Language Models are Few-Shot Learners
초록
최근 연구는 대규모 텍스트 말뭉치에서 사전 학습한 뒤 특정 과제에 대해 미세 조정함으로써 많은 NLP 과제와 벤치마크에서 상당한 향상을 보였다. 이 방법은 보통 아키텍처 측면에서는 과제 불가지론적이지만, 여전히 수천 또는 수만 개 예시의 과제별 미세 조정 데이터셋을 필요로 한다. 대조적으로, 인간은 일반적으로 몇 개의 예시나 단순한 지시만으로 새로운 언어 과제를 수행할 수 있는데, 이는 현재 NLP 시스템들이 여전히 대체로 어려움을 겪는 것이다. 여기서 우리는 언어 모델을 확장하는 것이 과제 불가지론적 few-shot 성능을 크게 향상시키며, 때로는 이전 state-of-the-art 미세 조정 접근법과 경쟁 가능한 수준에 이르기도 함을 보인다. 구체적으로, 우리는 1,750억 개 매개변수를 가진 autoregressive language model인 GPT-3를 학습시키는데, 이는 이전의 어떤 non-sparse language model보다 10x 더 많으며, few-shot 설정에서 그 성능을 시험한다. 모든 과제에 대해 GPT-3는 어떠한 gradient update나 fine-tuning 없이 적용되며, 과제와 few-shot demonstrations는 순전히 모델과의 텍스트 상호작용을 통해 지정된다. GPT-3는 번역, question-answering, cloze tasks를 포함한 많은 NLP 데이터셋에서 강한 성능을 달성하며, 단어 뒤섞기 풀기, 새로운 단어를 문장에 사용하기, 또는 3자리 산술 수행과 같이 즉석 추론이나 domain adaptation을 요구하는 여러 과제에서도 강한 성능을 보인다. 동시에 우리는 GPT-3의 few-shot learning이 여전히 어려움을 겪는 일부 데이터셋과, GPT-3가 대규모 웹 말뭉치에서의 학습과 관련된 방법론적 문제에 직면하는 일부 데이터셋도 식별한다. 마지막으로, 우리는 GPT-3가 인간 평가자들이 인간이 쓴 기사와 구별하기 어려워하는 뉴스 기사 샘플을 생성할 수 있음을 발견한다. 우리는 이 발견과 GPT-3 일반의 더 넓은 사회적 영향을 논의한다.
1 서론
최근 몇 년 동안 NLP 시스템에서는 사전 학습된 언어 표현으로 향하는 추세가 나타났으며, 이는 downstream transfer를 위해 점점 더 유연하고 과제 불가지론적인 방식으로 적용되었다. 먼저, 단일 층 표현이 word vectors를 사용하여 학습되었고[82, 102]과제별 아키텍처에 입력되었으며, 그 다음에는 여러 층의 표현과 contextual state를 가진 RNN들이 더 강한 표현을 형성하는 데 사용되었다[24, 81, 100](비록 여전히 과제별 아키텍처에 적용되었지만), 그리고 더 최근에는 사전 학습된 recurrent 또는 transformer language models가[134]직접 미세 조정되어, 과제별 아키텍처의 필요성을 완전히 제거했다[112, 20, 43].
이 마지막 패러다임은 reading comprehension, question answering, textual entailment 및 많은 다른 어려운 NLP 과제에서 상당한 진전을 이끌었으며, 새로운 아키텍처와 알고리즘에 기반하여 계속 발전해 왔다[116, 74, 139, 62]. 그러나 이 접근법의 주요 한계는 아키텍처가 과제 불가지론적이기는 하지만, 여전히 과제별 데이터셋과 과제별 미세 조정이 필요하다는 점이다. 원하는 과제에서 강한 성능을 달성하려면 일반적으로 해당 과제에 특화된 수천에서 수십만 개 예시의 데이터셋에서 미세 조정해야 한다. 이 한계를 제거하는 것은 여러 이유로 바람직할 것이다.
첫째, 실용적인 관점에서 모든 새로운 과제마다 대규모의 라벨링된 예시 데이터셋이 필요하다는 점은 언어 모델의 적용 가능성을 제한한다. 문법을 교정하는 것부터 추상적 개념의 예시를 생성하는 것, 짧은 이야기를 비평하는 것에 이르기까지, 가능한 유용한 언어 과제의 범위는 매우 넓다. 이러한 많은 과제에 대해 대규모 지도 학습 데이터셋을 수집하는 것은 어렵고, 특히 그 과정이 모든 새로운 과제마다 반복되어야 할 때 더욱 그렇다.
둘째, 학습 데이터의 spurious correlations를 이용할 가능성은 모델의 표현력과 학습 분포의 협소함에 따라 근본적으로 커진다. 이는 pre-training plus fine-tuning 패러다임에 문제를 만들 수 있는데, 이 패러다임에서는 모델이 사전 학습 동안 정보를 흡수하도록 크게 설계되지만, 그 후 매우 좁은 과제 분포에서 미세 조정되기 때문이다. 예를 들어[41]더 큰 모델이 반드시 out-of-distribution에서 더 잘 일반화하는 것은 아니라고 관찰한다. 이 패러다임에서 달성되는 일반화가, 모델이 학습 분포에 지나치게 특화되어 그 바깥으로 잘 일반화하지 못하기 때문에 나쁠 수 있음을 시사하는 증거가 있다[138, 88]. 따라서 특정 벤치마크에서 미세 조정된 모델의 성능은, 명목상 인간 수준일 때조차, underlying task에서의 실제 성능을 과장할 수 있다[36, 91].
셋째, 인간은 대부분의 언어 과제를 배우기 위해 대규모 지도 데이터셋을 필요로 하지 않는다. 자연어로 된 간단한 지시(예: “이 문장이 행복한 것을 묘사하는지 슬픈 것을 묘사하는지 말해 주세요”) 또는 많아야 아주 적은 수의 demonstration(예: “여기 용감하게 행동하는 사람들의 예시가 두 개 있습니다. 용기의 세 번째 예시를 주세요”)만으로도 인간이 새로운 과제를 적어도 합리적인 수준의 숙련도로 수행할 수 있게 하기에 충분한 경우가 많다. 이는 현재 NLP 기법의 개념적 한계를 가리키는 것 외에도 실용적 장점을 가진다. 예를 들어 긴 대화 중에 덧셈을 수행하는 것처럼, 인간이 많은 과제와 기술을 매끄럽게 섞거나 전환할 수 있게 한다. 널리 유용하려면, 우리는 언젠가 NLP 시스템도 이와 같은 유연성과 일반성을 갖기를 바란다.
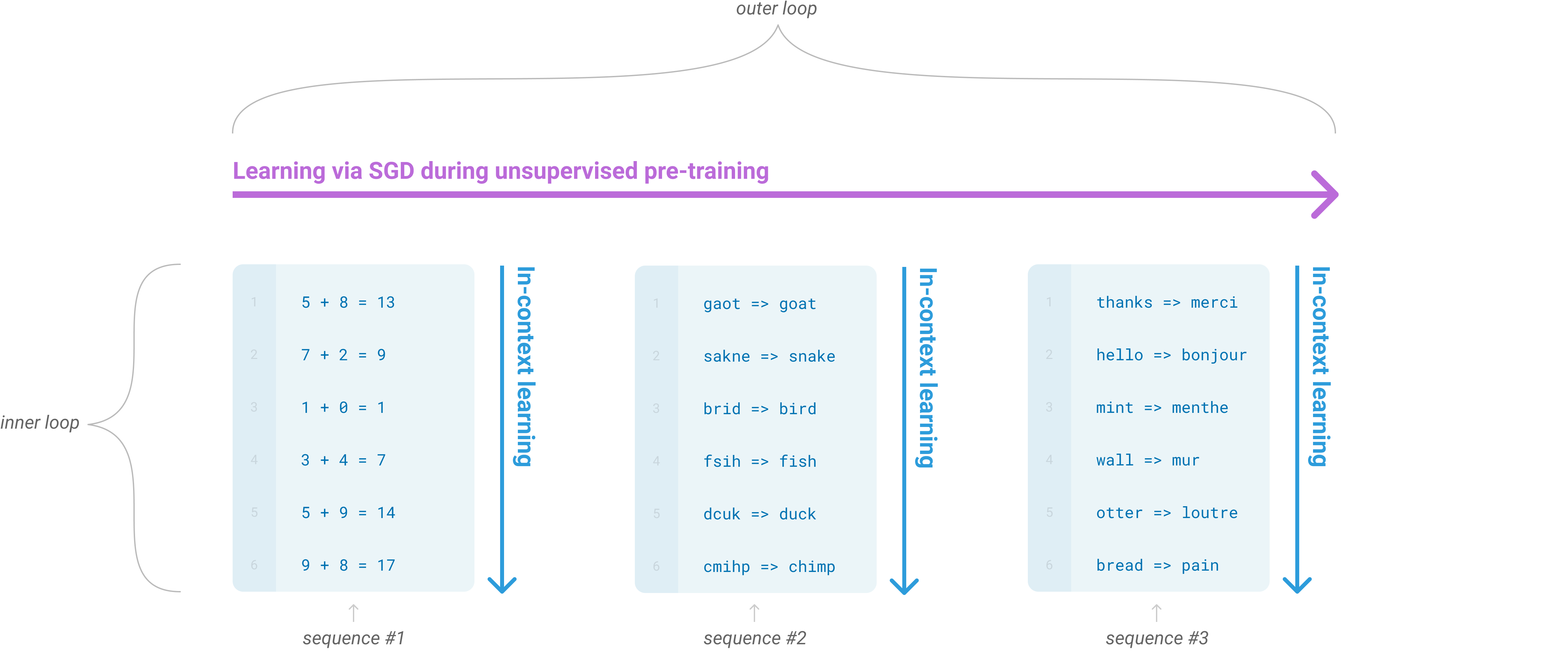
이러한 문제들을 해결하기 위한 하나의 잠재적 경로는 meta-learning이다111언어 모델의 맥락에서 이것은 때때로 “zero-shot transfer”라고 불렸지만, 이 용어는 잠재적으로 모호하다. 이 방법은 gradient update가 수행되지 않는다는 의미에서는 “zero-shot”이지만, 종종 추론 시점의 demonstrations를 모델에 제공하는 것을 포함하므로, 실제로는 zero examples로부터 배우는 것이 아니다. 이러한 혼동을 피하기 위해, 우리는 일반적 방법의 inner-loop / outer-loop 구조를 포착하기 위해 “meta-learning”이라는 용어를 사용하고, meta-learning의 inner loop를 가리키기 위해 “in context-learning”이라는 용어를 사용한다. 우리는 추론 시점에 제공되는 demonstrations의 수에 따라 설명을 “zero-shot”, “one-shot”, 또는 “few-shot”으로 더 구체화한다. 이러한 용어들은 모델이 추론 시점에 새로운 과제를 처음부터 배우는지, 아니면 단순히 학습 중 본 패턴을 인식하는지에 관한 질문에 대해 불가지론적으로 남도록 의도되었다. 이는 논문 뒤에서 논의하는 중요한 문제이지만, “meta-learning”은 두 가능성을 모두 포괄하도록 의도되었으며, 단순히 inner-outer loop 구조를 설명한다.– 이는 언어 모델의 맥락에서 모델이 학습 시점에 광범위한 기술과 패턴 인식 능력을 개발한 뒤, 추론 시점에 그 능력을 사용하여 원하는 과제에 빠르게 적응하거나 이를 인식한다는 뜻이다(Figure에 설명됨1.1). 최근 연구는[117]우리가 “in-context learning”이라고 부르는 것을 통해 이를 시도하며, 사전 학습된 언어 모델의 텍스트 입력을 과제 지정의 한 형태로 사용한다. 모델은 자연어 지시 및/또는 과제의 몇 가지 demonstrations에 조건화되고, 그 다음 단순히 다음에 올 것을 예측함으로써 과제의 추가 사례를 완성할 것으로 기대된다.
이 접근법은 초기 가능성을 일부 보였지만, 여전히 fine-tuning보다 훨씬 열등한 결과를 달성한다. 예를 들어[117]Natural Questions에서 겨우 4%를 달성하고, CoQa에서의 55 F1 결과조차 현재 state of the art보다 35점 이상 뒤처져 있다. Meta-learning이 언어 과제를 해결하는 실용적 방법으로 viable해지려면 명백히 상당한 개선이 필요하다.
언어 모델링의 또 다른 최근 추세가 앞으로 나아갈 길을 제공할 수 있다. 최근 몇 년 동안 transformer language models의 용량은 1억 개 매개변수에서[112], 3억 개 매개변수로[20], 15억 개 매개변수로[117], 80억 개 매개변수로[125], 110억 개 매개변수로[116], 그리고 마침내 170억 개 매개변수로 상당히 증가했다[132]. 각각의 증가는 텍스트 합성 및/또는 downstream NLP tasks에서 개선을 가져왔으며, 많은 downstream tasks와 잘 상관되는 log loss가 scale에 따라 매끄러운 개선 추세를 따른다는 증거가 있다[57]. in-context learning은 모델의 매개변수 안에 많은 기술과 과제를 흡수하는 것을 포함하므로, in-context learning 능력도 scale에 따라 비슷하게 강한 향상을 보일 수 있다는 것은 그럴듯하다.
이 논문에서 우리는 GPT-3라고 부르는 1,750억 매개변수 autoregressive language model을 학습시키고 그 in-context learning 능력을 측정함으로써 이 가설을 시험한다. 구체적으로, 우리는 GPT-3를 20개가 넘는 NLP 데이터셋과, 학습 세트에 직접 포함되어 있을 가능성이 낮은 과제에 대한 빠른 적응을 시험하도록 설계된 여러 새로운 과제에서 평가한다. 각 과제에 대해 우리는 GPT-3를 3가지 조건에서 평가한다: (a) “few-shot learning”, 즉 모델의 context window에 들어갈 수 있는 만큼 많은 demonstrations(일반적으로 10에서 100)를 허용하는 in-context learning, (b) 하나의 demonstration만 허용하는 “one-shot learning”, 그리고 (c) demonstrations는 허용하지 않고 자연어 지시만 모델에 주어지는 “zero-shot” learning. GPT-3는 원칙적으로 전통적인 fine-tuning 설정에서도 평가될 수 있지만, 우리는 이를 향후 연구로 남긴다.
