advances in neural information processing systems, 28:2017–2025, 2015.
- Johnson et al. (2017) Johnson, J., Hariharan, B., van der Maaten, L., Fei-Fei, L., Lawrence Zitnick, C., and Girshick, R. Clevr: 구성적 언어와 초보적 시각 추론을 위한 진단 데이터셋. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2901–2910, 2017.
- Joulin et al. (2016) Joulin, A., Van Der Maaten, L., Jabri, A., and Vasilache, N. 대규모 약지도 데이터로부터 시각 특징 학습하기. InEuropean Conference on Computer Vision, pp. 67–84. Springer, 2016.
- Kalfaoglu et al. (2020) Kalfaoglu, M., Kalkan, S., and Alatan, A. A. 행동 인식을 위해 bert를 사용한 3d cnn 아키텍처에서의 후기 시간 모델링. arXiv preprint arXiv:2008.01232, 2020.
- Kaplan et al. (2020) Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D. 신경 언어 모델을 위한 스케일링 법칙. arXiv preprint arXiv:2001.08361, 2020.
- Karpathy et al. (2014) Karpathy, A., Joulin, A., and Fei-Fei, L. F. 양방향 이미지 문장 매핑을 위한 깊은 fragment embeddings. InAdvances in neural information processing systems, pp. 1889–1897, 2014.
- Keyes (2018) Keyes, O. 잘못된 젠더 지정 기계들: 자동 성별 인식의 Trans/hci 함의. Proceedings of the ACM on Human-Computer Interaction, 2(CSCW):1–22, 2018.
- Kiela et al. (2020) Kiela, D., Firooz, H., Mohan, A., Goswami, V., Singh, A., Ringshia, P., and Testuggine, D. The hateful memes challenge: 멀티모달 밈에서 혐오 발언 탐지하기. arXiv preprint arXiv:2005.04790, 2020.
- Kingma&Ba (2014) Kingma, D. P. and Ba, J. Adam: 확률적 최적화를 위한 방법. arXiv preprint arXiv:1412.6980, 2014.
- Kiros et al. (2014) Kiros, R., Salakhutdinov, R., and Zemel, R. S. 멀티모달 신경 언어 모델로 시각-의미 임베딩 통합하기. arXiv preprint arXiv:1411.2539, 2014.
- Kiros et al. (2015) Kiros, R., Zhu, Y., Salakhutdinov, R. R., Zemel, R., Urtasun, R., Torralba, A., and Fidler, S. Skip-thought 벡터. 신경 정보 처리 시스템의 발전, 28:3294–3302, 2015.
- Kolesnikov et al. (2019) Kolesnikov, A., Beyer, L., Zhai, X., Puigcerver, J., Yung, J., Gelly, S., and Houlsby, N. 전이를 위한 일반적인 시각 표현의 대규모 학습. arXiv preprint arXiv:1912.11370, 2019.
- Kornblith et al. (2019) Kornblith, S., Shlens, J., and Le, Q. V. 더 나은 imagenet 모델은 더 잘 전이되는가? 에서IEEE 컴퓨터 비전 및 패턴 인식 학회 논문집, pp. 2661–2671, 2019.
- Krishna et al. (2017) Krishna, R., Zhu, Y., Groth, O., Johnson, J., Hata, K., Kravitz, J., Chen, S., Kalantidis, Y., Li, L.-J., Shamma, D. A., et al. Visual genome: 크라우드소싱된 조밀한 이미지 주석을 사용하여 언어와 시각을 연결하기. International journal of computer vision, 123(1):32–73, 2017.
- Krizhevsky et al. (2012) Krizhevsky, A., Sutskever, I., and Hinton, G. E. 심층 합성곱 신경망을 이용한 Imagenet 분류. 에서신경 정보 처리 시스템의 발전, pp. 1097–1105, 2012.
- Kuhnle&Copestake (2017) Kuhnle, A. and Copestake, A. Shapeworld-멀티모달 언어 이해를 위한 새로운 테스트 방법론. arXiv preprint arXiv:1704.04517, 2017.
- Kärkkäinen&Joo (2019) Kärkkäinen, K. and Joo, J. Fairface: 균형 잡힌 인종, 성별, 나이를 위한 얼굴 속성 데이터셋, 2019.
- Lake et al. (2016) Lake, B. M., Ullman, T. D., Tenenbaum, J. B., and Gershman, S. J. 사람처럼 배우고 생각하는 기계 만들기, 2016.
- Lampert et al. (2009) Lampert, C. H., Nickisch, H., and Harmeling, S. 클래스 간 속성 전이를 통해 보지 못한 객체 클래스를 탐지하는 학습. 에서2009 IEEE Conference on Computer Vision and Pattern Recognition, pp. 951–958. IEEE, 2009.
- Larochelle et al. (2008) Larochelle, H., Erhan, D., and Bengio, Y. 새로운 작업의 제로-데이터 학습. 2008.
- Le&Mikolov (2014) Le, Q. and Mikolov, T. 문장과 문서의 분산 표현. 에서International conference on machine learning, pp. 1188–1196, 2014.
- (104) LeCun, Y. 손글씨 숫자의 mnist 데이터베이스. http://yann. lecun. com/exdb/mnist/.
- (105) Lee, D.-H. Pseudo-label: 심층 신경망을 위한 단순하고 효율적인 반지도 학습 방법.
- Lei Ba et al. (2015) Lei Ba, J., Swersky, K., Fidler, S., et al. 텍스트 설명을 사용하여 심층 zero-shot 합성곱 신경망 예측하기. 에서IEEE International Conference on Computer Vision 논문집, pp. 4247–4255, 2015.
- Li et al. (2017) Li, A., Jabri, A., Joulin, A., and van der Maaten, L. 웹 데이터로부터 시각적 n-그램 학습하기. 에서IEEE International Conference on Computer Vision 논문집, pp. 4183–4192, 2017.
- Li et al. (2020a) Li, G., Duan, N., Fang, Y., Gong, M., and Jiang, D. Unicoder-vl: 교차-모달 사전 학습에 의한 시각과 언어를 위한 범용 인코더. 2020a.
- Li et al. (2016) Li, J., Miller, A. H., Chopra, S., Ranzato, M., and Weston, J. 질문을 함으로써 대화 상호작용을 통해 학습하기. arXiv preprint arXiv:1612.04936, 2016.
- Li et al. (2020b) Li, X., Yin, X., Li, C., Hu, X., Zhang, P., Zhang, L., Wang, L., Hu, H., Dong, L., Wei, F., et al. Oscar: 시각-언어 작업을 위한 객체-의미 정렬 사전 학습. arXiv preprint arXiv:2004.06165, 2020b.
- Liang et al. (2020) Liang, W., Zou, J., and Yu, Z. Alice: 대조적 자연어 설명을 이용한 능동 학습. arXiv preprint arXiv:2009.10259, 2020.
- Lin et al. (2014) Lin, T.-Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., and Zitnick, C. L. Microsoft coco: 맥락 속의 일반 객체. 에서European conference on computer vision, pp. 740–755. Springer, 2014.
- Linzen (2020) Linzen, T. 인간과 같은 언어적 일반화를 향한 진전을 어떻게 가속할 수 있는가? arXiv preprint arXiv:2005.00955, 2020.
- Lippe et al. (2020) Lippe, P., Holla, N., Chandra, S., Rajamanickam, S., Antoniou, G., Shutova, E., and Yannakoudakis, H. 혐오 밈 탐지를 위한 멀티모달 프레임워크. arXiv preprint arXiv:2012.12871, 2020.
- Liu et al. (2018) Liu, P. J., Saleh, M., Pot, E., Goodrich, B., Sepassi, R., Kaiser, L., and Shazeer, N. 긴 시퀀스를 요약하여 wikipedia 생성하기. arXiv preprint arXiv:1801.10198, 2018.
- Locatello et al. (2020) Locatello, F., Bauer, S., Lucic, M., Rätsch, G., Gelly, S., Schölkopf, B., and Bachem, O. 분리된 표현의 비지도 학습과 그 평가에 대한 냉정한 고찰. arXiv preprint arXiv:2010.14766, 2020.
- Loshchilov&Hutter (2016) Loshchilov, I. and Hutter, F. Sgdr: 웜 리스타트를 이용한 확률적 경사 하강법. arXiv preprint arXiv:1608.03983, 2016.
- Loshchilov&Hutter (2017) Loshchilov, I. and Hutter, F. 분리된 가중치 감쇠 정규화. arXiv preprint arXiv:1711.05101, 2017.
- Lu et al. (2019) Lu, J., Batra, D., Parikh, D., and Lee, S. Vilbert: 시각-및-언어 작업을 위한 작업-불가지론적 시각언어 표현 사전학습. 에서Advances in Neural Information Processing Systems, pp. 13–23, 2019.
- Lu et al. (2020) Lu, Z., Xiong, X., Li, Y., Stroud, J., and Ross, D. 행동 인식을 위해 약하게 지도된 데이터와 포즈 표현 활용하기, 2020. URLhttps://www.youtube.com/watch?v=KOQFxbPPLOE&t=1390s.
- Lucic et al. (2018) Lucic, M., Kurach, K., Michalski, M., Gelly, S., and Bousquet, O. gans는 동등하게 만들어졌는가? 대규모 연구. 신경 정보 처리 시스템의 발전, 31:700–709, 2018.
- Mahajan et al. (2018) Mahajan, D., Girshick, R., Ramanathan, V., He, K., Paluri, M., Li, Y., Bharambe, A., and van der Maaten, L. 약하게 지도된 사전학습의 한계 탐구. 에서European Conference on Computer Vision (ECCV) 논문집, pp. 181–196, 2018.
- McCann et al. (2017) McCann, B., Bradbury, J., Xiong, C., and Socher, R. 번역에서 학습됨: 문맥화된 단어 벡터. 에서신경 정보 처리 시스템의 발전, pp. 6294–6305, 2017.
- McCann et al. (2018) McCann, B., Keskar, N. S., Xiong, C., and Socher, R. 자연어 데카슬론: 질문 응답으로서의 멀티태스크 학습. arXiv preprint arXiv:1806.08730, 2018.
- Micikevicius et al. (2017) Micikevicius, P., Narang, S., Alben, J., Diamos, G., Elsen, E., Garcia, D., Ginsburg, B., Houston, M., Kuchaiev, O., Venkatesh, G., et al. 혼합 정밀도 학습. arXiv preprint arXiv:1710.03740, 2017.
- Miech et al. (2019) Miech, A., Zhukov, D., Alayrac, J.-B., Tapaswi, M., Laptev, I., and Sivic, J. Howto100m: 1억 개의 내레이션된 비디오 클립을 보며 텍스트-비디오 임베딩 학습하기. 에서IEEE international conference on computer vision 논문집, pp. 2630–2640, 2019.
- Miech et al. (2020a) Miech, A., Alayrac, J.-B., Laptev, I., Sivic, J., and Zisserman, A. Rareact: 특이한 상호작용의 비디오 데이터셋. arXiv preprint arXiv:2008.01018, 2020a.
- Miech et al. (2020b) Miech, A., Alayrac, J.-B., Smaira, L., Laptev, I., Sivic, J., and Zisserman, A. 정제되지 않은 교육용 비디오로부터 시각 표현의 엔드-투-엔드 학습. 에서IEEE/CVF Conference on Computer Vision and Pattern Recognition 논문집, pp. 9879–9889, 2020b.
- Mikolov et al. (2013) Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., and Dean, J. 단어와 구의 분산 표현 및 그 합성성. 신경 정보 처리 시스템의 발전, 26:3111–3119, 2013.
- Miller et al. (2020) Miller, J., Krauth, K., Recht, B., and Schmidt, L. 자연 분포 변화가 질문 응답 모델에 미치는 영향. arXiv preprint arXiv:2004.14444, 2020.
- Mishra et al. (2012) Mishra, A., Alahari, K., and Jawahar, C. 고차 언어 사전지식을 사용한 장면 텍스트 인식. 2012.
- Mithun et al. (2018) Mithun, N. C., Panda, R., Papalexakis, E. E., and Roy-Chowdhury, A. K. 교차-모달 이미지-텍스트 검색을 위한 웹 지도 공동 임베딩. 에서제26회 ACM international conference on Multimedia 논문집, pp. 1856–1864, 2018.
- Mori et al. (1999) Mori, Y., Takahashi, H., and Oka, R. 이미지를 단어와 함께 분할하고 벡터 양자화하는 것에 기반한 이미지-대-단어 변환. Citeseer, 1999.
- Mu et al. (2019) Mu, J., Liang, P., and Goodman, N. few-shot 분류를 위해 언어로 시각 표현 형성하기. arXiv preprint arXiv:1911.02683, 2019.
- Muller-Budack et al. (2018) Muller-Budack, E., Pustu-Iren, K., and Ewerth, R. 계층적 모델과 장면 분류를 사용한 사진의 지리 위치 추정. 에서European Conference on Computer Vision (ECCV) 논문집, pp. 563–579, 2018.