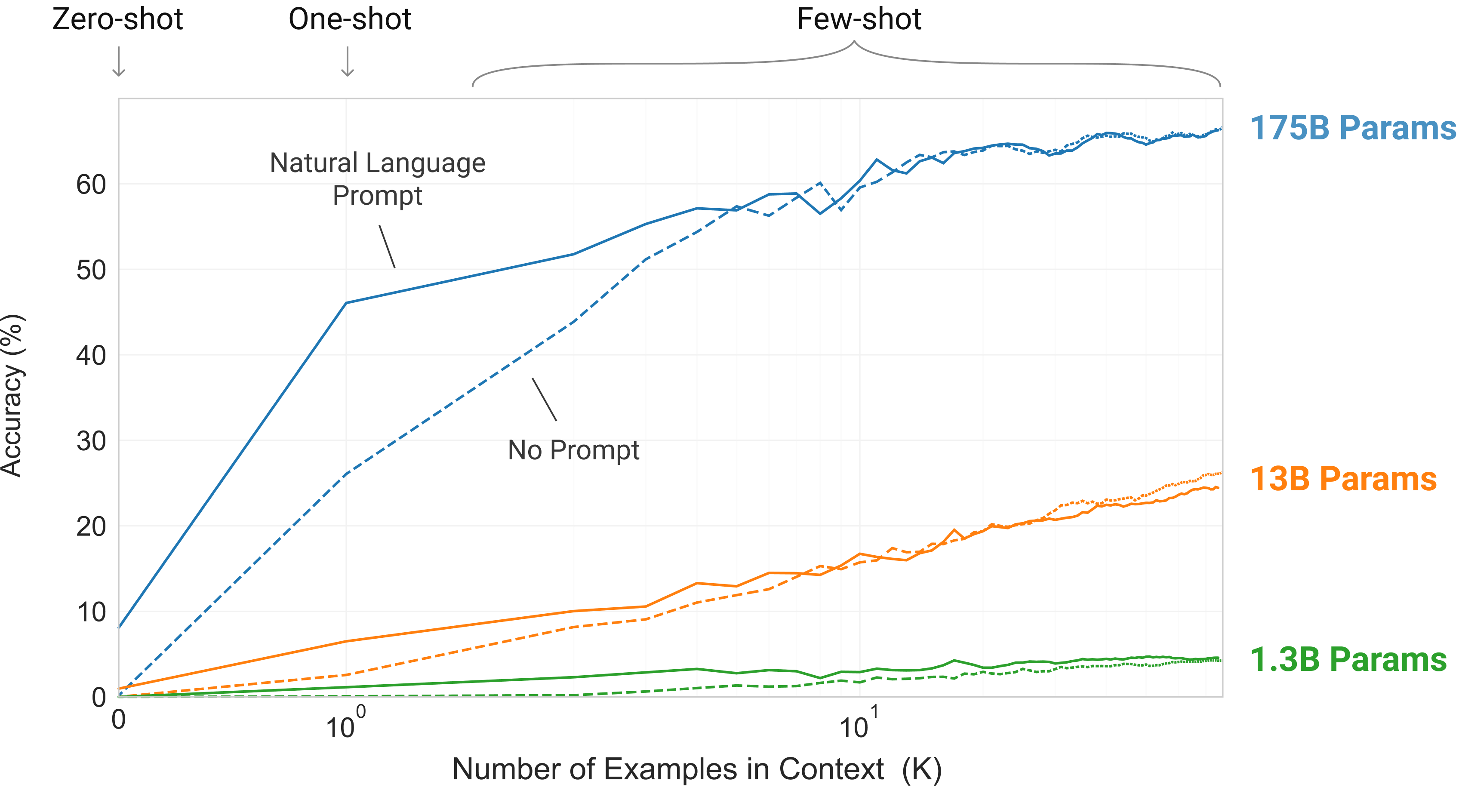
Figure1.2우리가 연구하는 조건들을 설명하고, 모델이 단어에서 불필요한 기호를 제거해야 하는 간단한 과제의 few-shot learning을 보여준다. 모델 성능은 자연어 과제 설명의 추가와 모델의 context 안 예시 수에 따라 향상된다,. Few-shot learning도 모델 크기에 따라 극적으로 향상된다. 이 경우의 결과가 특히 두드러지기는 하지만, 모델 크기와 in-context 예시 수 모두에 따른 일반적 추세는 우리가 연구하는 대부분의 과제에서 유지된다. 우리는 이러한 “learning” curves가 gradient updates나 fine-tuning을 포함하지 않고, 단지 conditioning으로 주어진 demonstrations의 수가 증가하는 것일 뿐임을 강조한다.
전반적으로, NLP 과제에서 GPT-3는 zero-shot 및 one-shot 설정에서 유망한 결과를 달성하며, few-shot 설정에서는 때때로 state-of-the-art와 경쟁 가능하거나 심지어 가끔 이를 능가한다(비록 state-of-the-art는 fine-tuned models가 보유하고 있음에도). 예를 들어, GPT-3는 zero-shot 설정에서 CoQA 81.5 F1, one-shot 설정에서 CoQA 84.0 F1, few-shot 설정에서 85.0 F1을 달성한다. 유사하게, GPT-3는 zero-shot 설정에서 TriviaQA 64.3% accuracy, one-shot 설정에서 68.0%, few-shot 설정에서 71.2%를 달성하며, 마지막 결과는 동일한 closed-book 설정에서 작동하는 fine-tuned models와 비교해 state-of-the-art이다.
GPT-3는 또한 단어 뒤섞기 풀기, 산술 수행, 그리고 한 번만 정의된 것을 본 뒤 새로운 단어를 문장에 사용하는 것을 포함하여, 빠른 적응 또는 즉석 추론을 시험하도록 설계된 과제에서 one-shot 및 few-shot 숙련도를 보인다. 우리는 또한 few-shot 설정에서 GPT-3가 인간 평가자들이 인간이 생성한 기사와 구별하기 어려워하는 합성 뉴스 기사를 생성할 수 있음을 보인다.
동시에, 우리는 GPT-3의 규모에서도 few-shot 성능이 어려움을 겪는 일부 과제를 발견한다. 여기에는 ANLI dataset 같은 natural language inference 과제와 RACE 또는 QuAC 같은 일부 reading comprehension 데이터셋이 포함된다. 이러한 한계를 포함하여 GPT-3의 강점과 약점에 대한 폭넓은 특성화를 제시함으로써, 우리는 언어 모델에서 few-shot learning 연구를 촉진하고 진전이 가장 필요한 지점에 주의를 끌기를 바란다.
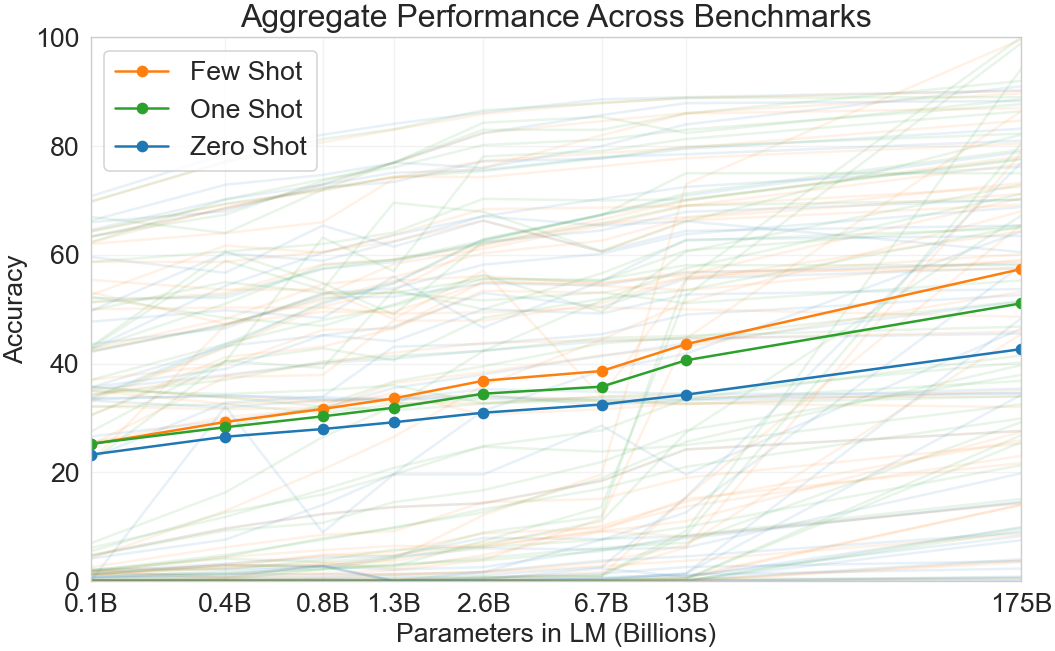
전체 결과에 대한 휴리스틱한 감각은 Figure에서 볼 수 있다1.3, 이는 다양한 과제를 집계한다(비록 그 자체로 엄밀하거나 의미 있는 benchmark로 보아서는 안 된다).
우리는 또한 “data contamination”에 대한 체계적 연구를 수행한다. 이는 Common Crawl과 같은 데이터셋에서 고용량 모델을 학습할 때 증가하는 문제로, 그러한 데이터셋은 단순히 해당 콘텐츠가 웹에 자주 존재하기 때문에 test datasets의 콘텐츠를 잠재적으로 포함할 수 있다. 이 논문에서 우리는 data contamination을 측정하고 그 왜곡 효과를 정량화하는 체계적 도구를 개발한다. data contamination이 대부분의 데이터셋에서 GPT-3의 성능에 미치는 영향은 미미하다는 것을 발견하지만, 결과를 부풀릴 수 있는 몇몇 데이터셋을 식별하며, 심각도에 따라 이러한 데이터셋에서는 결과를 보고하지 않거나 별표로 표시한다.
위의 모든 것에 더해, 우리는 zero, one 및 few-shot 설정에서의 성능을 GPT-3와 비교하기 위해 일련의 더 작은 모델들(1억 2,500만 매개변수부터 130억 매개변수까지)을 학습시킨다. 전반적으로, 대부분의 과제에서 우리는 세 설정 모두에서 모델 용량에 따른 비교적 매끄러운 scaling을 발견한다. 한 가지 주목할 만한 패턴은 zero-, one-, few-shot 성능 사이의 격차가 종종 모델 용량과 함께 커진다는 점이며, 이는 더 큰 모델이 더 능숙한 meta-learners임을 시사할 수 있다.
마지막으로, GPT-3가 보여주는 광범위한 능력 스펙트럼을 고려하여, 우리는 bias, fairness, 그리고 더 넓은 사회적 영향에 관한 우려를 논의하고, 이와 관련한 GPT-3의 특성에 대해 예비 분석을 시도한다.
2 접근법
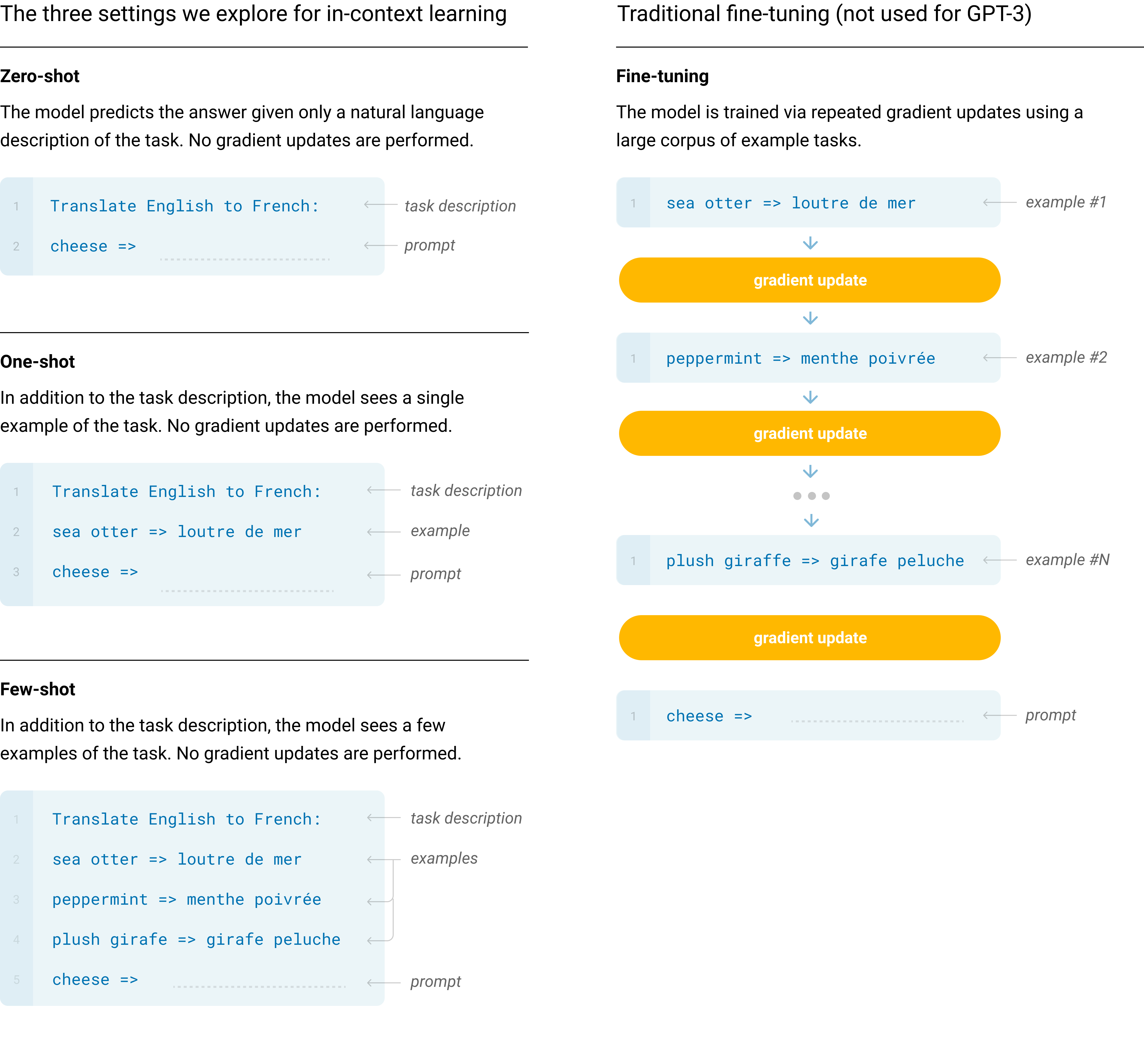
모델, 데이터, 학습을 포함한 우리의 기본 사전 학습 접근법은[117]에 설명된 과정과 유사하며, 모델 크기, 데이터셋 크기와 다양성, 학습 길이를 비교적 직접적으로 확장한 것이다. 우리의 in-context learning 사용도[117]와 유사하지만, 이 연구에서는 context 내 학습을 위한 서로 다른 설정들을 체계적으로 탐구한다. 따라서 우리는 이 절을 GPT-3를 평가할, 또는 원칙적으로 평가할 수 있는 서로 다른 설정들을 명시적으로 정의하고 대조하는 것으로 시작한다. 이러한 설정들은 그들이 의존하는 경향이 있는 과제별 데이터의 양에 대한 스펙트럼 위에 놓인 것으로 볼 수 있다. 구체적으로, 우리는 이 스펙트럼에서 적어도 네 지점을 식별할 수 있다(그림은 Figure 참조2.1참조):
-
•
Fine-Tuning (FT)은 최근 몇 년 동안 가장 일반적인 접근법이었으며, 원하는 과제에 특화된 지도 데이터셋에서 학습함으로써 사전 학습된 모델의 weights를 업데이트하는 것을 포함한다. 일반적으로 수천에서 수십만 개의 라벨링된 예시가 사용된다. fine-tuning의 주요 장점은 많은 벤치마크에서 강한 성능이다. 주요 단점은 모든 과제마다 새로운 대규모 데이터셋이 필요하다는 점, out-of-distribution에서 일반화가 나쁠 가능성[88], 그리고 학습 데이터의 spurious features를 이용할 가능성[36, 91], 잠재적으로 인간 성능과의 불공정한 비교를 초래할 수 있다는 점이다. 이 연구에서 우리는 초점이 과제 불가지론적 성능에 있기 때문에 GPT-3를 fine-tune하지 않지만, GPT-3는 원칙적으로 fine-tune될 수 있으며 이는 향후 연구의 유망한 방향이다.
-
•
Few-Shot (FS)은 이 연구에서 모델이 추론 시점에 conditioning으로 과제의 몇 가지 demonstrations를 받는 설정을 가리키기 위해 사용할 용어이다[117], 그러나 weight updates는 허용되지 않는다. Figure에 보인 것처럼2.1, 전형적인 데이터셋에서 예시는 context와 원하는 completion(예를 들어 영어 문장과 프랑스어 번역)을 가지며, few-shot은개의 context와 completion 예시를 제공한 다음, 마지막으로 context만 있는 하나의 예시를 제공하고, 모델이 completion을 제공할 것으로 기대하는 방식으로 작동한다. 우리는 일반적으로을 10에서 100 범위로 설정하는데, 이는 모델의 context window에 들어갈 수 있는 예시 수이기 때문이다(). few-shot의 주요 장점은 과제별 데이터에 대한 필요를 크게 줄이고, 크지만 좁은 fine-tuning 데이터셋에서 지나치게 좁은 분포를 학습할 가능성을 줄인다는 점이다. 주요 단점은 이 방법의 결과가 지금까지 state-of-the-art fine-tuned models보다 훨씬 나빴다는 점이다. 또한 적은 양의 task specific data는 여전히 필요하다. 이름에서 나타나듯, 여기서 언어 모델에 대해 설명한 few-shot learning은 ML의 다른 맥락에서 사용되는 few-shot learning과 관련이 있다[45, 133]– 둘 다 광범위한 과제 분포(이 경우에는 사전 학습 데이터에 암묵적으로 존재함)에 기반하여 학습한 다음 새로운 과제에 빠르게 적응하는 것을 포함한다.
-
•
One-Shot (1S)은 자연어 과제 설명에 더해 단 하나의 demonstration만 허용된다는 점을 제외하면 few-shot과 동일하며, Figure 1에 보인 바와 같다. one-shot을 few-shot 및 zero-shot(아래)과 구별하는 이유는 이것이 일부 과제가 인간에게 전달되는 방식과 가장 가깝게 일치하기 때문이다. 예를 들어, 인간 작업자 서비스(예: Mechanical Turk)에서 인간에게 데이터셋을 생성해 달라고 요청할 때, 과제의 한 가지 demonstration을 주는 것이 일반적이다. 반대로 예시가 주어지지 않으면 과제의 내용이나 형식을 전달하기가 때때로 어렵다.
-
•
Zero-Shot (0S)은 demonstrations가 허용되지 않고, 모델에게 과제를 설명하는 자연어 지시만 주어진다는 점을 제외하면 one-shot과 동일하다. 이 방법은 최대의 편의성, robustness 가능성, 그리고 spurious correlations의 회피를 제공하지만(그것들이 대규모 사전 학습 데이터 말뭉치 전반에 매우 넓게 발생하지 않는 한), 또한 가장 어려운 설정이다. 어떤 경우에는 인간조차 사전 예시 없이 과제의 형식을 이해하기 어려울 수 있으므로, 이 설정은 어떤 경우에는 “불공정하게 어렵다”. 예를 들어, 누군가에게 “200m 달리기의 세계 기록 표를 만들어라”라고 요청한다면, 표가 정확히 어떤 형식을 가져야 하는지 또는 무엇을 포함해야 하는지가 명확하지 않을 수 있어 이 요청은 모호할 수 있다(그리고 신중한 명확화가 있더라도, 정확히 무엇이 원하는 것인지 이해하는 것은 어려울 수 있다). 그럼에도 적어도 일부 설정에서는 zero-shot이 인간이 과제를 수행하는 방식에 가장 가깝다. 예를 들어 Figure의 번역 예시에서2.1, 인간은 아마도 텍스트 지시만으로 무엇을 해야 하는지 알 것이다.
Figure2.1는 영어를 프랑스어로 번역하는 예시를 사용하여 네 가지 방법을 보여준다. 이 논문에서 우리는 zero-shot, one-shot 및 few-shot에 초점을 맞추며, 이들을 경쟁하는 대안으로 비교하는 것이 아니라 특정 벤치마크에서의 성능과 sample efficiency 사이의 다양한 trade-off를 제공하는 서로 다른 문제 설정으로 비교하는 것을 목표로 한다. 우리는 특히 few-shot 결과를 강조하는데, 그중 많은 결과가 state-of-the-art fine-tuned models에 약간 뒤처질 뿐이기 때문이다. 그러나 궁극적으로 one-shot, 또는 때로는 zero-shot조차, 인간 성능과의 가장 공정한 비교처럼 보이며, 향후 연구의 중요한 목표이다.
Sections2.1-2.3아래에서는 각각 우리의 모델, 학습 데이터, 학습 과정에 대한 세부 사항을 제공한다. Section2.4은 우리가 few-shot, one-shot, zero-shot 평가를 어떻게 수행하는지의 세부 사항을 논의한다.
2.1 모델과 아키텍처
우리는 GPT-2와 동일한 모델 및 아키텍처를 사용한다[117], 그 안에 설명된 modified initialization, pre-normalization, reversible tokenization을 포함하되, transformer의 층들에서 Sparse Transformer와 유사하게 alternating dense 및 locally banded sparse attention patterns를 사용한다는 예외가 있다[15]. ML 성능이 모델 크기에 어떻게 의존하는지 연구하기 위해, 우리는 1억 2,500만 매개변수부터 1,750억 매개변수까지 세 자릿수 규모에 걸친 8가지 서로 다른 크기의 모델을 학습시키며, 마지막 모델이 우리가 GPT-3라고 부르는 모델이다. 이전 연구는[57]충분한 학습 데이터가 있으면 validation loss의 scaling이 크기의 함수로서 대략 매끄러운 power law가 되어야 함을 시사한다. 많은 서로 다른 크기의 모델을 학습시키면 validation loss와 downstream language tasks 모두에서 이 가설을 시험할 수 있다.
| Model Name | Batch Size | Learning Rate | |||||
|---|---|---|---|---|---|---|---|
| GPT-3 Small | 125M | 12 | 768 | 12 | 64 | 0.5M | |
| GPT-3 Medium | 350M | 24 | 1024 | 16 | 64 | 0.5M | |
| GPT-3 Large | 760M | 24 | 1536 | 16 | 96 | 0.5M | |
| GPT-3 XL | 1.3B | 24 | 2048 | 24 | 128 | 1M | |
| GPT-3 2.7B | 2.7B | 32 | 2560 | 32 | 80 | 1M | |
| GPT-3 6.7B | 6.7B | 32 | 4096 | 32 | 128 | 2M | |
| GPT-3 13B | 13.0B | 40 | 5140 | 40 | 128 | 2M | |
| GPT-3 175B 또는 “GPT-3” | 175.0B | 96 | 12288 | 96 | 128 | 3.2M |
Table2.1은 우리의 8개 모델의 크기와 아키텍처를 보여준다. 여기서는 학습 가능한 매개변수의 총수이고,는 층의 총수이며,는 각 bottleneck layer의 units 수이다(우리는 항상 feedforward layer를 bottleneck layer 크기의 네 배로 둔다, ), 그리고는 각 attention head의 차원이다. 모든 모델은tokens의 context window를 사용한다. 우리는 노드 간 data-transfer를 최소화하기 위해 depth와 width 차원 모두를 따라 모델을 GPUs에 분할한다. 각 모델의 정확한 아키텍처 매개변수는 computational efficiency와 GPU들에 걸친 모델 배치의 load-balancing을 바탕으로 선택된다. 이전 연구는[57]validation loss가 합리적으로 넓은 범위 안에서 이러한 매개변수들에 크게 민감하지 않음을 시사한다.
2.2 학습 데이터셋
언어 모델용 데이터셋은 빠르게 확장되어, Common Crawl dataset에 이르렀다222https://commoncrawl.org/the-data/ [116]이는 거의 1조 단어를 구성한다. 이 크기의 데이터셋은 동일한 시퀀스를 두 번 업데이트하지 않고도 우리의 가장 큰 모델을 학습시키기에 충분하다. 그러나 우리는 필터링되지 않았거나 가볍게 필터링된 Common Crawl 버전이 더 curated된 데이터셋보다 품질이 낮은 경향이 있음을 발견했다. 따라서 우리는 데이터셋의 평균 품질을 향상시키기 위해 3단계를 취했다: (1) 우리는 고품질 reference corpora 범위와의 유사성에 기반하여 CommonCrawl 버전을 다운로드하고 필터링했으며, (2) 중복을 방지하고 held-out validation set의 무결성을 overfitting의 정확한 측정으로 보존하기 위해 문서 수준에서, 데이터셋 내부와 데이터셋 간에 fuzzy deduplication을 수행했고, (3) CommonCrawl을 보강하고 그 다양성을 증가시키기 위해 알려진 고품질 reference corpora도 training mix에 추가했다.
첫 두 지점(Common Crawl 처리)의 세부 사항은 Appendix에 설명되어 있다A. 세 번째에 대해서는, 우리는 WebText dataset의 확장 버전을 포함하여 여러 curated high-quality datasets를 추가했다[117], 이는 더 긴 기간 동안 링크를 scraping하여 수집되었고, 처음으로[57]에서 설명되었으며, 두 개의 인터넷 기반 books corpora(Books1 및 Books2)와 English-language Wikipedia도 추가했다.
Table2.2은 우리가 학습에 사용한 최종 데이터셋 혼합을 보여준다. CommonCrawl 데이터는 2016년부터 2019년까지를 포괄하는 월별 CommonCrawl의 41개 shards에서 다운로드되었으며, 필터링 전에는 45TB의 압축된 plaintext, 필터링 후에는 570GB로 구성되어, 대략 4,000억 byte-pair-encoded tokens에 해당한다. 학습 중에는 데이터셋이 그 크기에 비례하여 샘플링되지 않고, 우리가 더 높은 품질로 보는 데이터셋이 더 자주 샘플링된다. 따라서 CommonCrawl과 Books2 데이터셋은 학습 중 한 번 미만으로 샘플링되지만, 다른 데이터셋들은 2-3번 샘플링된다. 이는 본질적으로 더 높은 품질의 학습 데이터를 얻는 대가로 적은 양의 overfitting을 받아들이는 것이다.
| Dataset | Quantity (tokens) | Weight in training mix | Epochs elapsed when training for 300B tokens |
|---|---|---|---|
| Common Crawl (filtered) | 410 billion | 60% | 0.44 |
| WebText2 | 19 billion | 22% | 2.9 |
| Books1 | 12 billion | 8% | 1.9 |
| Books2 | 55 billion | 8% | 0.43 |
| Wikipedia | 3 billion | 3% | 3.4 |
인터넷 데이터의 넓은 범위에서 사전 학습된 언어 모델, 특히 방대한 양의 콘텐츠를 암기할 수 있는 용량을 가진 대형 모델의 주요 방법론적 우려는 downstream tasks의 test 또는 development sets가 사전 학습 중에 의도치 않게 보임으로써 발생하는 잠재적 contamination이다. 그러한 contamination을 줄이기 위해, 우리는 이 논문에서 연구한 모든 벤치마크의 development 및 test sets와의 모든 overlaps를 찾아 제거하려고 시도했다. 불행히도, 필터링의 버그로 인해 일부 overlaps를 무시하게 되었고, 학습 비용 때문에 모델을 다시 학습시키는 것은 실현 가능하지 않았다. Section에서4.1우리는 남아 있는 overlaps의 영향을 특성화하며, 향후 연구에서는 data contamination을 더 공격적으로 제거할 것이다.
2.3 학습 과정
에서 발견된 바와 같이[57, 85], 더 큰 모델은 일반적으로 더 큰 batch size를 사용할 수 있지만, 더 작은 learning rate를 필요로 한다. 우리는 학습 중 gradient noise scale을 측정하고 이를 batch size 선택의 지침으로 사용한다[85]. Table2.1은 우리가 사용한 매개변수 설정을 보여준다. 더 큰 모델을 메모리 부족 없이 학습시키기 위해, 우리는 각 matrix multiply 내부의 model parallelism과 네트워크의 층들에 걸친 model parallelism의 혼합을 사용한다. 모든 모델은 Microsoft가 제공한 high-bandwidth cluster의 일부에 있는 V100 GPU들에서 학습되었다. 학습 과정과 hyperparameter settings의 세부 사항은 Appendix에 설명되어 있다B.
2.4 평가
few-shot learning의 경우, 우리는 evaluation set의 각 예시를 평가할 때 무작위로개의 예시를 해당 과제의 training set에서 conditioning으로 뽑으며, 과제에 따라 1개 또는 2개의 newlines로 구분한다. LAMBADA와 Storycloze에는 사용할 수 있는 지도 training set이 없으므로 development set에서 conditioning examples를 뽑고 test set에서 평가한다. Winograd(원본, SuperGLUE 버전이 아님)의 경우에는 하나의 데이터셋만 있으므로, conditioning examples를 그 데이터셋에서 직접 뽑는다.
는 0부터 모델의 context window가 허용하는 최대량까지의 어떤 값이든 될 수 있으며, 이는이고 모든 모델에서 일반적으로에서개의 예시가 들어간다. 더 큰 값의이 보통, 하지만 항상은 아니고, 더 좋으므로, 별도의 development 및 test set이 사용 가능할 때 우리는 development set에서 몇 가지값을 실험한 다음 test set에서 최상의 값을 실행한다. 일부 과제의 경우(Appendix 참조G) 우리는 demonstrations에 추가하여(또는, demonstrations 대신) 자연어 prompt도 사용한다.
여러 옵션 중 하나의 올바른 completion을 선택하는 과제(multiple choice)에서는, 우리는개의 context plus correct completion 예시를 제공한 뒤, context만 있는 하나의 예시를 제공하고, 각 completion의 LM likelihood를 비교한다. 대부분의 과제에서는 per-token likelihood를 비교하지만(길이에 대해 정규화하기 위해), 소수의 데이터셋(ARC, OpenBookQA, RACE)에서는 development set에서 측정했을 때 각 completion의 unconditional probability로 정규화하여 추가 이득을 얻는데, 이는를 계산함으로써 이루어지며, 여기서는 문자열"Answer: "또는"A: "이고, completion이 답이어야 함을 prompt하는 데 사용되지만 그 외에는 generic하다.
binary classification을 포함하는 과제에서는, 우리는 옵션들에 더 의미론적으로 의미 있는 이름(예: 0 또는 1이 아니라 “True” 또는 “False”)을 부여한 다음 그 과제를 multiple choice처럼 처리한다. 또한 때때로 과제를[116]에서 수행된 것과 유사하게 구성한다(자세한 내용은 AppendixG) 참조.
free-form completion이 포함된 과제에서는, 우리는[116]와 동일한 매개변수로 beam search를 사용한다: beam width 4와 length penalty. 우리는 해당 데이터셋에서 표준인 것에 따라 F1 similarity score, BLEU, 또는 exact match를 사용하여 모델을 채점한다.