- Murty et al. (2020) Murty, S., Koh, P. W., and Liang, P. Expbert: 자연어 설명을 이용한 표현 공학. arXiv preprint arXiv:2005.01932, 2020.
- Narasimhan 등 (2015) Narasimhan, K., Kulkarni, T., and Barzilay, R. 심층 강화학습을 사용한 텍스트 기반 게임을 위한 언어 이해. arXiv preprint arXiv:1506.08941, 2015.
- Netzer 등 (2011) Netzer, Y., Wang, T., Coates, A., Bissacco, A., Wu, B., and Ng, A. Y. 비지도 특징 학습을 사용한 자연 이미지 속 숫자 읽기. 2011.
- Noble (2018) Noble, S. U. 억압의 알고리즘: 검색 엔진이 인종차별을 강화하는 방식. 2018.
- Nosek 등 (2002) Nosek, B. A., Banaji, M. R., and Greenwald, A. G. 시연 웹 사이트로부터 암묵적 집단 태도와 믿음 수확하기. Group Dynamics: Theory, Research, and Practice, 6(1):101, 2002.
- Oh 등 (2011) Oh, S., Hoogs, A., Perera, A., Cuntoor, N., Chen, C.-C., Lee, J. T., Mukherjee, S., Aggarwal, J., Lee, H., Davis, L., et al. 감시 비디오에서의 이벤트 인식을 위한 대규모 벤치마크 데이터셋. 에서CVPR 2011, pp. 3153–3160. IEEE, 2011.
- Oliver 등 (2018) Oliver, A., Odena, A., Raffel, C. A., Cubuk, E. D., and Goodfellow, I. 심층 준지도 학습 알고리즘의 현실적인 평가. Advances in neural information processing systems, 31:3235–3246, 2018.
- Oord 등 (2018) Oord, A. v. d., Li, Y., and Vinyals, O. 대조적 예측 코딩을 통한 표현 학습. arXiv preprint arXiv:1807.03748, 2018.
- Ordonez 등 (2011) Ordonez, V., Kulkarni, G., and Berg, T. Im2text: 캡션이 달린 100만 장의 사진을 사용하여 이미지 설명하기. Advances in neural information processing systems, 24:1143–1151, 2011.
- pandas development team (2020) pandas development team, T. pandas-dev/pandas: Pandas, 2020년 2월. URLhttps://doi.org/10.5281/zenodo.3509134.
- Parkhi 등 (2012) Parkhi, O. M., Vedaldi, A., Zisserman, A., and Jawahar, C. V. 고양이와 개. 에서IEEE Conference on Computer Vision and Pattern Recognition, 2012.
- Paszke 등 (2019) Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., Desmaison, A., Kopf, A., Yang, E., DeVito, Z., Raison, M., Tejani, A., Chilamkurthy, S., Steiner, B., Fang, L., Bai, J., and Chintala, S. Pytorch: 명령형 스타일의 고성능 딥러닝 라이브러리. 에서Advances in Neural Information Processing Systems 32, pp. 8024–8035, 2019.
- Pedregosa 등 (2011) Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., Vanderplas, J., Passos, A., Cournapeau, D., Brucher, M., Perrot, M., and Duchesnay, E. Scikit-learn: Python에서의 머신러닝. Journal of Machine Learning Research, 12:2825–2830, 2011.
- Pennington 등 (2014) Pennington, J., Socher, R., and Manning, C. D. Glove: 단어 표현을 위한 전역 벡터. 에서Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pp. 1532–1543, 2014.
- Peters 등 (2018) Peters, M. E., Neumann, M., Iyyer, M., Gardner, M., Clark, C., Lee, K., and Zettlemoyer, L. 깊은 문맥화된 단어 표현. arXiv preprint arXiv:1802.05365, 2018.
- Qi 등 (2020) Qi, D., Su, L., Song, J., Cui, E., Bharti, T., and Sacheti, A. Imagebert: 대규모 약지도 이미지-텍스트 데이터를 사용한 교차 모달 사전학습. arXiv preprint arXiv:2001.07966, 2020.
- Quattoni 등 (2007) Quattoni, A., Collins, M., and Darrell, T. 캡션이 있는 이미지를 사용한 시각 표현 학습. 에서2007 IEEE Conference on Computer Vision and Pattern Recognition, pp. 1–8. IEEE, 2007.
- Radford 등 (2018) Radford, A., Narasimhan, K., Salimans, T., and Sutskever, I. 생성적 사전학습을 통한 언어 이해 개선, 2018.
- Radford 등 (2019) Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., and Sutskever, I. 언어 모델은 비지도 멀티태스크 학습자이다. 2019.
- Raffel 등 (2019) Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., and Liu, P. J. 통합된 text-to-text transformer로 전이 학습의 한계 탐색하기. arXiv preprint arXiv:1910.10683, 2019.
- Raji 등 (2020) Raji, I. D., Gebru, T., Mitchell, M., Buolamwini, J., Lee, J., and Denton, E. 체면 살리기: 얼굴 인식 감사의 윤리적 우려 조사, 2020.
- Ramanathan 등 (2013) Ramanathan, V., Liang, P., and Fei-Fei, L. 자연어 설명을 사용한 비디오 이벤트 이해. 에서Proceedings of the IEEE International Conference on Computer Vision, pp. 905–912, 2013.
- Rashtchian 등 (2010) Rashtchian, C., Young, P., Hodosh, M., and Hockenmaier, J. amazon’s mechanical turk를 사용한 이미지 주석 수집. 에서Proceedings of the NAACL HLT 2010 Workshop on Creating Speech and Language Data with Amazon’s Mechanical Turk, pp. 139–147, 2010.
- Recht 등 (2019) Recht, B., Roelofs, R., Schmidt, L., and Shankar, V. imagenet 분류기는 imagenet에 일반화되는가? arXiv preprint arXiv:1902.10811, 2019.
- Salimans&Kingma (2016) Salimans, T. and Kingma, D. P. Weight normalization: 심층 신경망의 학습을 가속하기 위한 단순한 재매개변수화. 에서Advances in neural information processing systems, pp. 901–909, 2016.
- Scheuerman 등 (2019) Scheuerman, M. K., Paul, J. M., and Brubaker, J. R. 컴퓨터가 젠더를 보는 방식: 상업적 얼굴 분석 서비스에서의 젠더 분류 평가. Proceedings of the ACM on Human-Computer Interaction, 3(CSCW):1–33, 2019.
- Schwemmer 등 (2020) Schwemmer, C., Knight, C., Bello-Pardo, E. D., Oklobdzija, S., Schoonvelde, M., and Lockhart, J. W. 이미지 인식 시스템에서 젠더 편향 진단하기. Socius, 6:2378023120967171, 2020.
- Sennrich 등 (2015) Sennrich, R., Haddow, B., and Birch, A. 하위 단어 단위를 사용한 희귀 단어의 신경 기계 번역. arXiv preprint arXiv:1508.07909, 2015.
- Shankar 등 (2019) Shankar, V., Dave, A., Roelofs, R., Ramanan, D., Recht, B., and Schmidt, L. 이미지 분류기는 시간에 걸쳐 일반화되는가? arXiv preprint arXiv:1906.02168, 2019.
- Sharma 등 (2018) Sharma, P., Ding, N., Goodman, S., and Soricut, R. Conceptual captions: 자동 이미지 캡셔닝을 위한 정제되고 상위어화된 이미지 alt-text 데이터셋. 에서Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 2556–2565, 2018.
- Singh 등 (2019) Singh, A., Natarajan, V., Shah, M., Jiang, Y., Chen, X., Batra, D., Parikh, D., and Rohrbach, M. 읽을 수 있는 vqa 모델을 향하여. 에서Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 8317–8326, 2019.
- Socher&Fei-Fei (2010) Socher, R. and Fei-Fei, L. 모달리티 연결하기: 정렬되지 않은 텍스트 말뭉치를 사용한 이미지의 준지도 분할 및 주석. 에서2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, pp. 966–973. IEEE, 2010.
- Socher 등 (2013) Socher, R., Perelygin, A., Wu, J., Chuang, J., Manning, C. D., Ng, A. Y., and Potts, C. 감성 treebank 전반의 의미론적 구성성을 위한 재귀적 심층 모델. 에서Proceedings of the 2013 conference on empirical methods in natural language processing, pp. 1631–1642, 2013.
- Socher 등 (2014) Socher, R., Karpathy, A., Le, Q. V., Manning, C. D., and Ng, A. Y. 문장으로 이미지를 찾고 설명하기 위한 근거 있는 구성적 의미론. Transactions of the Association for Computational Linguistics, 2:207–218, 2014.
- Sohn (2016) Sohn, K. 다중 클래스 n-pair loss 목적함수를 사용한 개선된 심층 metric learning. 에서Advances in neural information processing systems, pp. 1857–1865, 2016.
- Solaiman 등 (2019) Solaiman, I., Brundage, M., Clark, J., Askell, A., Herbert-Voss, A., Wu, J., Radford, A., Krueger, G., Kim, J. W., Kreps, S., McCain, M., Newhouse, A., Blazakis, J., McGuffie, K., and Wang, J. 언어 모델의 공개 전략과 사회적 영향, 2019.
- Soomro 등 (2012) Soomro, K., Zamir, A. R., and Shah, M. Ucf101: 야생 비디오에서 가져온 101개 인간 행동 클래스의 데이터셋. arXiv preprint arXiv:1212.0402, 2012.
- Speer (2019) Speer, R. ftfy. Zenodo, 2019. URLhttps://doi.org/10.5281/zenodo.2591652. Version 5.5.
- Srivastava&Salakhutdinov (2012) Srivastava, N. and Salakhutdinov, R. 심층 볼츠만 머신을 사용한 멀티모달 학습. 에서NIPS, 2012.
- Srivastava 등 (2017) Srivastava, S., Labutov, I., and Mitchell, T. 자연어 설명으로부터의 공동 개념 학습 및 의미 파싱. 에서Proceedings of the 2017 conference on empirical methods in natural language processing, pp. 1527–1536, 2017.
- Stallkamp 등 (2011) Stallkamp, J., Schlipsing, M., Salmen, J., and Igel, C. The German Traffic Sign Recognition Benchmark: 다중 클래스 분류 대회. 에서IEEE International Joint Conference on Neural Networks, pp. 1453–1460, 2011.
- Stroud 등 (2020) Stroud, J. C., Ross, D. A., Sun, C., Deng, J., Sukthankar, R., and Schmid, C. 텍스트 웹 감독으로부터 비디오 표현 학습하기. arXiv preprint arXiv:2007.14937, 2020.
- Szegedy 등 (2016) Szegedy, C., Ioffe, S., Vanhoucke, V., and Alemi, A. Inception-v4, inception-resnet 및 잔차 연결이 학습에 미치는 영향. arXiv preprint arXiv:1602.07261, 2016.
- Tan&Bansal (2019) Tan, H. and Bansal, M. Lxmert: 트랜스포머로부터 교차-모달리티 인코더 표현 학습. arXiv preprint arXiv:1908.07490, 2019.
- Tan&Le (2019) Tan, M. and Le, Q. V. Efficientnet: 합성곱 신경망을 위한 모델 스케일링 재고. arXiv preprint arXiv:1905.11946, 2019.
- Taori et al. (2020) Taori, R., Dave, A., Shankar, V., Carlini, N., Recht, B., and Schmidt, L. 이미지 분류에서 자연적 분포 변화에 대한 견고성 측정. arXiv preprint arXiv:2007.00644, 2020.
- Thomee et al. (2016) Thomee, B., Shamma, D. A., Friedland, G., Elizalde, B., Ni, K., Poland, D., Borth, D., and Li, L.-J. Yfcc100m: 멀티미디어 연구의 새로운 데이터. Communications of the ACM, 59(2):64–73, 2016.
- Tian et al. (2019) Tian, Y., Krishnan, D., and Isola, P. 대조적 다중뷰 코딩. arXiv preprint arXiv:1906.05849, 2019.
- Tian et al. (2020) Tian, Y., Wang, Y., Krishnan, D., Tenenbaum, J. B., and Isola, P. Few-shot 이미지 분류 재고: 좋은 임베딩만 있으면 충분한가? arXiv preprint arXiv:2003.11539, 2020.
- Torralba et al. (2008) Torralba, A., Fergus, R., and Freeman, W. T. 8천만 개의 작은 이미지: 비모수 객체 및 장면 인식을 위한 대규모 데이터 세트. IEEE transactions on pattern analysis and machine intelligence, 30(11):1958–1970, 2008.
- Touvron et al. (2019) Touvron, H., Vedaldi, A., Douze, M., and Jégou, H. 학습-테스트 해상도 불일치 수정. InAdvances in neural information processing systems, pp. 8252–8262, 2019.
- Varadarajan&Odobez (2009) Varadarajan, J. and Odobez, J.-M. 장면 분석과 이상 탐지를 위한 토픽 모델. In2009 IEEE 12th International Conference on Computer Vision Workshops, ICCV Workshops, pp. 1338–1345. IEEE, 2009.
- Vaswani et al. (2017) Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., and Polosukhin, I. Attention is all you need. InAdvances in neural information processing systems, pp. 5998–6008, 2017.
- Veeling et al. (2018) Veeling, B. S., Linmans, J., Winkens, J., Cohen, T., and Welling, M. 디지털 병리학을 위한 회전 등변 CNN. 2018년 6월.
- Virtanen et al. (2020) Virtanen, P., Gommers, R., Oliphant, T. E., Haberland, M., Reddy, T., Cournapeau, D., Burovski, E., Peterson, P., Weckesser, W., Bright, J., van der Walt, S. J., Brett, M., Wilson, J., Millman, K. J., Mayorov, N., Nelson, A. R. J., Jones, E., Kern, R., Larson, E., Carey, C. J., Polat, İ., Feng, Y., Moore, E. W., VanderPlas, J., Laxalde, D., Perktold, J., Cimrman, R., Henriksen, I., Quintero, E. A., Harris, C. R., Archibald, A. M., Ribeiro, A. H., Pedregosa, F., van Mulbregt, P., and SciPy 1.0 Contributors. SciPy 1.0: Python에서의 과학 컴퓨팅을 위한 기본 알고리즘. Nature Methods, 17:261–272, 2020. doi:10.1038/s41592-019-0686-2.
- Vo et al. (2017) Vo, N., Jacobs, N., and Hays, J. 딥러닝 시대의 im2gps 재검토. InProceedings of the IEEE International Conference on Computer Vision, pp. 2621–2630, 2017.
- Wang et al. (2018) Wang, A., Singh, A., Michael, J., Hill, F., Levy, O., and Bowman, S. R. Glue: 자연어 이해를 위한 다중-작업 벤치마크 및 분석 플랫폼. arXiv preprint arXiv:1804.07461, 2018.
- Wang et al. (2019) Wang, H., Ge, S., Lipton, Z., and Xing, E. P. 국소 예측력을 벌점화하여 견고한 전역 표현 학습. InAdvances in Neural Information Processing Systems, pp. 10506–10518, 2019.
- Wang et al. (2020) Wang, H., Lu, P., Zhang, H., Yang, M., Bai, X., Xu, Y., He, M., Wang, Y., and Liu, W. 필요한 것은 경계뿐: 임의 형태 텍스트 스포팅을 향하여. InProceedings of the AAAI Conference on Artificial Intelligence, volume 34, pp. 12160–12167, 2020.
- Wang et al. (2009) Wang, J., Markert, K., and Everingham, M. 자연어 설명으로부터 객체 인식을 위한 모델 학습. InBMVC, volume 1, pp. 2, 2009.
- Weston et al. (2010) Weston, J., Bengio, S., and Usunier, N. 대규모 이미지 주석: 결합 단어-이미지 임베딩으로 순위화 학습. Machine learning, 81(1):21–35, 2010.
- Weston (2016) Weston, J. E. 대화 기반 언어 학습. InAdvances in Neural Information Processing Systems, pp. 829–837, 2016.
- Weyand et al. (2016) Weyand, T., Kostrikov, I., and Philbin, J. 합성곱 신경망을 이용한 Planet-photo 지리 위치 추정. InEuropean Conference on Computer Vision, pp. 37–55. Springer, 2016.
- Wu et al. (2019) Wu, Y., Kirillov, A., Massa, F., Lo, W.-Y., and Girshick, R. Detectron2. https://github.com/facebookresearch/detectron2, 2019.
- Wu et al. (2018) Wu, Z., Xiong, Y., Yu, S., and Lin, D. 비모수 인스턴스 수준 판별을 통한 비지도 특징 학습. arXiv preprint arXiv:1805.01978, 2018.
- Xie et al. (2020) Xie, Q., Luong, M.-T., Hovy, E., and Le, Q. V. Noisy Student를 이용한 자기 학습은 ImageNet 분류를 향상시킨다. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10687–10698, 2020.
- y Arcas et al. (2017) y Arcas, B. A., Mitchell, M., and Todorov, A. 관상학의 새 옷. 2017. URLhttps://medium.com/@blaisea/physiognomys-new-clothes-f2d4b59fdd6a.
- Yang et al. (2020) Yang, Z., Lu, Y., Wang, J., Yin, X., Florencio, D., Wang, L., Zhang, C., Zhang, L., and Luo, J. Tap: text-vqa와 text-caption을 위한 텍스트 인식 사전학습. arXiv preprint arXiv:2012.04638, 2020.
- Yogatama et al. (2019) Yogatama, D., d’Autume, C. d. M., Connor, J., Kocisky, T., Chrzanowski, M., Kong, L., Lazaridou, A., Ling, W., Yu, L., Dyer, C., et al. 일반 언어 지능의 학습과 평가. arXiv preprint arXiv:1901.11373, 2019.
- Young et al. (2014) Young, P., Lai, A., Hodosh, M., and Hockenmaier, J. 이미지 설명에서 시각적 지시체까지: 사건 설명에 대한 의미 추론을 위한 새로운 유사도 메트릭. Transactions of the Association for Computational Linguistics, 2:67–78, 2014.
- Yu et al. (2020) Yu, F., Tang, J., Yin, W., Sun, Y., Tian, H., Wu, H., and Wang, H. Ernie-vil: 장면 그래프를 통한 지식 강화 시각-언어 표현. arXiv preprint arXiv:2006.16934, 2020.
- Zeiler&Fergus (2014) Zeiler, M. D. and Fergus, R. 합성곱 네트워크의 시각화와 이해. InEuropean conference on computer vision, pp. 818–833. Springer, 2014.
- Zhai et al. (2019) Zhai, X., Puigcerver, J., Kolesnikov, A., Ruyssen, P., Riquelme, C., Lucic, M., Djolonga, J., Pinto, A. S., Neumann, M., Dosovitskiy, A., et al. visual task adaptation benchmark를 이용한 표현 학습의 대규모 연구. arXiv preprint arXiv:1910.04867, 2019.
- Zhang (2019) Zhang, R. 합성곱 네트워크를 다시 shift-invariant하게 만들기. arXiv preprint arXiv:1904.11486, 2019.
- Zhang et al. (2020) Zhang, Y., Jiang, H., Miura, Y., Manning, C. D., and Langlotz, C. P. 쌍을 이룬 이미지와 텍스트로부터 의료 시각 표현의 대조 학습. arXiv preprint arXiv:2010.00747, 2020.
- Zuboff (2015) Zuboff, S. 거대한 타자: 감시 자본주의와 정보 문명의 전망. Journal of Information Technology, 30(1):75–89, 2015.
Appendix ALinear-probe 평가
우리는 평가에 사용된 데이터셋과 모델의 목록을 포함하여, 이 논문에서 제시한 linear probe 실험에 대한 추가 세부 사항을 제공한다.
A.1 데이터셋
우리는 다음에 의해 도입된 잘 연구된 평가 모음의 12개 데이터셋을 사용하고(Kornblith et al.,2019)더 다양한 분포와 작업에서 모델의 성능을 평가하기 위해 15개의 추가 데이터셋을 더한다. 이러한 데이터셋에는 MNIST, Facial Expression Recognition 2013 dataset(Goodfellow et al.,2015), STL-10(Coates et al.,2011), EuroSAT(Helber et al.,2019), NWPU-RESISC45 dataset(Cheng et al.,2017), German Traffic Sign Recognition Benchmark (GTSRB) dataset(Stallkamp et al.,2011), KITTI dataset(Geiger et al.,2012), PatchCamelyon(Veeling et al.,2018), UCF101 action recognition dataset(Soomro et al.,2012), Kinetics 700(Carreira et al.,2019), CLEVR dataset의 무작위 표본 2,500개(Johnson et al.,2017), Hateful Memes dataset(Kiela et al.,2020), 그리고 ImageNet-1k dataset(Deng et al.,2012). 두 비디오 데이터셋(UCF101 및 Kinetics700)에 대해서는, 각 비디오 클립의 중간 프레임을 입력 이미지로 사용한다. STL-10과 UCF101은 각각 10개와 3개의 여러 사전 정의된 train/validation/test split을 가지며, 우리는 모든 split에 대한 평균을 보고한다. 각 데이터셋과 해당 평가 metric에 대한 세부 사항은 표9.
추가로, 우리는 Country211과 Rendered SST2라고 부르는 두 데이터셋을 만들었다. Country211 dataset은 시각 표현의 지리 위치 추정 능력을 평가하도록 설계되었다. 우리는 YFCC100m dataset을 필터링하여(Thomee et al.,2016)GPS 좌표가 있는 사진이 최소 300장 있는 211개 국가(ISO-3166 국가 코드를 가지는 것으로 정의됨)를 찾았고, 각 국가에 대해 학습용 200장과 테스트용 100장의 사진을 샘플링하여 211개 범주의 균형 잡힌 데이터셋을 구축했다.
Rendered SST2 dataset은 시각 표현의 광학 문자 인식 능력을 측정하도록 설계되었다. 이를 위해 우리는 Stanford Sentiment Treebank dataset의 문장들을 사용했고(Socher et al.,2013)그것들을 흰색 배경 위의 검은색 텍스트로, 448448 해상도의 이미지로 렌더링했다. 이 데이터셋의 두 예시 이미지는 Figure19.


| Dataset | 클래스 | Train 크기 | Test 크기 | 평가 metric |
| Food-101 | 102 | 75,750 | 25,250 | 정확도 |
| CIFAR-10 | 10 | 50,000 | 10,000 | 정확도 |
| CIFAR-100 | 100 | 50,000 | 10,000 | 정확도 |
| Birdsnap | 500 | 42,283 | 2,149 | 정확도 |
| SUN397 | 397 | 19,850 | 19,850 | 정확도 |
| Stanford Cars | 196 | 8,144 | 8,041 | 정확도 |
| FGVC Aircraft | 100 | 6,667 | 3,333 | 클래스별 평균 |
| Pascal VOC 2007 Classification | 20 | 5,011 | 4,952 | 11-point mAP |
| Describable Textures | 47 | 3,760 | 1,880 | 정확도 |
| Oxford-IIIT Pets | 37 | 3,680 | 3,669 | 클래스별 평균 |
| Caltech-101 | 102 | 3,060 | 6,085 | 클래스별 평균 |
| Oxford Flowers 102 | 102 | 2,040 | 6,149 | 클래스별 평균 |
| MNIST | 10 | 60,000 | 10,000 | 정확도 |
| Facial Emotion Recognition 2013 | 8 | 32,140 | 3,574 | 정확도 |
| STL-10 | 10 | 1000 | 8000 | 정확도 |
| EuroSAT | 10 | 10,000 | 5,000 | 정확도 |
| RESISC45 | 45 | 3,150 | 25,200 | 정확도 |
| GTSRB | 43 | 26,640 | 12,630 | 정확도 |
| KITTI | 4 | 6,770 | 711 | 정확도 |
| Country211 | 211 | 43,200 | 21,100 | 정확도 |
| PatchCamelyon | 2 | 294,912 | 32,768 | 정확도 |
| UCF101 | 101 | 9,537 | 1,794 | 정확도 |
| Kinetics700 | 700 | 494,801 | 31,669 | mean(top1, top5) |
| CLEVR Counts | 8 | 2,000 | 500 | 정확도 |
| Hateful Memes | 2 | 8,500 | 500 | ROC AUC |
| Rendered SST2 | 2 | 7,792 | 1,821 | 정확도 |
| ImageNet | 1000 | 1,281,167 | 50,000 | 정확도 |
A.2 모델
위에 나열된 데이터셋과 함께, 우리는 linear probe를 사용하여 다음 일련의 모델들을 평가한다.
LM RN50
이는 가장 작은 contrastive 모델에서와 같이 ResNet-50 architecture를 사용하면서, contrastive loss 대신 autoregressive loss를 사용하는 multimodal 모델이다. 이를 위해 CNN의 출력은 네 개의 토큰으로 투영되고, 그런 다음 텍스트 토큰을 autoregressive하게 예측하는 language model에 prefix로 공급된다. 학습 objective를 제외하고, 이 모델은 다른 CLIP 모델들과 동일한 데이터셋에서 동일한 epoch 수만큼 학습되었다.
CLIP-RN
다섯 개의 ResNet 기반 contrastive CLIP 모델이 포함된다. 논문에서 논의한 것처럼, 처음 두 모델은 ResNet-50과 ResNet-101을 따르며, 우리는 EfficientNet-style(Tan&Le,2019)scaling을 다음 세 모델에 사용하여, 모델 width, layer 수, input resolution을 동시에 scale하여 대략 4x, 16x, 64x computation을 갖는 모델을 얻는다.