최종 결과는 공개적으로 사용 가능할 때 test set에서, 각 model size와 learning setting(zero-, one-, few-shot)에 대해 보고된다. test set이 private인 경우, 우리의 모델은 종종 test server에 맞기에는 너무 크므로 development set의 결과를 보고한다. 우리는 submission이 작동하도록 할 수 있었던 소수의 데이터셋(SuperGLUE, TriviaQA, PiQa)에 대해서는 test server에 제출하며, 200B few-shot 결과만 제출하고, 그 밖의 모든 것에 대해서는 development set 결과를 보고한다.
3 결과
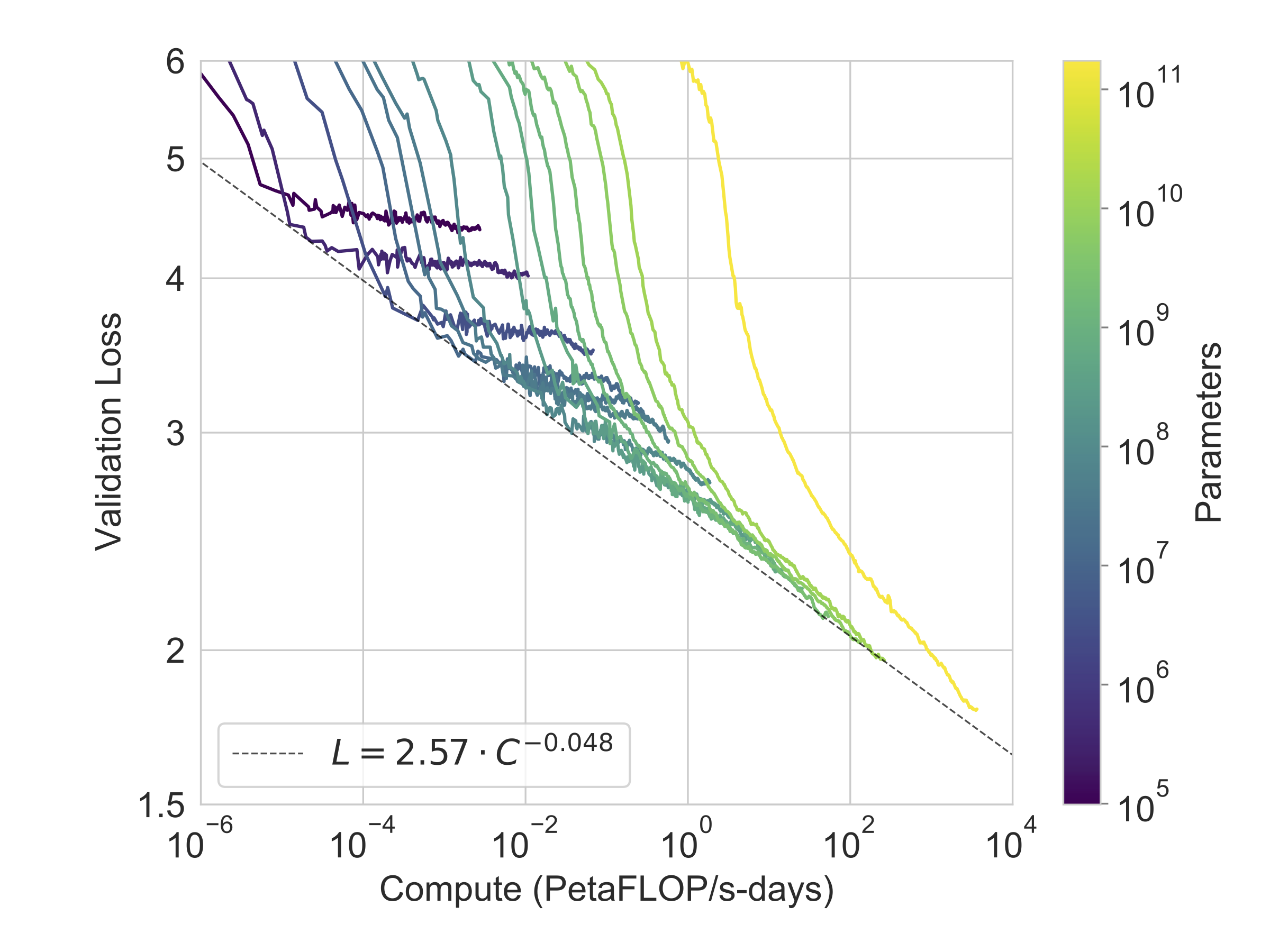
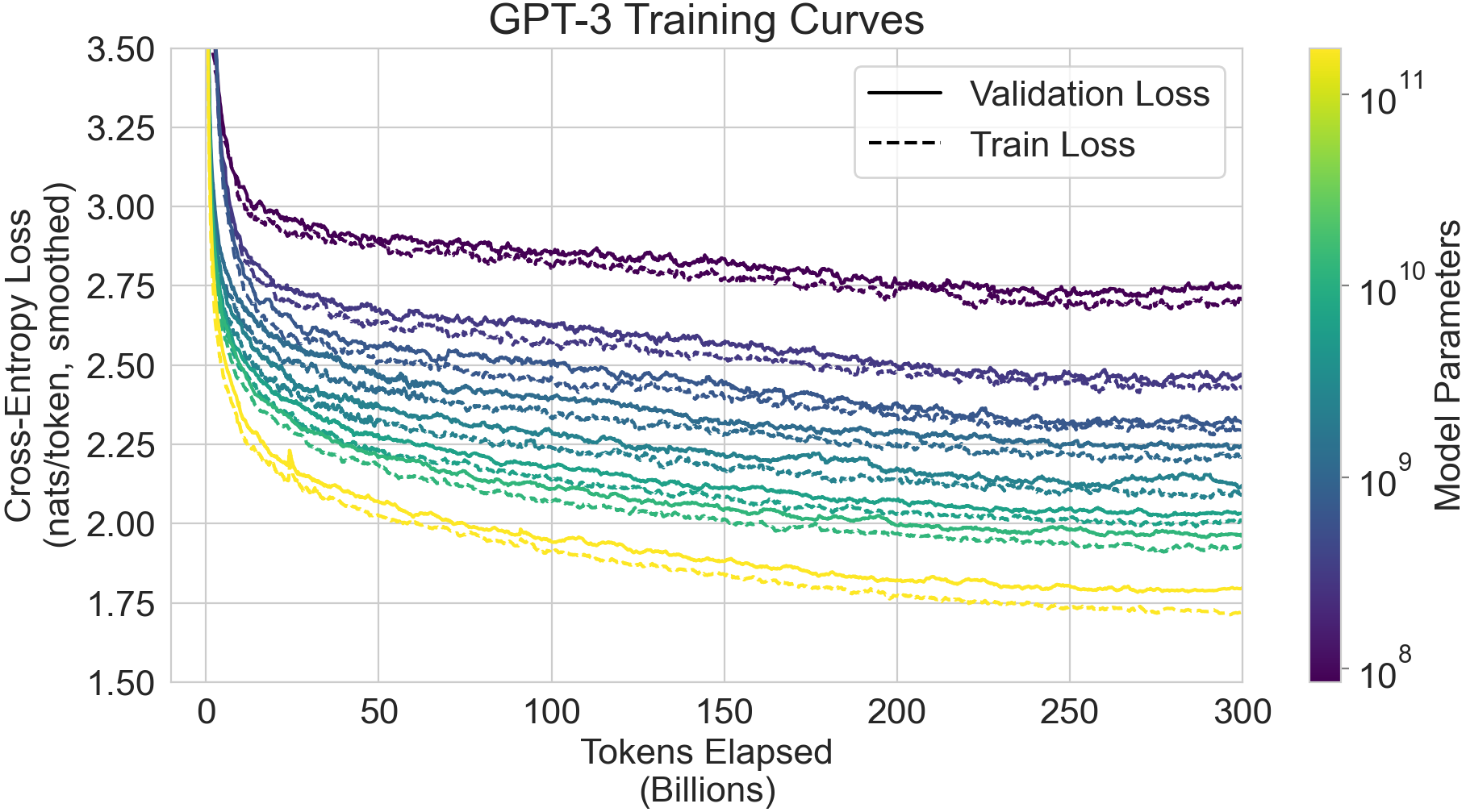
그림에서3.1우리는 섹션에서 설명한 8개 모델에 대한 훈련 곡선을 표시한다2. 이 그래프에는 또한 매개변수가 100,000개에 불과한 6개의 추가 extra-small 모델도 포함한다. 에서 관찰된 바와 같이[57], 언어 모델링 성능은 훈련 compute를 효율적으로 사용할 때 power-law를 따른다. 이 추세를 두 자릿수 더 확장한 후, 우리는 power-law에서 약간의(있다면) 이탈만을 관찰한다. 이러한 cross-entropy loss의 개선이 우리의 훈련 말뭉치의 가짜 세부사항을 모델링하는 데서만 오는 것이라고 우려할 수도 있다. 그러나 다음 섹션들에서 보겠지만, cross-entropy loss의 개선은 광범위한 자연어 태스크 전반에서 일관된 성능 향상으로 이어진다.
아래에서, 우리는 섹션에서 설명한 8개 모델을 평가한다2(175 billion parameter GPT-3와 7개의 더 작은 모델) 다양한 데이터셋에서. 우리는 대략 유사한 태스크를 나타내는 9개 범주로 데이터셋을 묶는다.
섹션에서3.1우리는 전통적인 언어 모델링 태스크와 Cloze 태스크 및 문장/문단 완성 태스크처럼 언어 모델링과 유사한 태스크를 평가한다. 섹션에서3.2우리는 “closed book” 질문 응답 태스크를 평가한다: 일반 지식 질문에 답하기 위해 모델의 매개변수에 저장된 정보를 사용해야 하는 태스크이다. 섹션에서3.3우리는 언어 간 번역 능력(특히 one-shot 및 few-shot)을 평가한다. 섹션에서3.4우리는 Winograd Schema와 유사한 태스크에서 모델의 성능을 평가한다. 섹션에서3.5우리는 commonsense reasoning 또는 질문 응답을 포함하는 데이터셋에서 평가한다. 섹션에서3.6우리는 reading comprehension 태스크를 평가하고, 섹션에서3.7우리는 SuperGLUE benchmark suite에서 평가하며, 그리고3.8우리는 NLI를 간단히 탐구한다. 마지막으로, 섹션에서3.9, 우리는 특히 in-context learning 능력을 조사하도록 설계된 몇 가지 추가 태스크를 고안한다 – 이 태스크들은 즉석 추론, 적응 기술, 또는 개방형 텍스트 합성에 초점을 맞춘다. 우리는 모든 태스크를 few-shot, one-shot, zero-shot 설정에서 평가한다.
3.1 언어 모델링, Cloze, 및 완성 태스크
이 섹션에서 우리는 전통적인 언어 모델링 태스크에서 GPT-3의 성능을 테스트하며, 관심 있는 단일 단어를 예측하거나, 문장 또는 문단을 완성하거나, 텍스트 조각의 가능한 완성들 중에서 선택하는 관련 태스크들도 테스트한다.
3.1.1 언어 모델링
우리는 Penn Tree Bank (PTB)에서 zero-shot perplexity를 계산한다[86]에서 측정된 데이터셋[117]. 우리는 그 작업의 4개 Wikipedia 관련 태스크를 생략하는데, 그것들이 우리의 훈련 데이터에 완전히 포함되어 있기 때문이며, 또한 데이터셋의 높은 비율이 우리의 훈련 세트에 포함되어 있기 때문에 one-billion word benchmark도 생략한다. PTB는 현대 인터넷보다 앞서 존재했기 때문에 이러한 문제를 피한다. 우리의 가장 큰 모델은 PTB에서 15점이라는 상당한 차이로 새로운 SOTA를 세우며, perplexity 20.50을 달성한다. PTB는 전통적인 언어 모델링 데이터셋이므로 one-shot 또는 few-shot 평가를 정의할 명확한 예제 분리가 없다는 점에 유의하라. 따라서 우리는 zero-shot만 측정한다.
| 설정 | PTB |
|---|---|
| SOTA (Zero-Shot) | 35.8a |
| GPT-3 Zero-Shot | 20.5 |
3.1.2 LAMBADA
| 설정 | LAMBADA (acc) | LAMBADA (ppl) | StoryCloze (acc) | HellaSwag (acc) |
|---|---|---|---|---|
| SOTA | 68.0a | 8.63b | 91.8c | 85.6d |
| GPT-3 Zero-Shot | 76.2 | 3.00 | 83.2 | 78.9 |
| GPT-3 One-Shot | 72.5 | 3.35 | 84.7 | 78.1 |
| GPT-3 Few-Shot | 86.4 | 1.92 | 87.7 | 79.3 |
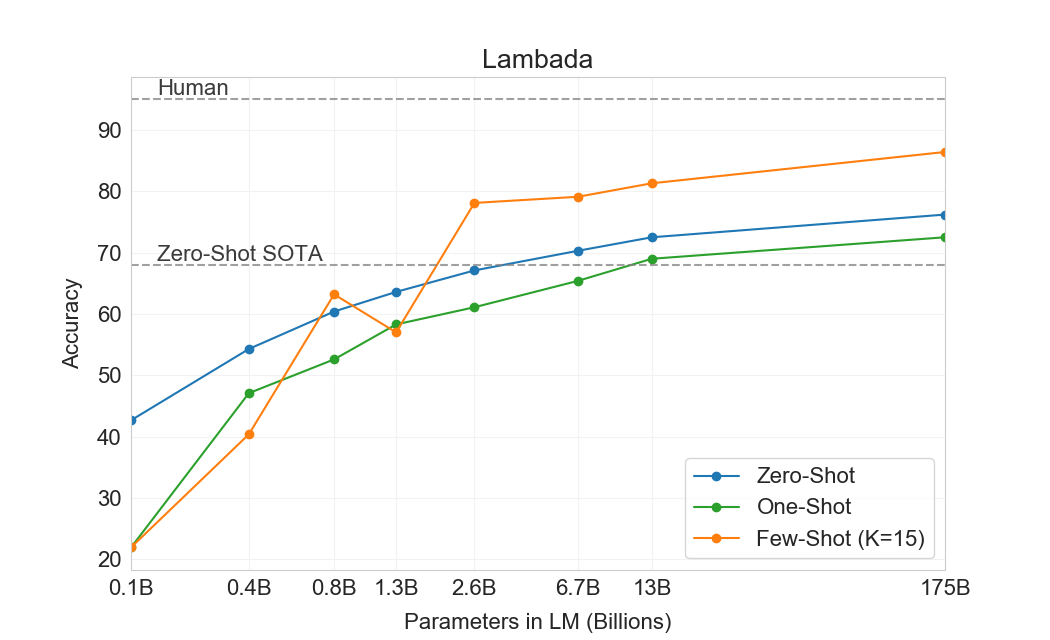
LAMBADA 데이터셋은[99]텍스트에서 장거리 의존성의 모델링을 테스트한다 – 모델은 문맥의 한 문단을 읽어야 하는 문장의 마지막 단어를 예측하도록 요구된다. 최근에는 언어 모델의 지속적인 스케일링이 이 어려운 benchmark에서 수확 체감을 낳고 있다는 제안이 있었다.[9]두 최근 state of the art 결과 사이에서 모델 크기를 두 배로 늘려 달성한 작은 1.5% 개선을 되돌아보고 ([125]및[132]) “하드웨어와 데이터 크기를 계속해서 orders of magnitude만큼 확장하는 것은 앞으로 나아갈 길이 아니다”라고 주장한다. 우리는 그 길이 여전히 유망하다고 보며, zero-shot 설정에서 GPT-3는 LAMBADA에서 76%를 달성하여 이전 state of the art보다 8% 향상된다.
LAMBADA는 또한 이 데이터셋에서 고전적으로 발생하는 문제를 다루는 방법을 제공하므로 few-shot learning의 유연성을 보여주는 사례이기도 하다. LAMBADA의 완성은 항상 문장의 마지막 단어이지만, 표준 언어 모델은 이 세부사항을 알 방법이 없다. 따라서 올바른 끝맺음뿐만 아니라 문단의 다른 유효한 이어짐에도 확률을 할당한다. 이 문제는 과거에 stop-word filters로 부분적으로 다루어졌다[117](이는 “continuation” 단어를 금지한다). 대신 few-shot 설정은 우리가 태스크를 cloze-test로 “frame”할 수 있게 하고, 언어 모델이 예제로부터 정확히 한 단어의 완성이 요구된다는 것을 추론할 수 있게 한다. 우리는 다음 fill-in-the-blank 형식을 사용한다:
Alice는 Bob과 친구였다. Alice는 그녀의 친구를 방문하러 갔다 . Bob
George는 야구 장비, 공, 글러브, 그리고 하나의 .
이러한 방식으로 형식화된 예제가 제시되면, GPT-3는 few-shot 설정에서 86.4% accuracy를 달성하며, 이는 이전 state-of-the-art보다 18% 넘게 증가한 것이다. 우리는 few-shot 성능이 모델 크기와 함께 강하게 향상됨을 관찰한다. 이 설정은 가장 작은 모델의 성능을 거의 20% 감소시키지만, GPT-3의 경우 accuracy를 10% 향상시킨다. 마지막으로, fill-in-blank 방법은 one-shot에서는 효과적이지 않으며, 항상 zero-shot 설정보다 나쁘게 수행된다. 아마도 이는 모든 모델이 여전히 패턴을 인식하기 위해 여러 예제를 필요로 하기 때문일 수 있다.
주의할 점 하나는 test set contamination 분석에서 LAMBADA 데이터셋의 상당한 소수가 우리의 훈련 데이터에 존재하는 것으로 보인다는 것이 확인되었다는 점이다 – 그러나 섹션에서 수행된 분석은4.1성능에 미치는 영향이 무시할 만하다고 시사한다.
3.1.3 HellaSwag
HellaSwag 데이터셋은[140]이야기나 지시문 집합에 대한 가장 좋은 끝맺음을 고르는 것을 포함한다. 예제들은 사람에게는 쉬운 상태(사람은 95.6% accuracy를 달성함)를 유지하면서 언어 모델에게 어렵도록 adversarially mined되었다. GPT-3는 one-shot 설정에서 78.1% accuracy, few-shot 설정에서 79.3% accuracy를 달성하여, fine-tuned 1.5B parameter 언어 모델의 75.4% accuracy를 능가한다[141]그러나 fine-tuned multi-task model ALUM이 달성한 전체 SOTA 85.6%보다는 여전히 상당히 낮다.
3.1.4 StoryCloze
3.2 Closed Book 질문 응답
| 설정 | NaturalQS | WebQS | TriviaQA |
|---|---|---|---|
| RAG (Fine-tuned, Open-Domain)[75] | 44.5 | 45.5 | 68.0 |
| T5-11B+SSM (Fine-tuned, Closed-Book)[115] | 36.6 | 44.7 | 60.5 |
| T5-11B (Fine-tuned, Closed-Book) | 34.5 | 37.4 | 50.1 |
| GPT-3 Zero-Shot | 14.6 | 14.4 | 64.3 |
| GPT-3 One-Shot | 23.0 | 25.3 | 68.0 |
| GPT-3 Few-Shot | 29.9 | 41.5 | 71.2 |
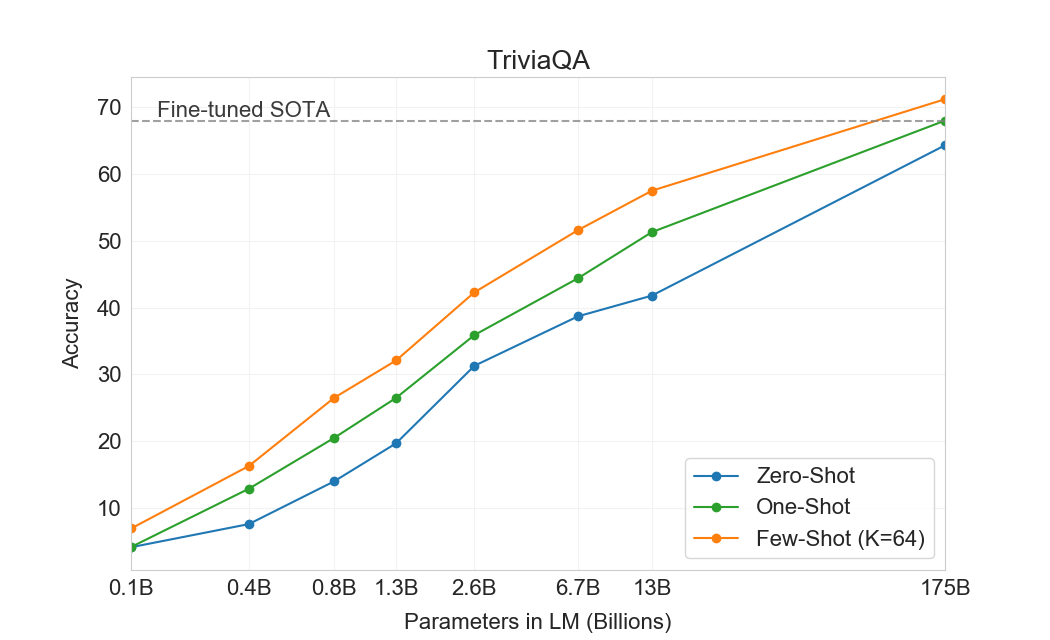
이 섹션에서 우리는 광범위한 사실 지식에 관한 질문에 답하는 GPT-3의 능력을 측정한다. 가능한 질의의 양이 방대하기 때문에, 이 태스크는 보통 관련 텍스트를 찾기 위해 정보 검색 시스템을 사용하고, 질문과 검색된 텍스트가 주어졌을 때 답을 생성하도록 학습하는 모델과 결합하는 방식으로 접근되어 왔다. 이 설정은 시스템이 잠재적으로 답을 포함하는 텍스트를 검색하고 그 텍스트에 조건화할 수 있게 하므로 “open-book”이라고 불린다.[115]최근에 큰 언어 모델이 보조 정보에 조건화하지 않고 직접 질문에 답하는 데 놀라울 정도로 잘 수행할 수 있음을 보여주었다. 그들은 이 더 제한적인 평가 설정을 “closed-book”이라고 부른다. 그들의 작업은 더 높은 용량의 모델이 더 잘 수행할 수도 있음을 시사하며, 우리는 GPT-3로 이 가설을 테스트한다. 우리는 GPT-3를 의 3개 데이터셋에서 평가한다[115]: Natural Questions[58], WebQuestions[5], 그리고 TriviaQA[49], 동일한 split을 사용한다. 모든 결과가 closed-book 설정에 있을 뿐만 아니라, 우리의 few-shot, one-shot, zero-shot 평가 사용은 이전 closed-book QA 작업보다 훨씬 더 엄격한 설정을 나타낸다는 점에 유의하라: 외부 콘텐츠가 허용되지 않는 것에 더해, Q&A 데이터셋 자체에 대한 fine-tuning도 허용되지 않는다.
GPT-3에 대한 결과는 Table에 표시되어 있다3.3. TriviaQA에서 우리는 zero-shot 설정에서 64.3%, one-shot 설정에서 68.0%, few-shot 설정에서 71.2%를 달성한다. zero-shot 결과는 이미 fine-tuned T5-11B보다 14.2% 더 우수하며, 또한 Q&A 맞춤형 span prediction을 pre-training 동안 사용한 버전보다 3.8% 더 우수하다. one-shot 결과는 3.7% 향상되며, fine-tuning할 뿐만 아니라 21M 문서의 15.3B parameter dense vector index에 대한 학습된 retrieval mechanism도 사용하는 open-domain QA system의 SOTA와 일치한다[75]. GPT-3의 few-shot 결과는 이를 넘어 성능을 추가로 3.2% 더 향상시킨다.
WebQuestions (WebQs)에서 GPT-3는 zero-shot 설정에서 14.4%, one-shot 설정에서 25.3%, few-shot 설정에서 41.5%를 달성한다. 이는 fine-tuned T5-11B의 37.4%, 그리고 Q&A-specific pre-training procedure를 사용하는 fine-tuned T5-11B+SSM의 44.7%와 비교된다. few-shot 설정의 GPT-3는 state-of-the-art fine-tuned 모델의 성능에 접근한다. 특히 TriviaQA와 비교할 때, WebQS는 zero-shot에서 few-shot으로 훨씬 더 큰 향상을 보이며(실제로 zero-shot 및 one-shot 성능은 나쁘다), 이는 WebQs 질문 및/또는 답변의 스타일이 GPT-3에 대해 out-of-distribution임을 시사할 수 있다. 그럼에도 불구하고 GPT-3는 이 분포에 적응할 수 있는 것으로 보이며, few-shot 설정에서 강한 성능을 회복한다.
Natural Questions (NQs)에서 GPT-3는 zero-shot 설정에서 14.6%, one-shot 설정에서 23.0%, few-shot 설정에서 29.9%를 달성하며, fine-tuned T5 11B+SSM의 36.6%와 비교된다. WebQS와 유사하게, zero-shot에서 few-shot으로의 큰 향상은 distribution shift를 시사할 수 있으며, TriviaQA 및 WebQS와 비교해 덜 경쟁적인 성능을 설명할 수도 있다. 특히 NQs의 질문은 Wikipedia에 특화된 매우 세밀한 지식 쪽으로 기울어져 있어, GPT-3의 용량과 광범위한 pretraining 분포의 한계를 시험하고 있을 수 있다.
3.3 번역
GPT-2의 경우 용량 우려 때문에 다국어 문서 모음에 필터를 사용하여 영어 전용 데이터셋을 생성했다. 이러한 필터링에도 불구하고 GPT-2는 다국어 능력의 일부 증거를 보였고, 남아 있는 프랑스어 텍스트 10 megabytes만으로 훈련했음에도 프랑스어와 영어 간 번역에서 사소하지 않은 성능을 보였다. 우리는 GPT-2에서 GPT-3로 용량을 두 자릿수 이상 증가시키므로, 훈련 데이터셋의 범위도 확장하여 다른 언어의 표현을 더 포함하지만, 이는 여전히 추가 개선의 영역으로 남아 있다. 에서 논의한 바와 같이2.2우리 데이터의 대부분은 품질 기반 필터링만 거친 raw Common Crawl에서 파생된다. GPT-3의 훈련 데이터는 여전히 주로 영어(단어 수 기준 93%)이지만, 다른 언어의 텍스트도 7% 포함한다. 이 언어들은 에 문서화되어 있다supplemental material. 번역 능력을 더 잘 이해하기 위해, 우리는 분석을 확장하여 일반적으로 연구되는 두 개의 추가 언어인 독일어와 루마니아어도 포함한다.
기존의 unsupervised machine translation 접근법은 종종 단일언어 데이터셋 쌍에 대한 pretraining과 back-translation을 결합한다[123]두 언어를 통제된 방식으로 연결하기 위해. 대조적으로, GPT-3는 많은 언어를 자연스럽게 섞은 훈련 데이터의 혼합으로부터 학습하며, 단어, 문장, 문서 수준에서 이들을 결합한다. GPT-3는 또한 특정 태스크에 맞춤화되거나 설계되지 않은 단일 훈련 objective를 사용한다. 그러나 우리의 one / few-shot 설정은 소량의 paired examples(1 또는 64)를 사용하기 때문에 이전 unsupervised 작업과 엄밀히 비교 가능하지는 않다. 이는 최대 한두 페이지의 in-context training data에 해당한다.
| 설정 | EnFr | FrEn | EnDe | DeEn | EnRo | RoEn |
|---|---|---|---|---|---|---|
| SOTA (Supervised) | 45.6a | 35.0 b | 41.2c | 40.2d | 38.5e | 39.9e |
| XLM[61] | 33.4 | 33.3 | 26.4 | 34.3 | 33.3 | 31.8 |
| MASS[127] | 37.5 | 34.9 | 28.3 | 35.2 | 35.2 | 33.1 |
| mBART[66] | - | - | 29.8 | 34.0 | 35.0 | 30.5 |
| GPT-3 Zero-Shot | 25.2 | 21.2 | 24.6 | 27.2 | 14.1 | 19.9 |
| GPT-3 One-Shot | 28.3 | 33.7 | 26.2 | 30.4 | 20.6 | 38.6 |
| GPT-3 Few-Shot | 32.6 | 39.2 | 29.7 | 40.6 | 21.0 | 39.5 |
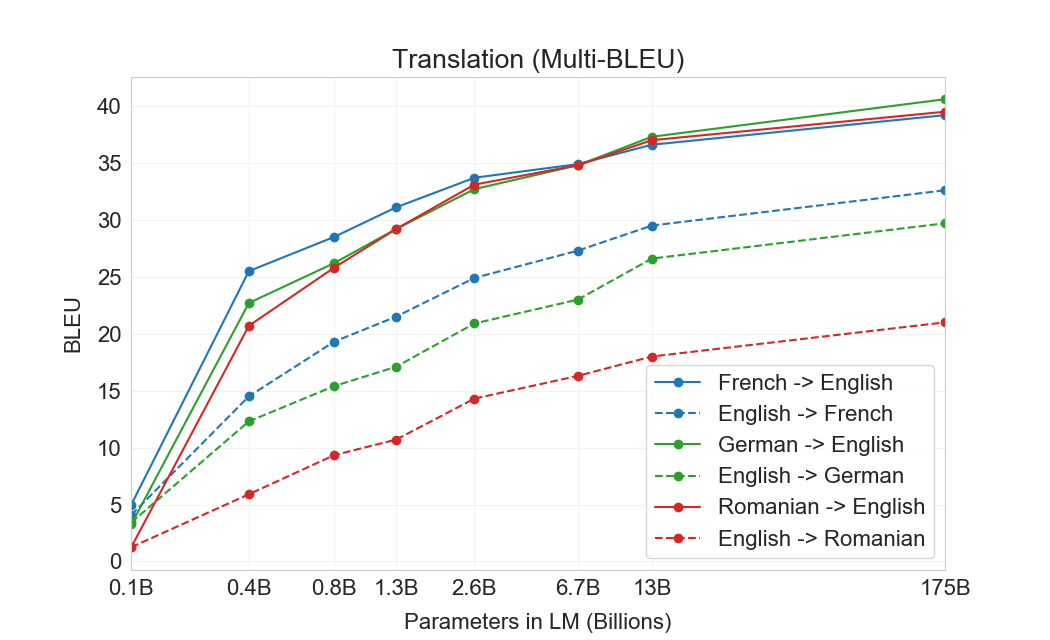
결과는 Table에 표시되어 있다3.4. 태스크에 대한 자연어 설명만 받는 Zero-shot GPT-3는 여전히 최근 unsupervised NMT 결과보다 성능이 낮다. 그러나 각 번역 태스크에 대해 단 하나의 예시 demonstration만 제공해도 성능이 7 BLEU 넘게 향상되어 이전 작업과 경쟁적인 성능에 가까워진다. full few-shot 설정의 GPT-3는 추가로 4 BLEU 더 향상되어 이전 unsupervised NMT 작업과 유사한 평균 성능을 낸다. GPT-3는 언어 방향에 따라 성능에서 눈에 띄는 편향을 가진다. 연구된 세 입력 언어에 대해, GPT-3는 영어로 번역할 때 이전 unsupervised NMT 작업을 크게 능가하지만 반대 방향으로 번역할 때는 성능이 낮다. En-Ro에서의 성능은 이전 unsupervised NMT 작업보다 10 BLEU 넘게 낮아 눈에 띄는 outlier이다. 이는 거의 전적으로 영어 훈련 데이터셋을 위해 개발된 GPT-2의 byte-level BPE tokenizer를 재사용한 데 따른 약점일 수 있다. Fr-En과 De-En 모두에서 few shot GPT-3는 우리가 찾을 수 있었던 최고의 supervised 결과보다 우수하지만, 문헌에 대한 우리의 익숙하지 않음과 이들이 경쟁적이지 않은 benchmarks로 보인다는 점 때문에, 우리는 그 결과들이 진정한 state of the art를 나타낸다고 의심하지 않는다. Ro-En의 경우 few shot GPT-3는 unsupervised pretraining, 608K labeled examples에 대한 supervised finetuning, 그리고 backtranslation의 조합으로 달성된 전체 SOTA의 0.5 BLEU 이내에서 수행된다[70].