CLIP-ViT
우리는 Vision Transformer를 사용하는 네 개의 CLIP 모델을 포함한다(Dosovitskiy et al.,2020)architecture를 image encoder로 사용한다. 우리는 224-by-224 pixel 이미지로 학습된 세 모델인 ViT-B/32, ViT-B/16, ViT-L/14와, 336-by-336 pixel input 이미지로 fine-tune된 ViT-L/14 모델을 포함한다.
EfficietNet
Instagram-pretrained ResNeXt
Big Transfer (BiT)
우리는 BiT-S와 BiT-M 모델을 사용한다(Kolesnikov et al.,2019), ImageNet-1k와 ImageNet-21k 데이터셋에서 학습되었다. BiT-L의 model weight는 공개적으로 이용 가능하지 않다.
Vision Transformer (ViT)
우리는 또한 네 개의 ViT를 포함한다(Dosovitskiy et al.,2020)ImageNet-21k 데이터셋에서 pretrained된 checkpoint, 즉 ViT-B/32, ViT-B/16, ViT-L/16, ViT-H/14이다. 우리는 JFT-300M 데이터셋에서 학습된 그들의 최고 성능 모델들이 공개적으로 이용 가능하지 않음을 언급한다.
SimCLRv2
SimCLRv2(Chen et al.,2020c)project는 다양한 설정에서 pre-trained 및 fine-tuned 모델을 공개했다. 우리는 selective kernels가 있는 일곱 개의 pretrain-only checkpoint를 사용한다.
BYOL
우리는 최근 공개된 BYOL의 model weight를 사용한다(Grill et al.,2020), 구체적으로 그들의 50x1 및 200x2 checkpoint이다.
Momentum Contrast (MoCo)
VirTex
우리는 VirTex의 pretrained 모델을 사용한다(Desai&Johnson,2020). 우리는 VirTex가 CLIP-AR과 유사한 model design을 갖지만 MSCOCO의 고품질 caption으로 이루어진 1000x 더 작은 데이터셋에서 학습된다는 점을 언급한다.
ResNet
우리는 다음에 의해 공개된 원래 ResNet checkpoint들을 추가한다(He et al.,2016b), 즉 ResNet-50, ResNet-101, ResNet152이다.
A.3 평가
우리는 제공된 어떤 classification layer도 무시하고, 각 모델의 끝에서 두 번째 layer에서 가져온 image feature를 사용한다. CLIP-ViT 모델의 경우, 우리는 embedding space로의 linear projection 이전 feature를 사용했으며, 이는 다음에 해당한다I_fFigure에서3. 우리는 scikit-learn의 L-BFGS 구현을 사용하여 logistic regression classifier를 학습하고, 최대 1,000 iteration으로 각 데이터셋에 해당하는 metric을 보고한다. 우리는 L2 regularization strength를 결정한다validation set에서 다음 사이의 범위에 대한 hyperparameter sweep을 사용하여그리고, 96개의 logarithmically spaced step으로. sweep에 필요한 compute를 절약하기 위해, 우리는 다음으로 시작하는 parametric binary search를 수행한다그리고 peak 주변의 interval을 반복적으로 절반으로 줄여 decade당 8 step의 resolution에 도달할 때까지 진행한다. hyperparameter sweep은 각 데이터셋의 validation split에서 수행된다. test split에 더해 validation split을 포함하는 데이터셋의 경우, 우리는 제공된 validation set을 사용하여 hyperparameter search를 수행하고, validation split을 제공하지 않거나 test data에 대한 label을 공개하지 않은 데이터셋의 경우, training dataset을 split하여 hyperparameter search를 수행한다. 최종 결과를 위해, 우리는 validation split을 다시 training split과 결합하고 사용되지 않은 split에서의 성능을 보고한다.
A.4 결과
개별 linear probe score는 Table에 제공된다10그리고 Figure에 plot되어 있다20. ViT-L/14 archiecture와 336-by-336 pixel 이미지를 사용하는 최고 성능 CLIP 모델은 27개 데이터셋 중 21개에서 state of the art를 달성했으며, 즉 각 데이터셋 최고 score 주변의 Clopper-Pearson 99.5% confidence interval에 포함되었다. 많은 데이터셋에서 CLIP은 다른 모델들보다 유의하게 더 잘 수행하여, image classification 기반의 전통적인 pre-training approach보다 natural language supervision의 이점을 보여준다. Section을 참조하라3.2linear probe 결과에 대한 더 많은 논의를 위해.
|
Food101 |
CIFAR10 |
CIFAR100 |
Birdsnap |
SUN397 |
Cars |
Aircraft |
VOC2007 |
DTD |
Pets |
Caltech101 |
Flowers |
MNIST |
FER2013 |
STL10⋆ |
EuroSAT |
RESISC45 |
GTSRB |
KITTI |
Country211 |
PCAM |
UCF101 |
Kinetics700 |
CLEVR |
HatefulMemes |
SST |
ImageNet |
|||
| LM RN50 | 81.3 | 82.8 | 61.7 | 44.2 | 69.6 | 74.9 | 44.9 | 85.5 | 71.5 | 82.8 | 85.5 | 91.1 | 96.6 | 60.1 | 95.3 | 93.4 | 84.0 | 73.8 | 70.2 | 19.0 | 82.9 | 76.4 | 51.9 | 51.2 | 65.2 | 76.8 | 65.2 | ||
| CLIP-RN | 50 | 86.4 | 88.7 | 70.3 | 56.4 | 73.3 | 78.3 | 49.1 | 87.1 | 76.4 | 88.2 | 89.6 | 96.1 | 98.3 | 64.2 | 96.6 | 95.2 | 87.5 | 82.4 | 70.2 | 25.3 | 82.7 | 81.6 | 57.2 | 53.6 | 65.7 | 72.6 | 73.3 | |
| 101 | 88.9 | 91.1 | 73.5 | 58.6 | 75.1 | 84.0 | 50.7 | 88.0 | 76.3 | 91.0 | 92.0 | 96.4 | 98.4 | 65.2 | 97.8 | 95.9 | 89.3 | 82.4 | 73.6 | 26.6 | 82.8 | 84.0 | 60.3 | 50.3 | 68.2 | 73.3 | 75.7 | ||
| 50x4 | 91.3 | 90.5 | 73.0 | 65.7 | 77.0 | 85.9 | 57.3 | 88.4 | 79.5 | 91.9 | 92.5 | 97.8 | 98.5 | 68.1 | 97.8 | 96.4 | 89.7 | 85.5 | 59.4 | 30.3 | 83.0 | 85.7 | 62.6 | 52.5 | 68.0 | 76.6 | 78.2 | ||
| 50x16 | 93.3 | 92.2 | 74.9 | 72.8 | 79.2 | 88.7 | 62.7 | 89.0 | 79.1 | 93.5 | 93.7 | 98.3 | 98.9 | 68.7 | 98.6 | 97.0 | 91.4 | 89.0 | 69.2 | 34.8 | 83.5 | 88.0 | 66.3 | 53.8 | 71.1 | 80.0 | 81.5 | ||
| 50x64 | 94.8 | 94.1 | 78.6 | 77.2 | 81.1 | 90.5 | 67.7 | 88.9 | 82.0 | 94.5 | 95.4 | 98.9 | 98.9 | 71.3 | 99.1 | 97.1 | 92.8 | 90.2 | 69.2 | 40.7 | 83.7 | 89.5 | 69.1 | 55.0 | 75.0 | 81.2 | 83.6 | ||
| CLIP-ViT | B/32 | 88.8 | 95.1 | 80.5 | 58.5 | 76.6 | 81.8 | 52.0 | 87.7 | 76.5 | 90.0 | 93.0 | 96.9 | 99.0 | 69.2 | 98.3 | 97.0 | 90.5 | 85.3 | 66.2 | 27.8 | 83.9 | 85.5 | 61.7 | 52.1 | 66.7 | 70.8 | 76.1 | |
| B/16 | 92.8 | 96.2 | 83.1 | 67.8 | 78.4 | 86.7 | 59.5 | 89.2 | 79.2 | 93.1 | 94.7 | 98.1 | 99.0 | 69.5 | 99.0 | 97.1 | 92.7 | 86.6 | 67.8 | 33.3 | 83.5 | 88.4 | 66.1 | 57.1 | 70.3 | 75.5 | 80.2 | ||
| L/14 | 95.2 | 98.0 | 87.5 | 77.0 | 81.8 | 90.9 | 69.4 | 89.6 | 82.1 | 95.1 | 96.5 | 99.2 | 99.2 | 72.2 | 99.7 | 98.2 | 94.1 | 92.5 | 64.7 | 42.9 | 85.8 | 91.5 | 72.0 | 57.8 | 76.2 | 80.8 | 83.9 | ||
| L/14-336px | 95.9 | 97.9 | 87.4 | 79.9 | 82.2 | 91.5 | 71.6 | 89.9 | 83.0 | 95.1 | 96.0 | 99.2 | 99.2 | 72.9 | 99.7 | 98.1 | 94.9 | 92.4 | 69.2 | 46.4 | 85.6 | 92.0 | 73.0 | 60.3 | 77.3 | 80.5 | 85.4 | ||
| EfficientNet | B0 | 74.3 | 92.5 | 76.5 | 59.7 | 62.0 | 62.5 | 55.7 | 84.4 | 71.2 | 93.0 | 93.3 | 91.7 | 98.2 | 57.2 | 97.1 | 97.3 | 85.5 | 80.0 | 73.8 | 12.4 | 83.1 | 74.4 | 47.6 | 47.9 | 55.7 | 53.4 | 76.9 | |
| B1 | 74.2 | 93.2 | 77.2 | 61.3 | 62.6 | 62.5 | 56.1 | 84.7 | 74.2 | 93.4 | 93.6 | 92.4 | 98.3 | 57.0 | 97.5 | 96.8 | 84.5 | 75.9 | 75.5 | 12.5 | 82.7 | 74.7 | 48.5 | 44.3 | 54.5 | 54.4 | 78.6 | ||
| B2 | 75.8 | 93.6 | 77.9 | 64.4 | 64.0 | 63.2 | 57.0 | 85.3 | 73.5 | 93.9 | 93.5 | 92.9 | 98.5 | 56.6 | 97.7 | 96.9 | 84.4 | 76.4 | 73.1 | 12.6 | 84.3 | 75.1 | 49.4 | 42.6 | 55.4 | 55.2 | 79.7 | ||
| B3 | 77.4 | 94.0 | 78.0 | 66.5 | 64.4 | 66.0 | 59.3 | 85.8 | 73.1 | 94.1 | 93.7 | 93.3 | 98.5 | 57.1 | 98.2 | 97.3 | 85.0 | 75.8 | 76.1 | 13.4 | 83.3 | 78.1 | 50.9 | 45.1 | 53.8 | 54.8 | 81.0 | ||
| B4 | 79.7 | 94.1 | 78.7 | 70.1 | 65.4 | 66.4 | 60.4 | 86.5 | 73.4 | 94.7 | 93.5 | 93.2 | 98.8 | 57.9 | 98.6 | 96.8 | 85.0 | 78.3 | 72.3 | 13.9 | 83.1 | 79.1 | 52.5 | 46.5 | 54.4 | 55.4 | 82.9 | ||
| B5 | 81.5 | 93.6 | 77.9 | 72.4 | 67.1 | 72.7 | 68.9 | 86.7 | 73.9 | 95.0 | 94.7 | 94.5 | 98.4 | 58.5 | 98.7 | 96.8 | 86.0 | 78.5 | 69.6 | 14.9 | 84.7 | 80.9 | 54.5 | 46.6 | 53.3 | 56.3 | 83.7 | ||
| B6 | 82.4 | 94.0 | 78.0 | 73.5 | 65.8 | 71.1 | 68.2 | 87.6 | 73.9 | 95.0 | 94.1 | 93.7 | 98.4 | 60.2 | 98.7 | 96.8 | 85.4 | 78.1 | 72.7 | 15.3 | 84.2 | 80.0 | 54.1 | 51.1 | 53.3 | 57.0 | 84.0 | ||