3.4 Winograd-Style 태스크
| 설정 | Winograd | Winogrande (XL) |
|---|---|---|
| Fine-tuned SOTA | 90.1a | 84.6b |
| GPT-3 Zero-Shot | 88.3* | 70.2 |
| GPT-3 One-Shot | 89.7* | 73.2 |
| GPT-3 Few-Shot | 88.6* | 77.7 |
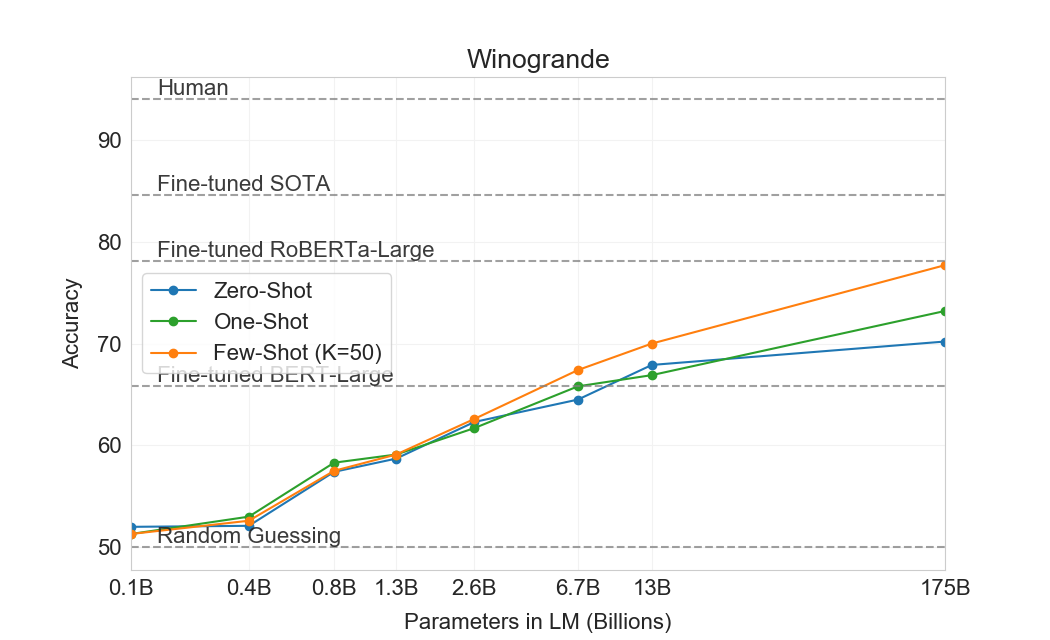
Winograd Schemas Challenge는[65]NLP의 고전적 태스크로, 대명사가 문법적으로는 모호하지만 사람에게는 의미적으로 명확할 때 그 대명사가 어떤 단어를 가리키는지 결정하는 것을 포함한다. 최근 fine-tuned language models는 원래 Winograd 데이터셋에서 거의 인간 수준의 성능을 달성했지만, adversarially-mined Winogrande 데이터셋과 같은 더 어려운 버전은[118]여전히 인간 성능에 크게 뒤처진다. 우리는 평소처럼 zero-, one-, few-shot 설정에서 Winograd와 Winogrande 모두에 대한 GPT-3의 성능을 테스트한다.
Winograd에서 우리는 에 설명된 동일한 “partial evaluation” 방법을 사용하여 원래 273개 Winograd schemas 세트에서 GPT-3를 테스트한다[117]. 이 설정은 SuperGLUE benchmark의 WSC 태스크와 약간 다르다는 점에 유의하라. WSC는 binary classification으로 제시되며, 이 섹션에서 설명한 형태로 변환하기 위해 entity extraction이 필요하다. Winograd에서 GPT-3는 zero-shot, one-shot, few-shot 설정에서 각각 88.3%, 89.7%, 88.6%를 달성하여 명확한 in-context learning은 보이지 않지만, 모든 경우에 state-of-the-art 및 추정 인간 성능보다 몇 점 낮은 강한 결과를 달성한다. 우리는 contamination 분석에서 일부 Winograd schemas가 훈련 데이터에서 발견되었지만 이것이 결과에 미치는 영향은 작은 것으로 보인다는 점에 주목한다 (Section 참조4.1).
더 어려운 Winogrande 데이터셋에서는 in-context learning의 이득을 발견한다: GPT-3는 zero-shot 설정에서 70.2%, one-shot 설정에서 73.2%, few-shot 설정에서 77.7%를 달성한다. 비교를 위해 fine-tuned RoBERTA 모델은 79%를 달성하고, state-of-the-art는 fine-tuned high capacity model (T5)로 달성한 84.6%이며, 에 의해 보고된 이 태스크의 인간 성능은[118]94.0%이다.
3.5 상식 추론
| 설정 | PIQA | ARC (Easy) | ARC (Challenge) | OpenBookQA |
|---|---|---|---|---|
| Fine-tuned SOTA | 79.4 | 92.0[55] | 78.5[55] | 87.2[55] |
| GPT-3 Zero-Shot | 80.5* | 68.8 | 51.4 | 57.6 |
| GPT-3 One-Shot | 80.5* | 71.2 | 53.2 | 58.8 |
| GPT-3 Few-Shot | 82.8* | 70.1 | 51.5 | 65.4 |
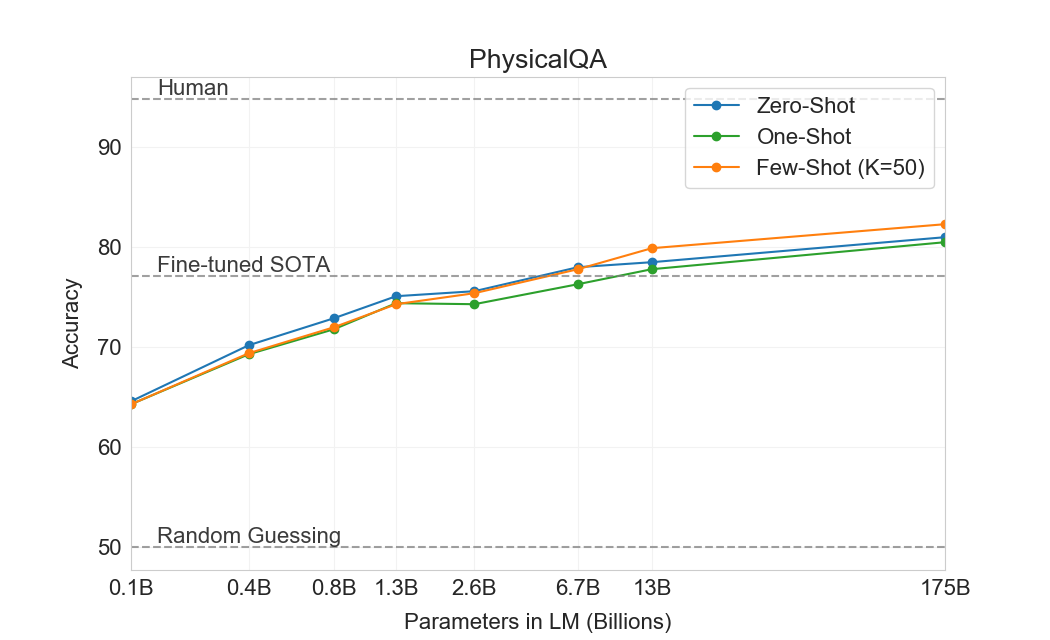
다음으로 우리는 문장 완성, reading comprehension, 또는 광범위한 지식 질문 응답과 구별되는 물리적 또는 과학적 추론을 포착하려고 시도하는 세 데이터셋을 고려한다. 첫 번째인 PhysicalQA (PIQA)는[11], 물리적 세계가 어떻게 작동하는지에 대한 상식 질문을 묻고, 세계에 대한 grounded understanding을 탐색하기 위한 것이다. GPT-3는 zero-shot에서 81.0% accuracy, one-shot에서 80.5% accuracy, few-shot에서 82.8% accuracy(마지막은 PIQA의 test server에서 측정)를 달성한다. 이는 fine-tuned RoBERTa의 이전 state-of-the-art 79.4% accuracy와 비교해 유리하다. PIQA는 모델 크기에 따른 비교적 얕은 scaling을 보이며 인간 성능보다 여전히 10% 넘게 나쁘지만, GPT-3의 few-shot 및 even zero-shot 결과는 현재 state-of-the-art를 능가한다. 우리의 분석은 PIQA를 잠재적 data contamination 문제로 표시했으며(숨겨진 test labels에도 불구하고), 따라서 우리는 보수적으로 결과에 별표를 표시한다. Section을 보라4.1자세한 내용은.
ARC[14]는 3학년부터 9학년까지의 과학 시험에서 수집한 multiple-choice questions 데이터셋이다. 간단한 통계적 방법이나 정보 검색 방법이 올바르게 답할 수 없는 질문으로 필터링된 데이터셋의 “Challenge” 버전에서, GPT-3는 zero-shot 설정에서 51.4% accuracy, one-shot 설정에서 53.2%, few-shot 설정에서 51.5%를 달성한다. 이는 UnifiedQA의 fine-tuned RoBERTa baseline(55.9%)의 성능에 접근한다[55]. 데이터셋의 “Easy” 버전(언급된 baseline 접근법 중 하나가 올바르게 답한 질문)에서, GPT-3는 68.8%, 71.2%, 70.1%를 달성하며, 이는 의 fine-tuned RoBERTa baseline을 약간 초과한다[55]. 그러나 이 두 결과 모두 전체 SOTA보다 여전히 훨씬 나쁘며, UnifiedQA가 달성한 전체 SOTA는 challenge set에서 GPT-3의 few-shot 결과를 27%, easy set에서 22% 초과한다.
OpenBookQA에서[84], GPT-3는 zero에서 few shot 설정으로 크게 향상되지만 여전히 전체 SOTA보다 20점 넘게 부족하다. GPT-3의 few-shot 성능은 leaderboard의 fine-tuned BERT Large baseline과 유사하다.
전반적으로, GPT-3를 사용한 in-context learning은 commonsense reasoning 태스크에서 혼재된 결과를 보이며, PIQA와 ARC 모두에서 one 및 few-shot learning 설정에서 작고 일관되지 않은 이득만 관찰되지만, OpenBookQA에서는 상당한 개선이 관찰된다. GPT-3는 새 PIQA 데이터셋의 모든 평가 설정에서 SOTA를 세운다.
3.6 Reading Comprehension
| 설정 | CoQA | DROP | QuAC | SQuADv2 | RACE-h | RACE-m |
|---|---|---|---|---|---|---|
| Fine-tuned SOTA | 90.7a | 89.1b | 74.4c | 93.0d | 90.0e | 93.1e |
| GPT-3 Zero-Shot | 81.5 | 23.6 | 41.5 | 59.5 | 45.5 | 58.4 |
| GPT-3 One-Shot | 84.0 | 34.3 | 43.3 | 65.4 | 45.9 | 57.4 |
| GPT-3 Few-Shot | 85.0 | 36.5 | 44.3 | 69.8 | 46.8 | 58.1 |
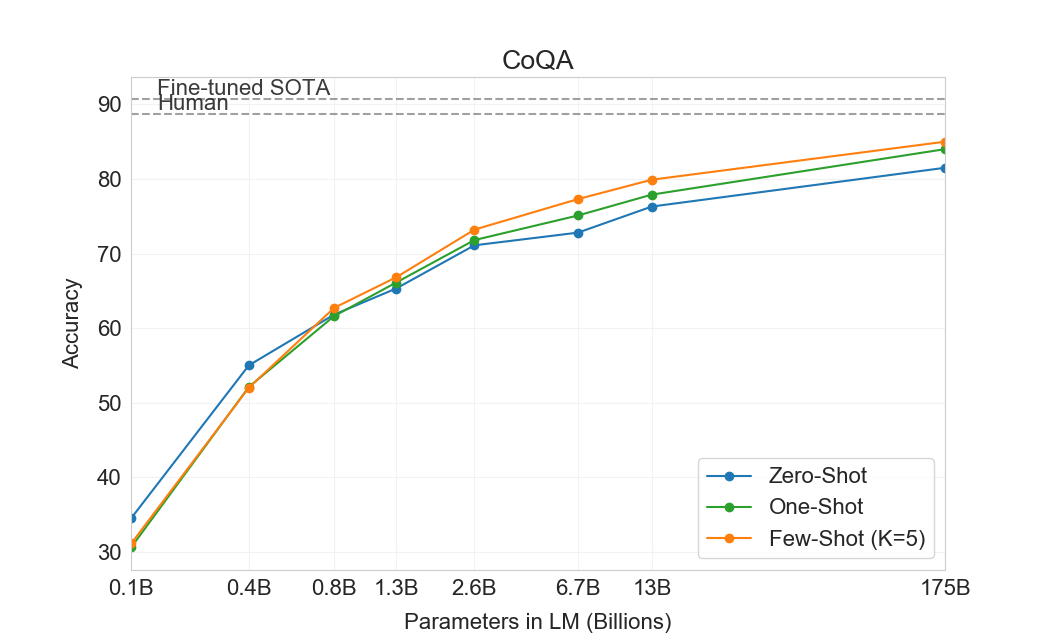
다음으로 우리는 읽기 이해 과제에서 GPT-3를 평가한다. 우리는 대화 및 단일 질문 설정 모두에서 추상적, 객관식, span 기반 답변 형식을 포함하는 5개 데이터셋 모음을 사용한다. 우리는 이러한 데이터셋 전반에서 GPT-3의 성능이 크게 분산되어 있음을 관찰하며, 이는 서로 다른 답변 형식에 대한 능력이 다양함을 시사한다. 일반적으로 우리는 GPT-3가 각 해당 데이터셋에서 contextual representations를 사용해 훈련된 초기 baseline 및 초기 결과와 동등한 수준임을 관찰한다.