| B7 | 84.5 | 94.9 | 80.1 | 74.7 | 69.0 | 77.1 | 72.3 | 87.2 | 76.8 | 95.2 | 94.7 | 95.9 | 98.6 | 61.3 | 99.1 | 96.3 | 86.8 | 80.8 | 75.8 | 16.4 | 85.2 | 81.9 | 56.8 | 51.9 | 54.4 | 57.8 | 84.8 | ||
| B8 | 84.5 | 95.0 | 80.7 | 75.2 | 69.6 | 76.8 | 71.5 | 87.4 | 77.1 | 94.9 | 95.2 | 96.3 | 98.6 | 61.4 | 99.2 | 97.0 | 87.4 | 80.4 | 70.9 | 17.4 | 85.2 | 82.4 | 57.7 | 51.4 | 51.7 | 55.8 | 85.3 | ||
| EfficientNet Noisy Student | B0 | 78.1 | 94.0 | 78.6 | 63.5 | 65.5 | 57.2 | 53.7 | 85.6 | 75.6 | 93.8 | 93.1 | 94.5 | 98.1 | 55.6 | 98.2 | 97.0 | 84.3 | 74.0 | 71.6 | 14.0 | 83.1 | 76.7 | 51.7 | 47.3 | 55.7 | 55.0 | 78.5 | |
| B1 | 80.4 | 95.1 | 80.2 | 66.6 | 67.6 | 59.6 | 53.7 | 86.2 | 77.0 | 94.6 | 94.4 | 95.1 | 98.0 | 56.1 | 98.6 | 96.9 | 84.3 | 73.1 | 67.1 | 14.5 | 83.9 | 79.9 | 54.5 | 46.1 | 54.3 | 54.9 | 81.1 | ||
| B2 | 80.9 | 95.3 | 81.3 | 67.6 | 67.9 | 60.9 | 55.2 | 86.3 | 77.7 | 95.0 | 94.7 | 94.4 | 98.0 | 55.5 | 98.8 | 97.3 | 84.6 | 71.7 | 70.0 | 14.6 | 82.9 | 80.1 | 55.1 | 46.1 | 54.1 | 55.3 | 82.2 | ||
| B3 | 82.6 | 95.9 | 82.1 | 68.6 | 68.8 | 60.6 | 55.4 | 86.5 | 77.2 | 95.0 | 94.8 | 95.2 | 98.1 | 56.0 | 99.1 | 96.5 | 85.0 | 70.5 | 69.5 | 15.1 | 83.1 | 81.8 | 56.8 | 45.1 | 55.7 | 52.0 | 83.8 | ||
| B4 | 85.2 | 95.6 | 81.0 | 72.5 | 69.7 | 56.1 | 52.6 | 87.0 | 78.7 | 94.8 | 95.2 | 95.3 | 98.2 | 56.0 | 99.3 | 95.3 | 84.8 | 61.9 | 64.8 | 16.0 | 82.8 | 83.4 | 59.8 | 43.2 | 55.3 | 53.0 | 85.4 | ||
| B5 | 87.6 | 96.3 | 82.4 | 75.3 | 71.6 | 64.7 | 64.8 | 87.8 | 79.6 | 95.5 | 95.6 | 96.6 | 98.8 | 60.9 | 99.4 | 96.1 | 87.0 | 68.5 | 73.7 | 16.4 | 83.5 | 86.4 | 61.6 | 46.3 | 53.4 | 55.8 | 85.8 | ||
| B6 | 87.3 | 97.0 | 83.9 | 75.8 | 71.4 | 67.6 | 65.6 | 87.3 | 78.5 | 95.2 | 96.4 | 97.2 | 98.6 | 61.9 | 99.5 | 96.6 | 86.1 | 70.7 | 72.4 | 17.6 | 84.2 | 85.5 | 61.0 | 49.6 | 54.6 | 55.7 | 86.4 | ||
| B7 | 88.4 | 96.0 | 82.0 | 76.9 | 72.6 | 72.2 | 71.2 | 88.1 | 80.5 | 95.5 | 95.5 | 96.6 | 98.5 | 62.7 | 99.4 | 96.2 | 88.5 | 73.4 | 73.0 | 18.5 | 83.8 | 86.6 | 63.2 | 50.5 | 57.2 | 56.7 | 87.0 | ||
| L2-475 | 91.6 | 99.0 | 91.0 | 74.8 | 76.4 | 75.1 | 66.8 | 89.5 | 81.9 | 95.6 | 96.5 | 97.7 | 98.9 | 67.5 | 99.6 | 97.0 | 89.5 | 73.4 | 68.9 | 22.2 | 86.3 | 89.4 | 68.2 | 58.3 | 58.6 | 55.2 | 88.3 | ||
| L2-800 | 92.0 | 98.7 | 89.0 | 78.5 | 75.7 | 75.5 | 68.4 | 89.4 | 82.5 | 95.6 | 94.7 | 97.9 | 98.5 | 68.4 | 99.7 | 97.2 | 89.9 | 77.7 | 66.9 | 23.7 | 86.8 | 88.9 | 66.7 | 62.7 | 58.4 | 56.9 | 88.4 | ||
| 32x8d | 84.8 | 95.9 | 80.9 | 63.8 | 69.0 | 74.2 | 56.0 | 88.0 | 75.4 | 95.4 | 93.9 | 91.7 | 97.4 | 60.7 | 99.1 | 95.7 | 82.1 | 72.3 | 69.2 | 16.7 | 82.3 | 80.1 | 56.8 | 42.2 | 53.3 | 55.2 | 83.3 | ||
| 32x16d | 85.7 | 96.5 | 80.9 | 64.8 | 70.5 | 77.5 | 56.7 | 87.9 | 76.2 | 95.6 | 94.9 | 92.5 | 97.4 | 61.6 | 99.3 | 95.5 | 82.8 | 73.8 | 66.1 | 17.5 | 83.4 | 81.1 | 58.2 | 41.3 | 54.2 | 56.1 | 84.4 | ||
| 32x32d | 86.7 | 96.8 | 82.7 | 67.1 | 71.5 | 77.5 | 55.4 | 88.3 | 78.5 | 95.8 | 95.3 | 94.4 | 97.9 | 62.4 | 99.3 | 95.7 | 85.4 | 71.2 | 66.8 | 18.0 | 83.7 | 82.1 | 58.8 | 39.7 | 55.3 | 56.7 | 85.0 | ||
| 32x48d | 86.9 | 96.8 | 83.4 | 65.9 | 72.2 | 76.6 | 53.2 | 88.0 | 77.2 | 95.5 | 95.8 | 93.6 | 98.1 | 63.7 | 99.4 | 95.3 | 85.4 | 73.0 | 67.2 | 18.5 | 82.7 | 82.8 | 59.2 | 41.3 | 55.5 | 56.7 | 85.2 | ||
| FixRes-v1 | 88.5 | 95.7 | 81.1 | 67.4 | 72.9 | 80.5 | 57.6 | 88.0 | 77.9 | 95.8 | 96.1 | 94.5 | 97.9 | 62.2 | 99.4 | 96.2 | 86.6 | 76.5 | 64.8 | 19.3 | 82.5 | 83.4 | 59.8 | 43.5 | 56.6 | 59.0 | 86.0 | ||
| FixRes-v2 | 88.5 | 95.7 | 81.1 | 67.3 | 72.9 | 80.7 | 57.5 | 88.0 | 77.9 | 95.0 | 96.0 | 94.5 | 98.0 | 62.1 | 99.4 | 96.5 | 86.6 | 76.3 | 64.8 | 19.5 | 82.3 | 83.5 | 59.8 | 44.2 | 56.6 | 59.0 | 86.0 | ||
| BiT-S | R50x1 | 72.5 | 91.7 | 74.8 | 57.7 | 61.1 | 53.5 | 52.5 | 83.7 | 72.4 | 92.3 | 91.2 | 92.0 | 98.4 | 56.1 | 96.4 | 97.4 | 85.0 | 70.0 | 66.0 | 12.5 | 83.0 | 72.3 | 47.5 | 48.3 | 54.1 | 55.3 | 75.2 | |
| R50x3 | 75.1 | 93.7 | 79.0 | 61.1 | 63.7 | 55.2 | 54.1 | 84.8 | 74.6 | 92.5 | 91.6 | 92.8 | 98.8 | 58.7 | 97.0 | 97.8 | 86.4 | 73.1 | 73.8 | 14.0 | 84.2 | 76.4 | 50.0 | 49.2 | 54.7 | 54.2 | 77.2 | ||
| R101x1 | 73.5 | 92.8 | 77.4 | 58.4 | 61.3 | 54.0 | 52.4 | 84.4 | 73.5 | 92.5 | 91.8 | 90.6 | 98.3 | 56.5 | 96.8 | 97.3 | 84.6 | 69.4 | 68.9 | 12.6 | 82.0 | 73.5 | 48.6 | 45.4 | 52.6 | 55.5 | 76.0 | ||
| R101x3 | 74.7 | 93.9 | 79.8 | 57.8 | 62.9 | 54.7 | 53.3 | 84.7 | 75.5 | 92.3 | 91.2 | 92.6 | 98.8 | 59.7 | 97.3 | 98.0 | 85.5 | 71.8 | 60.2 | 14.1 | 83.1 | 75.9 | 50.4 | 49.7 | 54.1 | 54.6 | 77.4 | ||
| R152x2 | 74.9 | 94.3 | 79.7 | 58.7 | 62.7 | 55.9 | 53.6 | 85.3 | 74.9 | 93.0 | 92.0 | 91.7 | 98.6 | 58.3 | 97.1 | 97.8 | 86.2 | 71.8 | 71.6 | 13.9 | 84.1 | 76.2 | 49.9 | 48.2 | 53.8 | 55.9 | 77.1 | ||
| R152x4 | 74.7 | 94.2 | 79.2 | 57.8 | 62.9 | 51.2 | 50.8 | 85.4 | 75.4 | 93.1 | 91.2 | 91.4 | 98.9 | 61.4 | 97.2 | 98.0 | 85.5 | 72.8 | 67.9 | 14.9 | 83.1 | 76.0 | 50.3 | 42.9 | 53.6 | 56.0 | 78.5 | ||
| BiT-M | R50x1 | 83.3 | 94.9 | 82.2 | 70.9 | 69.9 | 59.0 | 55.6 | 86.8 | 77.3 | 91.5 | 93.9 | 99.4 | 98.0 | 60.6 | 98.4 | 97.5 | 87.4 | 68.6 | 68.2 | 16.6 | 82.5 | 79.4 | 53.2 | 49.4 | 54.5 | 53.4 | 76.7 | |
| R50x3 | 86.9 | 96.7 | 86.2 | 75.7 | 74.6 | 60.6 | 54.2 | 87.7 | 78.5 | 93.2 | 95.3 | 99.4 | 98.6 | 64.6 | 99.3 | 98.0 | 88.1 | 69.9 | 59.6 | 19.6 | 83.4 | 83.5 | 57.8 | 51.3 | 55.8 | 55.6 | 80.7 | ||
| R101x1 | 85.5 | 95.7 | 84.4 | 73.0 | 72.5 | 59.8 | 55.0 | 87.3 | 78.1 | 92.2 | 95.0 | 99.5 | 98.1 | 62.5 | 99.0 | 97.6 | 87.8 | 68.7 | 67.7 | 18.0 | 84.0 | 82.3 | 55.9 | 53.4 | 54.8 | 53.1 | 79.4 | ||
| R101x3 | 87.2 | 97.4 | 87.5 | 72.4 | 75.0 | 57.4 | 47.4 | 87.5 | 79.6 | 93.2 | 95.4 | 99.6 | 98.6 | 64.3 | 99.4 | 98.2 | 87.7 | 68.8 | 64.1 | 20.7 | 80.4 | 84.0 | 58.7 | 52.6 | 54.9 | 54.3 | 81.2 | ||
| R152x2 | 88.0 | 97.5 | 87.8 | 75.8 | 75.9 | 61.5 | 55.3 | 88.1 | 79.8 | 93.6 | 95.9 | 99.5 | 98.5 | 64.3 | 99.5 | 97.9 | 89.0 | 70.0 | 70.3 | 20.7 | 82.6 | 85.5 | 59.6 | 50.8 | 54.9 | 55.1 | 81.9 | ||
| R152x4 | 87.2 | 97.6 | 88.2 | 72.4 | 75.0 | 49.1 | 43.4 | 87.1 | 79.9 | 92.4 | 95.4 | 99.3 | 98.5 | 65.7 | 99.5 | 97.8 | 87.7 | 68.2 | 57.1 | 20.6 | 80.4 | 84.6 | 59.0 | 49.7 | 57.2 | 55.1 | 81.5 | ||
| ViT | B/32 | 81.8 | 96.7 | 86.3 | 65.2 | 70.7 | 49.1 | 42.7 | 85.3 | 73.1 | 90.4 | 94.5 | 98.7 | 97.8 | 59.0 | 99.0 | 96.3 | 83.0 | 68.1 | 65.1 | 15.7 | 82.6 | 79.1 | 51.7 | 38.9 | 57.1 | 54.6 | 76.6 | |
| B/16 | 86.7 | 96.9 | 86.4 | 74.0 | 74.2 | 54.7 | 46.0 | 86.7 | 74.3 | 92.7 | 94.1 | 99.2 | 97.4 | 61.3 | 99.5 | 96.4 | 84.5 | 63.1 | 61.5 | 17.5 | 85.4 | 82.7 | 56.6 | 40.0 | 57.0 | 56.1 | 80.9 | ||
| L/16 | 87.4 | 97.9 | 89.0 | 76.5 | 74.9 | 62.5 | 52.2 | 86.1 | 75.0 | 92.9 | 94.7 | 99.3 | 98.0 | 64.0 | 99.6 | 96.5 | 85.7 | 70.4 | 58.8 | 17.7 | 85.7 | 84.1 | 58.0 | 38.4 | 58.4 | 52.8 | 81.9 | ||
| H/14 | 83.4 | 95.8 | 84.5 | 70.2 | 69.2 | 62.3 | 54.8 | 84.7 | 75.4 | 91.7 | 93.7 | 98.9 | 98.5 | 62.4 | 98.4 | 97.3 | 87.0 | 73.9 | 63.4 | 15.4 | 87.0 | 79.4 | 52.1 | 41.1 | 55.9 | 54.1 | 75.9 | ||
| SimCLRv2 | R50x1 | 76.4 | 93.2 | 77.9 | 48.6 | 64.1 | 56.3 | 51.7 | 84.4 | 77.0 | 88.3 | 91.8 | 92.9 | 97.6 | 59.7 | 96.7 | 97.5 | 85.8 | 71.1 | 69.1 | 15.8 | 84.8 | 78.4 | 51.0 | 56.2 | 53.9 | 53.8 | 73.8 | |
| R50x3 | 81.0 | 95.6 | 82.4 | 56.5 | 67.0 | 65.6 | 61.1 | 85.9 | 78.8 | 90.9 | 94.1 | 95.4 | 98.7 | 62.6 | 98.2 | 97.9 | 88.2 | 78.2 | 74.7 | 17.6 | 85.4 | 82.6 | 54.6 | 55.4 | 54.2 | 55.2 | 77.3 | ||
| R101x1 | 77.9 | 94.8 | 79.9 | 51.9 | 65.2 | 57.1 | 52.0 | 85.4 | 77.2 | 90.0 | 91.6 | 92.7 | 97.2 | 59.4 | 97.6 | 96.8 | 84.6 | 65.7 | 70.6 | 16.1 | 84.3 | 78.8 | 52.4 | 53.6 | 55.1 | 55.7 | 76.1 | ||
| R101x3 | 82.2 | 96.4 | 83.4 | 57.5 | 68.2 | 64.6 | 60.0 | 86.2 | 78.9 | 91.8 | 95.0 | 95.4 | 98.4 | 63.0 | 98.5 | 97.9 | 88.0 | 77.5 | 69.1 | 18.3 | 85.5 | 82.9 | 55.9 | 52.2 | 54.5 | 56.3 | 78.8 | ||
| R152x1 | 78.6 | 95.0 | 79.9 | 50.3 | 65.6 | 55.6 | 52.2 | 85.8 | 77.3 | 90.1 | 92.5 | 91.8 | 97.6 | 59.8 | 98.1 | 96.6 | 84.3 | 64.8 | 70.3 | 16.6 | 83.9 | 79.4 | 53.1 | 57.2 | 55.8 | 54.8 | 76.9 | ||
| R152x2 | 82.3 | 96.7 | 83.9 | 58.1 | 68.5 | 64.9 | 58.7 | 86.6 | 79.1 | 92.2 | 94.1 | 96.0 | 98.2 | 64.1 | 98.5 | 98.0 | 88.1 | 77.0 | 69.8 | 18.4 | 85.3 | 82.7 | 56.2 | 53.6 | 56.0 | 56.5 | 79.2 | ||
| R152x3 | 83.6 | 96.8 | 84.5 | 60.3 | 69.1 | 68.5 | 63.1 | 86.7 | 80.5 | 92.6 | 94.9 | 96.3 | 98.7 | 65.4 | 98.8 | 98.1 | 89.5 | 78.4 | 68.5 | 19.4 | 85.2 | 83.5 | 57.0 | 54.4 | 54.6 | 54.2 | 80.0 | ||
| BYOL | 50x1 | 74.0 | 93.6 | 79.1 | 47.6 | 63.7 | 61.6 | 62.3 | 82.6 | 77.0 | 88.3 | 93.7 | 94.3 | 98.7 | 58.8 | 96.4 | 97.6 | 88.2 | 80.1 | 71.4 | 14.1 | 84.8 | 77.3 | 49.3 | 56.1 | 53.8 | 54.4 | 73.3 | |
| 200x2 | 78.5 | 96.2 | 83.3 | 53.4 | 68.5 | 61.7 | 55.4 | 86.6 | 77.4 | 91.9 | 95.5 | 93.9 | 98.7 | 62.6 | 98.6 | 97.7 | 87.4 | 77.1 | 76.4 | 16.4 | 84.0 | 82.6 | 55.1 | 54.1 | 52.5 | 52.4 | 79.2 | ||
| MoCo | v1 | 65.9 | 85.0 | 63.1 | 27.5 | 52.6 | 35.9 | 43.5 | 75.7 | 70.0 | 70.4 | 78.1 | 85.4 | 97.6 | 54.3 | 85.6 | 97.1 | 82.9 | 62.6 | 60.2 | 12.6 | 85.7 | 64.2 | 40.7 | 54.7 | 55.6 | 53.5 | 57.2 | |
| v2 | 72.2 | 93.4 | 76.3 | 39.6 | 60.2 | 48.3 | 51.1 | 82.6 | 75.1 | 84.4 | 89.9 | 90.7 | 98.4 | 58.3 | 95.7 | 97.2 | 85.4 | 75.7 | 75.4 | 13.2 | 85.6 | 72.7 | 47.8 | 56.9 | 53.9 | 53.8 | 69.1 | ||
| VirTex | 57.9 | 83.9 | 57.5 | 17.0 | 49.8 | 22.4 | 34.5 | 83.8 | 58.2 | 53.6 | 70.6 | 74.7 | 98.1 | 56.5 | 86.7 | 94.8 | 74.1 | 69.5 | 71.3 | 8.7 | 83.1 | 61.5 | 39.9 | 45.5 | 53.5 | 55.8 | 50.7 | ||
| ResNet | 50 | 71.3 | 91.8 | 74.5 | 52.7 | 60.5 | 49.9 | 48.5 | 83.8 | 72.3 | 92.4 | 90.8 | 90.8 | 98.3 | 54.9 | 96.4 | 96.7 | 83.6 | 70.6 | 67.1 | 11.7 | 82.5 | 71.2 | 46.8 | 43.0 | 56.5 | 55.5 | 74.3 | |
| 101 | 72.7 | 93.0 | 77.2 | 53.7 | 60.8 | 50.1 | 47.0 | 84.4 | 71.6 | 92.3 | 91.9 | 90.4 | 98.5 | 56.6 | 97.0 | 97.1 | 83.4 | 72.5 | 63.6 | 11.9 | 83.3 | 72.7 | 48.3 | 43.2 | 53.0 | 54.7 | 75.8 | ||
| 152 | 73.7 | 93.5 | 78.0 | 55.1 | 61.6 | 52.8 | 48.4 | 84.5 | 71.9 | 93.0 | 92.1 | 89.6 | 98.2 | 57.0 | 97.6 | 97.0 | 83.1 | 70.1 | 70.2 | 12.3 | 82.9 | 75.3 | 49.2 | 42.4 | 53.2 | 53.9 | 77.1 |
⋆우리는 CUDA 관련 bug를 수정한 후 이 논문의 이전 버전에서 STL10 score를 업데이트했다.
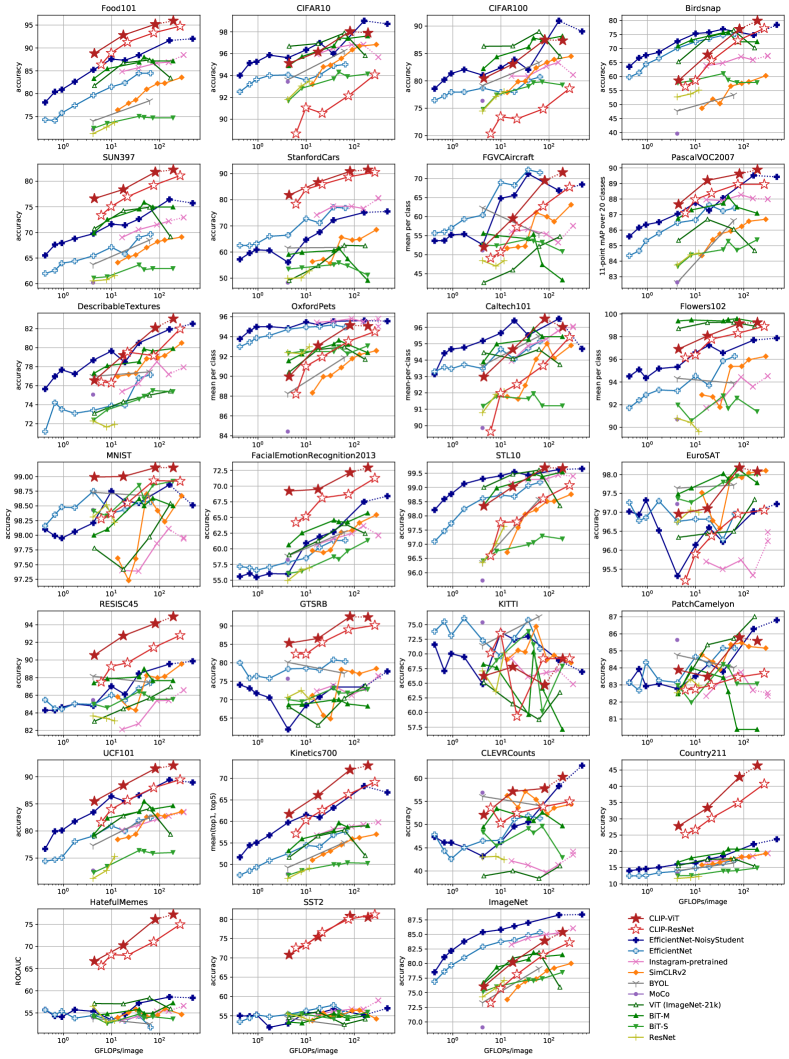
|
Food101 |
CIFAR10 |
CIFAR100 |
Birdsnap |
SUN397 |
Stanford Cars |
FGVC Aircraft |
VOC2007 |
DTD |
Oxford Pets |
Caltech101 |
Flowers102 |
MNIST |
FER2013 |
STL10 |
EuroSAT |
RESISC45 |
GTSRB |
KITTI |
Country211 |
PCam |
UCF101 |
Kinetics700 |
CLEVR |
HatefulMemes |
Rendered SST2 |
ImageNet |
|||
| CLIP-ResNet | RN50 | 81.1 | 75.6 | 41.6 | 32.6 | 59.6 | 55.8 | 19.3 | 82.1 | 41.7 | 85.4 | 82.1 | 65.9 | 66.6 | 42.2 | 94.3 | 41.1 | 54.2 | 35.2 | 42.2 | 16.1 | 57.6 | 63.6 | 43.5 | 20.3 | 59.7 | 56.9 | 59.6 | |
| RN101 | 83.9 | 81.0 | 49.0 | 37.2 | 59.9 | 62.3 | 19.5 | 82.4 | 43.9 | 86.2 | 85.1 | 65.7 | 59.3 | 45.6 | 96.7 | 33.1 | 58.5 | 38.3 | 33.3 | 16.9 | 55.2 | 62.2 | 46.7 | 28.1 | 61.1 | 64.2 | 62.2 | ||
| RN50x4 | 86.8 | 79.2 | 48.9 | 41.6 | 62.7 | 67.9 | 24.6 | 83.0 | 49.3 | 88.1 | 86.0 | 68.0 | 75.2 | 51.1 | 96.4 | 35.0 | 59.2 | 35.7 | 26.0 | 20.2 | 57.5 | 65.5 | 49.0 | 17.0 | 58.3 | 66.6 | 65.8 | ||
| RN50x16 | 90.5 | 82.2 | 54.2 | 45.9 | 65.0 | 72.3 | 30.3 | 82.9 | 52.8 | 89.7 | 87.6 | 71.9 | 80.0 | 56.0 | 97.8 | 40.3 | 64.4 | 39.6 | 33.9 | 24.0 | 62.5 | 68.7 | 53.4 | 17.6 | 58.9 | 67.6 | 70.5 | ||
| RN50x64 | 91.8 | 86.8 | 61.3 | 48.9 | 66.9 | 76.0 | 35.6 | 83.8 | 53.4 | 93.4 | 90.6 | 77.3 | 90.8 | 61.0 | 98.3 | 59.4 | 69.7 | 47.9 | 33.2 | 29.6 | 65.0 | 74.1 | 56.8 | 27.5 | 62.1 | 70.7 | 73.6 | ||
| CLIP-ViT | B/32 | 84.4 | 91.3 | 65.1 | 37.8 | 63.2 | 59.4 | 21.2 | 83.1 | 44.5 | 87.0 | 87.9 | 66.7 | 51.9 | 47.3 | 97.2 | 49.4 | 60.3 | 32.2 | 39.4 | 17.8 | 58.4 | 64.5 | 47.8 | 24.8 | 57.6 | 59.6 | 63.2 | |
| B/16 | 89.2 | 91.6 | 68.7 | 39.1 | 65.2 | 65.6 | 27.1 | 83.9 | 46.0 | 88.9 | 89.3 | 70.4 | 56.0 | 52.7 | 98.2 | 54.1 | 65.5 | 43.3 | 44.0 | 23.3 | 48.1 | 69.8 | 52.4 | 23.4 | 61.7 | 59.8 | 68.6 | ||
| L/14 | 92.9 | 96.2 | 77.9 | 48.3 | 67.7 | 77.3 | 36.1 | 84.1 | 55.3 | 93.5 | 92.6 | 78.7 | 87.2 | 57.5 | 99.3 | 59.9 | 71.6 | 50.3 | 23.1 | 32.7 | 58.8 | 76.2 | 60.3 | 24.3 | 63.3 | 64.0 | 75.3 | ||
| L/14-336px | 93.8 | 95.7 | 77.5 | 49.5 | 68.4 | 78.8 | 37.2 | 84.3 | 55.7 | 93.5 | 92.8 | 78.3 | 88.3 | 57.7 | 99.4 | 59.6 | 71.7 | 52.3 | 21.9 | 34.9 | 63.0 | 76.9 | 61.3 | 24.8 | 63.3 | 67.9 | 76.2 |
![[Uncaptioned image]](https://ar5iv.labs.arxiv.org/html/2103.00020/assets/x23.png)
Appendix BZero-Shot 예측
Appendix C중복 감지기
중복 감지와 분석에 대한 우리의 초기 시도는 모델이 학습한 임베딩 공간에서 nearest neighbors를 사용했다. 모델 자체의 유사성 개념을 사용하는 것은 직관적이지만, 우리는 문제들을 마주쳤다. 우리는 모델의 feature space가 의미적 유사성 쪽으로 매우 강하게 가중되어 있음을 발견했다. 유사하게 묘사될 별개의 객체들(축구공, 같은 종의 꽃 등…)이 거의 완벽한 유사성을 가져 많은 false positives가 발생했다. 또한 모델이 특정 종류의 near-duplicates에 높은 유사도 점수를 부여하는 데 꽤 서툴다는 것을 관찰했다. 서로 다른 resizing 알고리즘(nearest neighbor vs bi-linear)으로 pre-processed된 고주파 텍스처(털 또는 줄무늬 패턴 같은)를 가진 이미지들이 놀라울 정도로 낮은 유사성을 가질 수 있음을 반복적으로 알아차렸다. 이는 많은 false negatives를 초래했다.