GPT-3는 CoQA에서 가장 잘 수행한다(인간 baseline의 3점 이내)[106]자유 형식 대화형 데이터셋이며, QuAC에서는 가장 나쁘게 수행한다(ELMo baseline보다 13 F1 낮음)[16]교사-학생 상호작용의 구조화된 dialog act와 답변 span 선택을 모델링해야 하는 데이터셋이다. DROP에서[27], 읽기 이해의 맥락에서 이산 추론과 수리력을 테스트하는 데이터셋에서, few-shot 설정의 GPT-3는 원 논문의 fine-tuned BERT baseline을 능가하지만, 인간 성능과 신경망을 symbolic systems로 보강하는 state-of-the-art 접근법 모두에는 여전히 훨씬 못 미친다[110]. SQuAD 2.0에서[108], GPT-3는 zero-shot 설정과 비교해 거의 10 F1(69.8까지) 향상되며 few-shot learning 능력을 보여준다. 이를 통해 원 논문의 최고 fine-tuned 결과를 약간 능가할 수 있다. RACE에서[78], 중학교 및 고등학교 영어 시험의 객관식 데이터셋에서, GPT-3는 상대적으로 약하게 수행하며 contextual representations를 활용한 가장 초기 연구와만 경쟁 가능하고 여전히 SOTA보다 45% 뒤처진다.
| SuperGLUE | BoolQ | CB | CB | COPA | RTE | |
|---|---|---|---|---|---|---|
| 평균 | 정확도 | 정확도 | F1 | 정확도 | 정확도 | |
| Fine-tuned SOTA | 89.0 | 91.0 | 96.9 | 93.9 | 94.8 | 92.5 |
| Fine-tuned BERT-Large | 69.0 | 77.4 | 83.6 | 75.7 | 70.6 | 71.7 |
| GPT-3 Few-Shot | 71.8 | 76.4 | 75.6 | 52.0 | 92.0 | 69.0 |
| WiC | WSC | MultiRC | MultiRC | ReCoRD | ReCoRD | |
|---|---|---|---|---|---|---|
| 정확도 | 정확도 | 정확도 | F1a | 정확도 | F1 | |
| Fine-tuned SOTA | 76.1 | 93.8 | 62.3 | 88.2 | 92.5 | 93.3 |
| Fine-tuned BERT-Large | 69.6 | 64.6 | 24.1 | 70.0 | 71.3 | 72.0 |
| GPT-3 Few-Shot | 49.4 | 80.1 | 30.5 | 75.4 | 90.2 | 91.1 |
3.7 SuperGLUE
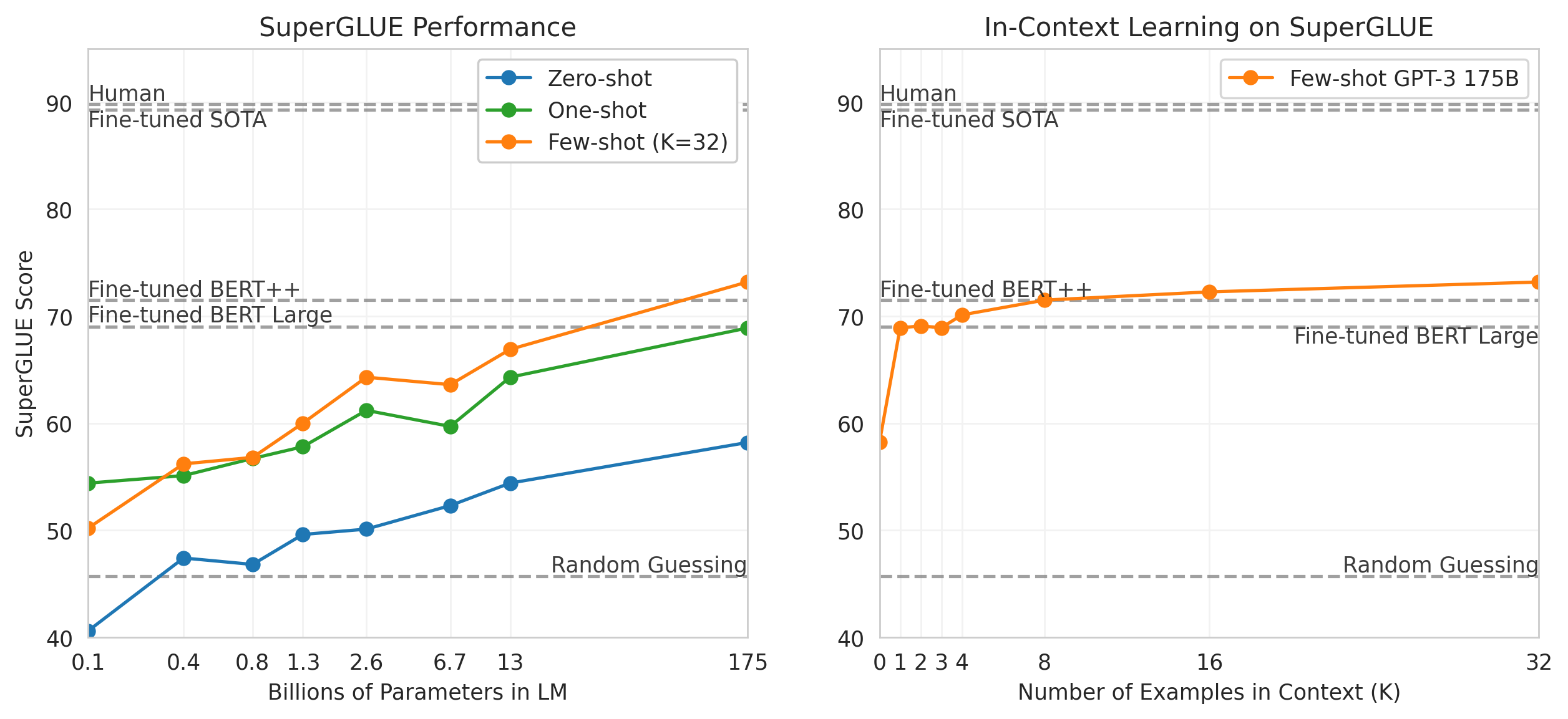
NLP 과제의 결과를 더 잘 집계하고 BERT 및 RoBERTa와 같은 인기 모델과 더 체계적인 방식으로 비교하기 위해, 우리는 또한 표준화된 데이터셋 모음인 SuperGLUE benchmark에서 GPT-3를 평가한다[135] [135] [17] [25] [105] [54] [142] [21] [8] [34] [6] [96] [98]. SuperGLUE 데이터셋에서 GPT-3의 test-set 성능은 Table에 나와 있다3.8. few-shot 설정에서 우리는 모든 과제에 대해 training set에서 무작위로 샘플링한 32개 예제를 사용했다. WSC와 MultiRC를 제외한 모든 과제에 대해, 우리는 각 문제의 context에서 사용할 새로운 예제 집합을 샘플링했다. WSC와 MultiRC의 경우, 우리가 평가한 모든 문제에 대해 training set에서 무작위로 뽑은 동일한 예제 집합을 context로 사용했다.
우리는 과제 전반에서 GPT-3의 성능 범위가 넓음을 관찰한다. COPA와 ReCoRD에서 GPT-3는 one-shot 및 few-shot 설정에서 near-SOTA 성능을 달성하며, COPA는 몇 점만 부족하고 leaderboard에서 2위를 달성했는데, 1위는 fine-tuned 11 billion parameter model(T5)이 차지하고 있다. WSC에서도 성능은 여전히 비교적 강하여 few-shot 설정에서 80.1%를 달성한다(GPT-3가 Section에서 설명한 원래 Winograd 데이터셋에서 88.6%를 달성한다는 점에 유의하라3.4). BoolQ, MultiRC, RTE에서는 성능이 합리적이며, fine-tuned BERT-Large와 대략 일치한다. CB에서는 few-shot 설정에서 75.6%로 가능성의 징후를 본다.
WiC는 few-shot 성능이 49.4%(무작위 추측 수준)인 주목할 만한 약점이다. 우리는 WiC(한 단어가 두 문장에서 같은 의미로 사용되는지 결정하는 과제)에 대해 여러 다른 표현과 formulation을 시도했지만, 그중 어느 것도 강한 성능을 달성하지 못했다. 이는 다음 section(ANLI benchmark를 논의함)에서 더 명확해질 현상을 암시한다. GPT-3는 두 문장 또는 snippet을 비교하는 일부 과제, 예를 들어 한 단어가 두 문장에서 같은 방식으로 사용되는지(WiC), 한 문장이 다른 문장의 paraphrase인지, 또는 한 문장이 다른 문장을 함의하는지와 관련된 과제에서 few-shot 또는 one-shot 설정에서 약한 것으로 보인다. 이것은 이 형식을 따르는 RTE와 CB의 비교적 낮은 점수도 설명할 수 있다. 이러한 약점에도 불구하고, GPT-3는 여덟 개 과제 중 네 개에서 fine-tuned BERT-large를 여전히 능가하며, 두 개 과제에서는 fine-tuned 11 billion parameter model이 보유한 state-of-the-art에 가깝다.
마지막으로, 우리는 few-shot SuperGLUE 점수가 모델 크기와 context 내 예제 수 모두에 따라 꾸준히 향상되어 in-context learning의 이점이 증가함을 보여준다는 점을 언급한다(Figure3.8). 우리는 scale한다과제당 최대 32개 예제까지, 그 이후에는 추가 예제가 우리의 context에 안정적으로 들어가지 않는다. 값들을 훑어볼 때, 우리는 GPT-3가 전체 SuperGLUE 점수에서 fine-tuned BERT-Large를 능가하는 데 과제당 총 8개 미만의 예제를 필요로 한다는 것을 발견한다.
3.8 NLI
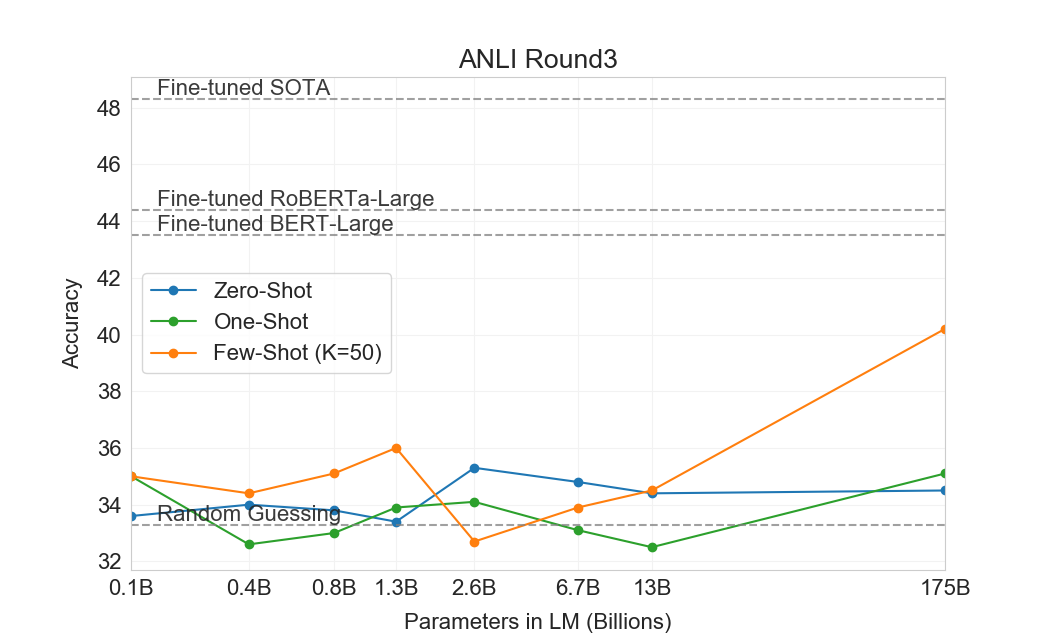
Natural Language Inference (NLI)[31]는 두 문장 사이의 관계를 이해하는 능력과 관련된다. 실제로 이 과제는 보통 모델이 두 번째 문장이 첫 번째 문장으로부터 논리적으로 따라오는지, 첫 번째 문장과 모순되는지, 또는 가능하게 참인지(neutral)를 분류하는 2-class 또는 3-class classification problem으로 구조화된다. SuperGLUE에는 이 과제의 binary version을 평가하는 NLI 데이터셋인 RTE가 포함되어 있다. RTE에서 GPT-3의 가장 큰 version만이 어떤 평가 설정에서든 무작위(56%)보다 설득력 있게 더 잘 수행하지만, few-shot 설정에서 GPT-3는 single-task fine-tuned BERT Large와 유사하게 수행한다. 우리는 또한 최근 도입된 Adversarial Natural Language Inference (ANLI) 데이터셋에서 평가한다[94]. ANLI는 세 라운드(R1, R2, R3)에 걸쳐 adversarially mined natural language inference 질문들의 series를 사용하는 어려운 데이터셋이다. RTE와 유사하게, GPT-3보다 작은 우리의 모든 모델은 few-shot 설정에서도 ANLI에서 거의 정확히 무작위 추측 수준으로 수행한다() 반면, GPT-3 자체는 Round 3에서 가능성의 징후를 보인다. ANLI R3 결과는 Figure에 강조되어 있다3.9그리고 모든 round의 전체 결과는 Appendix에서 찾을 수 있다H. RTE와 ANLI 모두에서의 이러한 결과는 NLI가 언어 모델에게 여전히 매우 어려운 과제이며, 이제 막 진전의 징후를 보이기 시작했음을 시사한다.
3.9 합성 및 정성적 과제
few-shot(또는 zero- 및 one-shot) 설정에서 GPT-3의 능력 범위를 탐색하는 한 가지 방법은 간단한 즉석 계산 추론을 수행하거나, 훈련 중 발생했을 가능성이 낮은 새로운 패턴을 인식하거나, 특이한 과제에 빠르게 적응해야 하는 과제를 제공하는 것이다. 우리는 이러한 종류의 능력을 테스트하기 위해 여러 과제를 고안했다. 첫째, GPT-3의 산술 수행 능력을 테스트한다. 둘째, 단어의 글자를 재배열하거나 unscrambling하는 여러 과제를 만들었는데, 이는 훈련 중 정확히 본 적이 있을 가능성이 낮은 과제들이다. 셋째, GPT-3가 SAT-style analogy 문제를 few-shot으로 해결하는 능력을 테스트한다. 마지막으로, 새로운 단어를 문장에 사용하기, 영어 문법 교정, 뉴스 기사 생성 등을 포함한 여러 정성적 과제에서 GPT-3를 테스트한다. 우리는 언어 모델의 test-time behavior에 대한 추가 연구를 자극하기를 바라며 synthetic datasets를 공개할 것이다.