우리는 이 문제를 해결하기 위해 자체 near-duplicate detector를 만들었다. 우리는 다양한 일반적인 이미지 조작을 결합한 synthetic data augmentation pipeline을 만들었다. augmentation pipeline은 random cropping과 zooming, aspect ratio distortion, 다양한 해상도로의 downsizing과 upscaling, minor rotations, jpeg compression, 그리고 HSV color jitter를 결합한다. 이 pipeline은 또한 모든 관련 단계에 대해 서로 다른 interpolation algorithms 중에서 무작위로 선택한다. 그런 다음 우리는 한 이미지와 그 변환된 변형의 유사성을 최대화하면서 training batch의 다른 모든 이미지와의 유사성을 최소화하도록 모델을 훈련했다. 우리는 CLIP과 동일한 n-pair / InfoNCE loss를 사용했지만, 고정 temperature 0.07을 사용했다.
우리는 모델 아키텍처로 ResNet-50을 선택했다. 우리는 base ResNet-50을(Zhang,2019)의 anti-alias 개선으로 수정했고, weight norm(Salimans&Kingma,2016)을 batch norm(Ioffe&Szegedy,2015)대신 사용하여 batch statistics를 통해 duplicates에 대한 정보가 누출되는 것을 피했다 - 이는 이전에(Henaff,2020)에서 지적된 문제이다. 우리는 또한 GELU activation function(Hendrycks&Gimpel,2016)이 이 작업에서 더 잘 수행함을 발견했다. 우리는 pre-training dataset에서 샘플링한 약 30 million images에 대해 총 batch size 1,712로 모델을 훈련했다. 훈련이 끝날 때 그것은 proxy training task에서 거의 100% accuracy를 달성한다.
Appendix DYFCC100M에 대한 Dataset Ablation
| Linear Classifier | Zero Shot | |||||
| Dataset | YFCC | WIT | YFCC | WIT | ||
| Birdsnap | 47.4 | 35.3 | 12.1 | 19.9 | 4.5 | 15.4 |
| Country211 | 23.1 | 17.3 | 5.8 | 5.2 | 5.3 | 0.1 |
| Flowers102 | 94.4 | 89.8 | 4.6 | 48.6 | 21.7 | 26.9 |
| GTSRB | 66.8 | 72.5 | 5.7 | 6.9 | 7.0 | 0.1 |
| UCF101 | 69.2 | 74.9 | 5.7 | 22.9 | 32.0 | 9.1 |
| Stanford Cars | 31.4 | 50.3 | 18.9 | 3.8 | 10.9 | 7.1 |
| ImageNet | 62.0 | 60.8 | 31.3 | 27.6 | 3.7 | |
| Dataset Average | 65.5 | 66.6 | 1.1 | 29.6 | 30.0 | 0.4 |
| Dataset “Wins” | 10 | 15 | 5 | 19 | 18 | 1 |
우리의 custom dataset이 CLIP의 성능에 중요한지 연구하기 위해, 우리는 YFCC100M dataset의 filtered subset(자세한 내용은 Section2.2)에서 모델을 훈련하고 그 성능을 동일한 크기의 WIT subset에서 훈련한 같은 모델과 비교했다. 우리는 각 모델을 32 epochs 동안 훈련하며, 이 지점에서 transfer performance는 overfitting 때문에 plateau에 도달하기 시작한다. 결과는 Table12. 우리의 전체 eval suite 전반에서, YFCC와 WIT는 zero-shot 및 linear probe 설정 모두에서 평균적으로 유사하게 수행한다. 그러나 특정 fine-grained classification 데이터셋에서의 성능은 크게 달라질 수 있다 - 때로는 10%를 넘기도 한다. 우리의 추측은 이러한 성능 차이가 각 pre-training dataset에서 관련 데이터의 상대적 밀도를 반영한다는 것이다. 예를 들어, 많은 새와 꽃 사진(사진가들에게 흔한 피사체)을 포함할 수 있는 YFCC100M에서 pre-training하면 Birdsnap과 Flowers102에서 더 나은 성능이 나오며, WIT에서 pre-training하면 더 나은 자동차 및 반려동물 classifiers가 나온다(이는 우리 dataset에서 흔해 보인다).
전반적으로, 이러한 결과는 우리의 접근법이 적절히 필터링된 paired (text, image) data의 어떤 collection이든 사용할 수 있음을 시사하므로 고무적이다. 이는 medical imaging이라는 비교적 다른 domain에서 동일한 contrastive pre-training objective를 사용해 긍정적 결과를 보고한 최근 연구와 닮아 있다(Zhang et al.,2020). 또한 이는 YFCC100M보다 그들의 JFT300M dataset을 사용할 때 약간의 개선만 보고한 noisy student self-training의 findings와도 유사하다(Xie et al.,2020). 우리는 이미 존재하는 YFCC100M에 대한 우리 dataset의 주요 이점이 훨씬 더 큰 크기라고 의심한다.
마지막으로, 우리는 WIT가 이 filtered subset of YFCC100M을 포함한다는 점을 주의시킨다. 이는 우리의 ablation이 YFCC100M과 WIT의 나머지 사이의 성능 차이 크기를 과소평가하게 만들 수 있다. YFCC100M은 전체 WIT data blend의 3.7%에 불과하고 WIT 생성 중 기존 data blend에 추가되었을 때 모델 성능을 눈에 띄게 바꾸지 않았으므로, 우리는 이것이 가능성이 높다고 생각하지 않는다.
| Text Retrieval | Image Retrieval | ||||||||||||
| Flickr30k | MSCOCO | Flickr30k | MSCOCO | ||||||||||
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | ||
| Finetune | Unicoder-VLa | 86.2 | 96.3 | 99.0 | 62.3 | 87.1 | 92.8 | 71.5 | 90.9 | 94.9 | 46.7 | 76.0 | 85.3 |
| Uniterb | 87.3 | 98.0 | 99.2 | 65.7 | 88.6 | 93.8 | 75.6 | 94.1 | 96.8 | 52.9 | 79.9 | 88.0 | |
| VILLAc | 87.9 | 97.5 | 98.8 | - | - | - | 76.3 | 94.2 | 96.8 | - | - | - | |
| Oscard | - | - | - | 73.5 | 92.2 | 96.0 | - | - | - | 57.5 | 82.8 | 89.8 | |
| ERNIE-ViLe | 88.7 | 98.0 | 99.2 | - | - | - | 76.7 | 93.6 | 96.4 | - | - | - | |
| Zero-Shot | Visual N-Gramsf | 15.4 | 35.7 | 45.1 | 8.7 | 23.1 | 33.3 | 8.8 | 21.2 | 29.9 | 5.0 | 14.5 | 21.9 |
| ImageBERTg | - | - | - | 44.0 | 71.2 | 80.4 | - | - | - | 32.3 | 59.0 | 70.2 | |
| Unicoder-VLa | 64.3 | 86.8 | 92.3 | - | - | - | 48.4 | 76.0 | 85.2 | - | - | - | |
| Uniterb | 83.6 | 95.7 | 97.7 | - | - | - | 68.7 | 89.2 | 93.9 | - | - | - | |
| CLIP | 88.0 | 98.7 | 99.4 | 58.4 | 81.5 | 88.1 | 68.7 | 90.6 | 95.2 | 37.8 | 62.4 | 72.2 | |
Appendix E선택된 Task 및 Dataset 결과
이 연구에서 고려한 데이터셋과 실험의 종류가 매우 많기 때문에, 본문은 전체 결과를 요약하고 분석하는 데 초점을 맞춘다. 다음 subsections에서는 특정 task, dataset, evaluation setting 그룹에 대한 성능 세부사항을 보고한다.
E.1 Image and Text Retrieval
CLIP은 우리의 noisy web-scale dataset에서 image-text retrieval 작업을 위해 pre-train한다. 이 논문의 초점은 매우 다양한 downstream datasets로의 transfer를 위한 representation learning과 task learning에 있지만, CLIP이 pre-trained된 바로 그 작업에서 높은 transfer performance를 달성할 수 있음을 검증하는 것은 중요한 sanity check / proof of concept이다. Table13에서 우리는 Flickr30k와 MSCOCO datsets에서 text 및 image retrieval 모두에 대한 CLIP의 zero-shot transfer performance를 확인한다. Zero-shot CLIP은 이 두 데이터셋에서 모든 prior zero-shot results와 같거나 이를 능가한다. Zero-shot CLIP은 또한 Flickr30k에서 text retrieval 작업의 현재 overall SOTA와도 경쟁적이다. Image retrieval에서는 overall state of the art 대비 CLIP의 성능이 눈에 띄게 낮다. 그러나 zero-shot CLIP은 여전히 fine-tuned Unicoder-VL과 경쟁적이다. 더 큰 MS-COCO dataset에서는 fine-tuning이 성능을 크게 향상시키며 zero-shot CLIP은 가장 최근 연구와 경쟁적이지 않다. 이 두 데이터셋 모두에 대해 우리는 각 이미지의 description 앞에 prompt “a photo of”를 붙였으며, 이것이 CLIP의 zero-shot R@1 성능을 1에서 2 points 사이로 향상시킨다는 것을 발견했다.
| IIIT5K | Hateful | |||||
| MNIST | SVHN | 1k | Memes | SST-2 | ||
| Finetune | SOTA | 99.8a | 96.4b | 98.9c | 78.0d | 97.5e |
| JOINTf | - | - | 89.6 | - | - | |
| CBoWg | - | - | - | - | 80.0 | |
| Linear | Raw Pixels | 92.5 | - | - | - | - |
| ES Best | 98.9h | - | - | 58.6h | 59.0i | |
| CLIP | 99.2 | - | - | 77.3 | 80.5 | |
|
ZS |
CLIP | 88.4 | 51.0 | 90.0 | 63.3 | 67.9 |
E.2 Optical Character Recognition
시각화는 ImageNet 모델이 이미지 내 텍스트의 존재에 반응하는 features를 포함함을 보여주었지만(Zeiler&Fergus,2014), 이러한 representations는 optical character recognition (OCR) 작업에 사용하기에는 충분히 fine-grained하지 않다. 이를 보완하기 위해, 이 capability가 필요한 작업에서 성능을 높이도록 모델은 custom OCR engines와 features의 outputs로 augment된다(Singh et al.,2019; Yang et al.,2020). CLIP 개발 초기에, 우리는 CLIP이 primitive OCR capabilities를 배우기 시작했으며 프로젝트 과정 동안 꾸준히 개선되는 것으로 보인다는 것을 알아차렸다. 이러한 정성적으로 관찰된 behavior를 평가하기 위해, 우리는 OCR의 직접 및 간접 사용을 요구하는 5개 데이터셋에서 성능을 측정했다. 이 데이터셋 중 세 개인 MNIST(LeCun,), SVHN(Netzer et al.,2011), 그리고 IIIT5K(Mishra et al.,2012)는 모델이 low-level character 및 word recognition을 수행하는 능력을 직접 확인하는 반면, Hateful Memes(Kiela et al.,2020)및 SST-2(Socher et al.,2013)는 모델이 semantic task를 수행하기 위해 OCR을 사용하는 능력을 확인한다. 결과는 Table14.
CLIP의 성능은 여전히 매우 가변적이며 domain(rendered 또는 natural images)과 인식될 text의 유형(numbers 또는 words)의 어떤 조합에 민감한 것으로 보인다. CLIP의 OCR 성능은 Hateful Memes와 SST-2에서 가장 강하다 - 이들은 text가 digitally rendered되고 대부분 words로 구성된 datasets이다. 개별적으로 cropped된 words의 natural images인 IIIT5K에서 zero-shot CLIP은 약간 더 각각 수행하며, 그 성능은Jaderberg et al. (2014)의 open-vocabulary OCR을 수행하기 위해 deep learning과 structured prediction을 결합한 초기 연구와 유사하다. 그러나 hand written 및 street view numbers의 인식을 포함하는 두 데이터셋에서는 성능이 눈에 띄게 낮다. full number SVHN에서 CLIP의 51% accuracy는 어떤 published results보다도 훨씬 낮다. 검토 결과 CLIP은 repeated characters뿐 아니라 SVHN의 낮은 resolution과 blurry images에 어려움을 겪는 것으로 보인다. CLIP의 zero-shot MNIST 성능도 낮으며, 가능한 가장 단순한 machine learning baselines 중 하나인 raw pixels에 대한 supervised logistic regression보다 뒤처진다.
SST-2는 우리가 images로 render한 sentence level NLP dataset이다. 우리는 CLIP이 low level OCR capability를 higher level representation으로 변환할 수 있는지 확인하기 위해 SST-2를 포함한다. rendered sentences에 대한 CLIP의 representation 위에 linear classifier를 fitting하면 80.5% accuracy를 달성한다. 이는 840 billion tokens로 pre-trained된 GloVe word vectors를 사용하는 continuous bag of words baseline의 80% accuracy와 동등하다(Pennington et al.,2014). 이는 오늘날 기준으로는 단순한 NLP baseline이고 현재 SOTA의 97.5%보다 훨씬 낮지만, CLIP이 rendered text의 이미지를 non-trivial sentence level representation으로 바꿀 수 있음을 보는 것은 고무적이다. Fully supervised CLIP은 Hateful Meme detection에서도 놀라울 정도로 강하며, CLIP은 현재 single model SOTA보다 단지 0.7 points 뒤지고 원 논문의 best baseline보다 몇 points 높다. SST-2와 유사하게, Hateful Memes에 대한 이러한 다른 결과들은 CLIP이 접근할 수 없는 ground truth text를 사용한다. 마지막으로, 우리는 zero-shot CLIP이 우리의 evaluation suite에 포함된 다른 56개 모델 전반에서 fully supervised linear probes를 사용한 최고 결과를 능가한다는 점에 주목한다. 이는 CLIP의 OCR capability가 self-supervised 및 supervised representation learning에 대한 기존 연구와 비교해 적어도 어느 정도는 unique함을 시사한다.
| UCF101 | K700 | RareAct | |||
| Top-1 | AVG | mWAP | mWSAP | ||
| Finetune | R(2+1)D-BERTa | 98.7 | - | - | - |
| NS ENet-L2b | - | 84.8 | - | - | |
| HT100M S3Dd | 91.3 | - | - | - | |
| Baseline I3De | - | 70.2 | - | - | |
| Linear | MMV FACf | 91.8 | - | - | - |
| NS ENet-L2c | 89.4c | 68.2c | - | - | |
| CLIP | 92.0 | 73.0 | - | - | |
| ZS | HT100M S3Dd | - | - | 30.5 | 34.8 |
| CLIP | 80.3 | 69.6 | 40.7 | 44.8 | |
E.3 비디오에서의 Action Recognition
학습의 목적에서, 자연어의 잠재적으로 중요한 한 측면은 극도로 넓은 개념 집합을 표현하고, 따라서 supervise할 수 있는 능력이다. CLIP 모델은 semi-arbitrary text를 images와 pair하도록 훈련되기 때문에, common nouns와 proper nouns, verbs, adjectives를 모두 포함하는 넓은 범위의 visual concepts에 대해 supervision을 받을 가능성이 높다. 반대로 ImageNet-1K는 common nouns에만 labels를 붙인다. ImageNet에서 더 넓은 supervision의 부족은 ImageNet 모델이 nouns가 아닌 visual concepts의 인식을 포함하는 tasks로 transfer될 때 더 약하게 만드는가?
이를 조사하기 위해, 우리는 verbs를 인식하는 모델의 능력을 측정하는 여러 video action classification datasets에서 CLIP과 ImageNet 모델의 성능을 측정하고 비교한다. Table15에서 우리는 UCF-101에 대한 결과를 보고한다(Soomro et al.,2012)및 Kinetics-700(Carreira et al.,2019), 이 작업을 위한 두 가지 일반적인 데이터셋이다. 불행히도, 우리의 CPU 기반 선형 분류기는 매우 많은 수의 훈련 프레임 때문에 비디오 데이터셋에서 평가하는 데 금지적으로 긴 시간이 걸린다. 이를 처리하기 위해, 우리는 각 비디오를 단 하나의 중앙 프레임으로 공격적으로 서브샘플링하여, 사실상 이를 이미지 분류 데이터셋으로 바꾸었다. 결과적으로, 선형 평가 설정에서 우리가 보고한 성능은 아마도 성능을 어느 정도 과소평가한다.
| IN | IN-V2 | IN-A | IN-R | ObjectNet | IN-Sketch | IN-Vid | YTBB | |||
| Top-1 | Top-1 | Top-1 | Top-1 | Top-1 | Top-1 | PM0 | PM10 | PM0 | PM10 | |
| NS EfficientNet-L2a | 88.3 | 80.2 | 84.9 | 74.7 | 68.5 | 47.6 | 88.0 | 82.1 | 67.7 | 63.5 |
| FixResNeXt101-32x48d V2b | 86.4 | 78.0 | 68.4 | 80.0 | 57.8 | 59.1 | 85.8 | 72.2 | 68.9 | 57.7 |
| Linear Probe CLIP | 85.4 | 75.9 | 75.3 | 84.2 | 66.2 | 57.4 | 89.1 | 77.2 | 68.7 | 63.1 |
| Zero-Shot CLIP | 76.2 | 70.1 | 77.2 | 88.9 | 72.3 | 60.2 | 95.3 | 89.2 | 95.2 | 88.5 |
이러한 불리함에도 불구하고, CLIP 특징은 이 작업으로 놀라울 정도로 잘 전이된다. CLIP은 선형 프로브 평가 설정에서 UCF-101의 최고 이전 결과와 일치하며 또한 우리의 평가 모음의 다른 모든 모델보다 성능이 좋다. Kinetics-700에서도 CLIP은 원 논문의 fine-tuned I3D baseline보다 성능이 좋다. 훈련 단계를 필요로 하지 않기 때문에, 우리는 모든 프레임에 걸쳐 예측을 평균낼 때 CLIP의 zero-shot 성능을 보고한다. CLIP은 이 설정에서도 잘 수행하며 Kinetics-700에서 그 성능은 545000개의 라벨이 지정된 비디오로 훈련된 완전 지도 I3D baseline의 1% 이내이다. 이러한 결과에 고무되어, 우리는 또한 최근 도입된 RareAct dataset에서 CLIP의 성능을 측정한다(Miech et al.,2020a)이는 “hammering a phone” 및 “drilling an egg”와 같은 특이한 행동의 zero-shot 인식을 측정하도록 설계되었다. CLIP은 이전 state of the art인, 1억 개의 instructional videos에서 자동으로 추출된 캡션으로 훈련된 S3D 모델보다 10 포인트 향상된다.
CLIP이 action recognition 작업에서 고무적으로 강한 성능을 보이지만, 우리는 비교되는 모델들 사이에는 단지 supervision의 형태를 넘어서 model architecture, training data distribution, dataset size, 사용된 compute와 같은 많은 차이가 있음을 주목한다. 이 작업에서 높은 성능을 달성하는 데 어떤 특정 설계 결정이 기여하는지 더 정확히 결정하기 위해서는 추가 연구가 필요하다.
| 1km | 25km | 200km | 750km | 2500km | |
| ISNsa | 16.9 | 43.0 | 51.9 | 66.7 | 80.2 |
| CPlaNetb | 16.5 | 37.1 | 46.4 | 62.0 | 78.5 |
| CLIP | 13.9 | 32.9 | 43.0 | 62.0 | 79.3 |
| Deep-Ret+c | 14.4 | 33.3 | 47.7 | 61.6 | 73.4 |
| PlaNetd | 8.4 | 24.5 | 37.6 | 53.6 | 71.3 |
E.4 Geolocalization
CLIP의 개발 중 우리가 알아차린 또 다른 행동은 많은 장소와 위치를 인식하는 능력이었다. 이를 정량화하기 위해 우리는 Appendix에 설명된 대로 Country211 dataset을 만들었다A그리고 논문 전반에 걸쳐 이에 대한 결과를 보고한다. 그러나 이는 새로운 benchmark이므로 geolocalization에 대한 이전 연구와 비교하기 위해 우리는 또한 다음의 IM2GPS test set에 대한 결과를 보고한다Hays&Efros (2008)Table에서17. IM2GPS는 regression benchmark이므로, 우리는 CLIP의 embedding space를 사용하여 reference images 집합에서 가장 가까운 이미지의 GPS coordinates를 추측한다. 이는 nearest-neighbor regression을 사용하기 때문에 zero-shot 결과가 아니다. 이전 연구보다 훨씬 적은 100만 개의 이미지만 query했음에도 불구하고, CLIP은 여러 task specific models와 유사하게 수행한다. 그러나 현재의 state of the art와 경쟁력이 있지는 않다.
E.5 Distribution Shift에 대한 강건성
Section3.3은 ImageNet 관련 강건성 결과의 high level 요약과 분석을 제공한다. 우리는 이 appendix에서 몇 가지 추가적인 수치 세부사항을 간략히 제공한다. 데이터셋별 성능 결과는 Table에 제공된다16그리고 현재 state of the art 결과와 비교된다, 이는 다음에 보고되어 있다Taori et al. (2020)의 evaluation suite. Zero-shot CLIP은 7개 데이터셋 중 5개인 ImageNet-R, ObjectNet, ImageNet-Sketch, ImageNet-Vid, Youtube-BB에서 state of the art를 향상시킨다. CLIP의 향상은 유연한 zero-shot capability 때문에 ImageNet-Vid와 Youtube-BB에서 가장 크며, ImageNet-R에서도 큰데, 이는 CLIP의 pre-training distribution이 상당한 양의 creative content를 포함한다는 점을 반영하는 것 같다. 유사한 행동은 다음에서 논의된 것처럼 Instagram pre-trained ResNeXt models에 대해 문서화되어 있다Taori et al. (2020).
Appendix FModel Hyperparameters
| Hyperparameter | Value |
| Batch size | 32768 |
| Vocabulary size | 49408 |
| Training epochs | 32 |
| Maximum temperature | 100.0 |
| Weight decay | 0.2 |
| Warm-up iterations | 2000 |
| Adam | 0.9 |
| Adam | 0.999 (ResNet), 0.98 (ViT) |
| Adam | (ResNet),(ViT) |
| Learning | Embedding | Input | ResNet | Text Transformer | ||||
| Model | rate | dimension | resolution | blocks | width | layers | width | heads |
| RN50 | 1024 | 224 | (3, 4, 6, 3) | 2048 | 12 | 512 | 8 | |
| RN101 | 512 | 224 | (3, 4, 23, 3) | 2048 | 12 | 512 | 8 | |
| RN50x4 | 640 | 288 | (4, 6, 10, 6) | 2560 | 12 | 640 | 10 | |
| RN50x16 | 768 | 384 | (6, 8, 18, 8) | 3072 | 12 | 768 | 12 | |
| RN50x64 | 1024 | 448 | (3, 15, 36, 10) | 4096 | 12 | 1024 | 16 | |
| Learning | Embedding | Input | Vision Transformer | Text Transformer | |||||
| Model | rate | dimension | resolution | layers | width | heads | layers | width | heads |
| ViT-B/32 | 512 | 224 | 12 | 768 | 12 | 12 | 512 | 8 | |
| ViT-B/16 | 512 | 224 | 12 | 768 | 12 | 12 | 512 | 8 | |
| ViT-L/14 | 768 | 224 | 24 | 1024 | 16 | 12 | 768 | 12 | |
| ViT-L/14-336px | 768 | 336 | 24 | 1024 | 16 | 12 | 768 | 12 | |