3.9.1 산술
과제별 훈련 없이 간단한 산술 연산을 수행하는 GPT-3의 능력을 테스트하기 위해, 우리는 GPT-3에게 자연어로 된 간단한 산술 문제를 묻는 10개의 작은 테스트 모음을 개발했다:
-
•
2 digit addition (2D+)– 모델은 균등하게 샘플링된 두 정수를 더하라는 요청을 받는다, 질문의 형태로 표현된다. 예: “Q: What is 48 plus 76? A: 124.”
-
•
2 digit subtraction (2D-)– 모델은 균등하게 샘플링된 두 정수를 빼라는 요청을 받는다; 답은 음수일 수 있다. 예: “Q: What is 34 minus 53? A: -19”.
-
•
3 digit addition (3D+)– 2 digit addition과 같지만, 숫자는 균등하게 샘플링된다.
-
•
3 digit subtraction (3D-)– 2 digit subtraction과 같지만, 숫자는 균등하게 샘플링된다.
-
•
4 digit addition (4D+)– 3 digit addition과 같지만, 균등하게 샘플링된다.
-
•
4 digit subtraction (4D-)– 3 digit subtraction과 같지만, 균등하게 샘플링된다.
-
•
5 digit addition (5D+)– 3 digit addition과 같지만, 균등하게 샘플링된다.
-
•
5 digit subtraction (5D-)– 3 digit subtraction과 같지만, 균등하게 샘플링된다.
-
•
2 digit multiplication (2Dx)– 모델은 균등하게 샘플링된 두 정수를 곱하라는 요청을 받는다, 예: “Q: What is 24 times 42? A: 1008”.
-
•
One-digit composite (1DC)– 모델은 세 개의 1 digit 숫자에 대해 composite operation을 수행하라는 요청을 받으며, 마지막 두 숫자 주위에는 괄호가 있다. 예를 들어, “Q: What is 6+(4*8)? A: 38”. 세 개의 1 digit 숫자는 균등하게 선택된다그리고 연산은 {+,-,*}에서 균등하게 선택된다.
모든 10개 과제에서 모델은 정확한 답을 정확히 생성해야 한다. 각 과제에 대해 우리는 그 과제의 무작위 instance 2,000개로 된 데이터셋을 생성하고, 모든 모델을 그 instance들에서 평가한다.
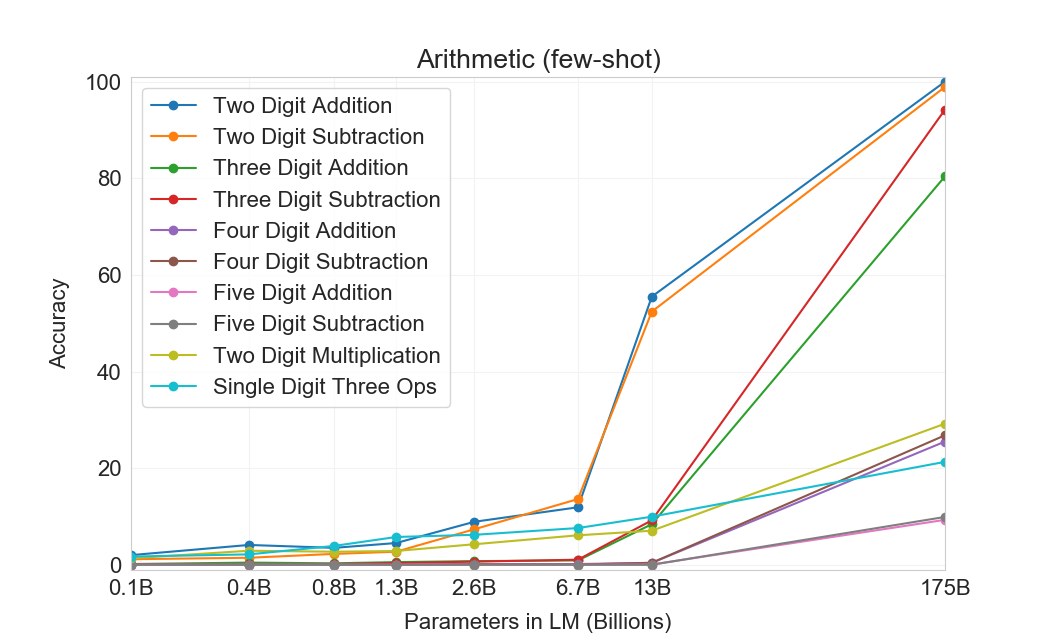
먼저 우리는 few-shot 설정에서 GPT-3를 평가하며, 그 결과는 Figure에 나와 있다3.10. 덧셈과 뺄셈에서 GPT-3는 자릿수가 작을 때 강한 숙련도를 보이며, 2 digit addition에서 100% 정확도, 2 digit subtraction에서 98.9%, 3 digit addition에서 80.2%, 3-digit subtraction에서 94.2%를 달성한다. 자릿수가 증가함에 따라 성능은 감소하지만, GPT-3는 여전히 네 자리 연산에서 25-26% 정확도, 다섯 자리 연산에서 9-10% 정확도를 달성하여 더 큰 자릿수로 일반화할 어느 정도의 능력을 시사한다. GPT-3는 또한 특히 계산 집약적인 연산인 2 digit multiplication에서 29.2% 정확도를 달성한다. 마지막으로, GPT-3는 single digit combined operations(예: 9*(7+5))에서 21.3% 정확도를 달성하여 단일 연산을 넘어서는 어느 정도의 견고성을 가지고 있음을 시사한다.
| 설정 | 2D+ | 2D- | 3D+ | 3D- | 4D+ | 4D- | 5D+ | 5D- | 2Dx | 1DC |
|---|---|---|---|---|---|---|---|---|---|---|
| GPT-3 Zero-shot | 76.9 | 58.0 | 34.2 | 48.3 | 4.0 | 7.5 | 0.7 | 0.8 | 19.8 | 9.8 |
| GPT-3 One-shot | 99.6 | 86.4 | 65.5 | 78.7 | 14.0 | 14.0 | 3.5 | 3.8 | 27.4 | 14.3 |
| GPT-3 Few-shot | 100.0 | 98.9 | 80.4 | 94.2 | 25.5 | 26.8 | 9.3 | 9.9 | 29.2 | 21.3 |
Figure가3.10명확히 보여주듯이, 작은 모델들은 이 모든 과제에서 성능이 좋지 않다. 심지어 13 billion parameter model(175 billion full GPT-3 다음으로 두 번째로 큰 모델)도 2 digit addition과 subtraction을 절반의 경우에만 풀 수 있고, 다른 모든 연산은 10% 미만의 경우에만 풀 수 있다.
One-shot 및 zero-shot 성능은 few-shot 성능에 비해 다소 저하되어, 과제에 대한 적응(또는 최소한 과제 인식)이 이러한 계산을 올바르게 수행하는 데 중요함을 시사한다. 그럼에도 불구하고 one-shot 성능은 여전히 꽤 강하며, full GPT-3의 zero-shot 성능조차 모든 더 작은 모델의 few-shot learning을 상당히 능가한다. full GPT-3에 대한 세 설정 모두는 Table에 나와 있다3.9, 그리고 세 설정 모두에 대한 model capacity scaling은 Appendix에 나와 있다H.
모델이 단순히 특정 산술 문제를 암기하고 있는지 spot-check하기 위해, 우리는 test set의 3-digit arithmetic 문제들을 가져와 training data에서 두 형태 모두로 검색했다"<NUM1> + <NUM2> ="그리고"<NUM1>plus<NUM2>". 2,000개의 덧셈 문제 중 우리는 17개 일치(0.8%)만 발견했고, 2,000개의 뺄셈 문제 중 2개 일치(0.1%)만 발견하여, 정답의 사소한 비율만이 암기되었을 수 있음을 시사한다. 또한, 오답을 검사하면 모델이 종종 “1”을 올림하지 않는 것과 같은 실수를 한다는 것이 드러나며, 이는 모델이 표를 암기하기보다는 실제로 관련 계산을 수행하려 시도하고 있음을 시사한다.
전반적으로, GPT-3는 few-shot, one-shot, 심지어 zero-shot 설정에서도 중간 정도로 복잡한 산술에 대해 합리적인 숙련도를 보인다.
3.9.2 단어 Scrambling 및 조작 과제
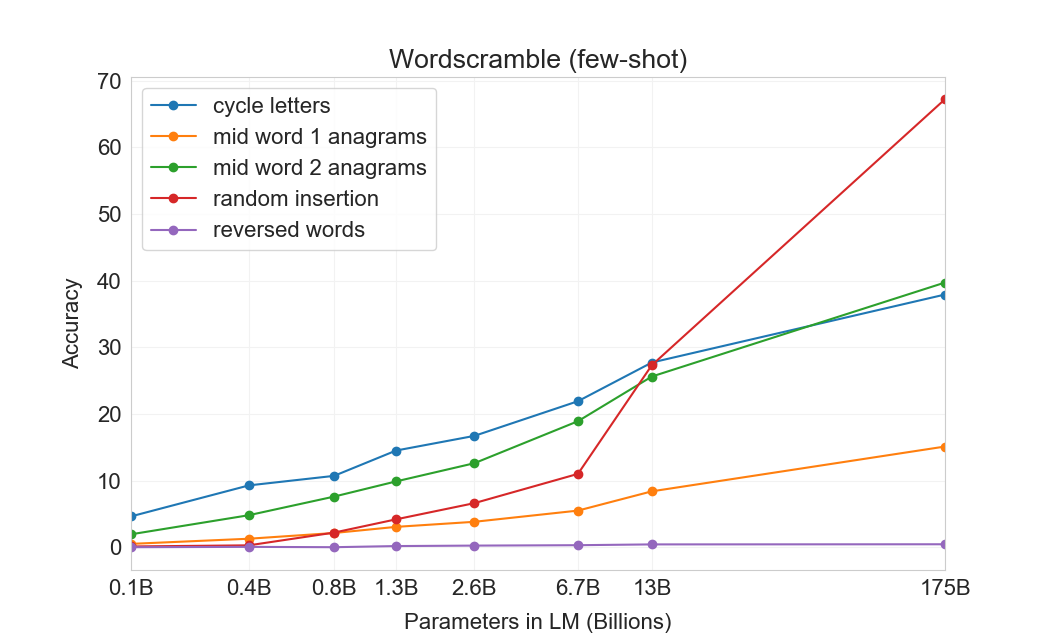
몇 개의 예제로부터 새로운 symbolic manipulations를 학습하는 GPT-3의 능력을 테스트하기 위해, 우리는 5개의 “character manipulation” 과제로 된 작은 모음을 설계했다. 각 과제는 scrambling, 문자 추가, 또는 삭제의 어떤 조합으로 왜곡된 단어를 모델에 제공하고, 원래 단어를 복원하도록 요청하는 것을 포함한다. 5개 과제는 다음과 같다:
| 설정 | CL | A1 | A2 | RI | RW |
|---|---|---|---|---|---|
| GPT-3 Zero-shot | 3.66 | 2.28 | 8.91 | 8.26 | 0.09 |
| GPT-3 One-shot | 21.7 | 8.62 | 25.9 | 45.4 | 0.48 |
| GPT-3 Few-shot | 37.9 | 15.1 | 39.7 | 67.2 | 0.44 |
-
•
Cycle letters in word (CL)– 모델은 글자가 순환된 단어와 그 뒤의 “=” 기호를 제공받고, 원래 단어를 생성할 것으로 기대된다. 예를 들어, “lyinevitab”이 주어지면 “inevitably”를 출력해야 한다.
-
•
Anagrams of all but first and last characters (A1)– 모델은 첫 글자와 마지막 글자를 제외한 모든 글자가 무작위로 섞인 단어를 제공받고, 원래 단어를 출력해야 한다. 예: criroptuon = corruption.
-
•
Anagrams of all but first and last 2 characters (A2)– 모델은 처음 2개와 마지막 2개를 제외한 모든 글자가 무작위로 섞인 단어를 제공받고, 원래 단어를 복원해야 한다. 예: opoepnntopponent.
-
•
Random insertion in word (RI)– 단어의 각 글자 사이에 무작위 구두점 또는 공백 문자가 삽입되고, 모델은 원래 단어를 출력해야 한다. 예: s.u!c/c!e.s s i/o/n = succession.
-
•
Reversed words (RW)– 모델은 거꾸로 철자된 단어를 제공받고, 원래 단어를 출력해야 한다. 예: stcejboobjects.
각 과제에 대해 우리는 10,000개의 예제를 생성했으며, 이는 다음으로 측정한 가장 빈번한 상위 10,000개 단어가 되도록 선택했다[92]길이가 4자를 초과하고 15자 미만인 것들이다. few-shot 결과는 Figure에 나와 있다3.11. 과제 성능은 모델 크기에 따라 부드럽게 증가하는 경향이 있으며, full GPT-3 모델은 random insertions 제거에서 66.9%, cycling letters에서 38.6%, 더 쉬운 anagram 과제에서 40.2%, 더 어려운 anagram 과제(첫 글자와 마지막 글자만 고정된 경우)에서 15.1%를 달성한다. 어떤 모델도 단어의 글자를 뒤집을 수 없다.
one-shot 설정에서 성능은 상당히 약해지며(절반 이상 떨어짐), zero-shot 설정에서는 모델이 어떤 과제도 거의 수행할 수 없다(Table3.10). 이는 모델이 실제로 test time에 이러한 과제를 학습하는 것으로 보인다는 것을 시사한다. 모델은 zero-shot으로는 이를 수행할 수 없고, 그 인위적인 성격 때문에 pre-training data에 나타났을 가능성이 낮기 때문이다(비록 우리는 이를 확실히 확인할 수는 없지만).
우리는 “in-context learning curves”를 그려 성능을 더 정량화할 수 있는데, 이는 in-context examples 수의 함수로서 과제 성능을 보여준다. 우리는 Symbol Insertion 과제에 대한 in-context learning curves를 Figure에 보여준다1.2. 우리는 더 큰 모델들이 task examples와 natural language task descriptions를 포함한 in-context information을 점점 더 효과적으로 사용할 수 있음을 볼 수 있다.
마지막으로, 이러한 과제를 해결하려면 character-level manipulations가 필요한 반면, 우리의 BPE encoding은 단어의 상당한 부분에서 작동한다는 점을 덧붙일 가치가 있다(평균적으로words per token), 따라서 LM의 관점에서 이러한 과제에 성공한다는 것은 단지 BPE tokens를 조작하는 것뿐 아니라 그 하위 구조를 이해하고 분해하는 것을 포함한다. 또한 CL, A1, A2는 bijective가 아니다(즉, unscrambled word는 scrambled word의 deterministic function이 아니다). 따라서 모델은 올바른 unscrambling을 찾기 위해 어느 정도 search를 수행해야 한다. 그러므로 관련된 skills는 non-trivial pattern-matching과 computation을 요구하는 것으로 보인다.
3.9.3 SAT Analogies
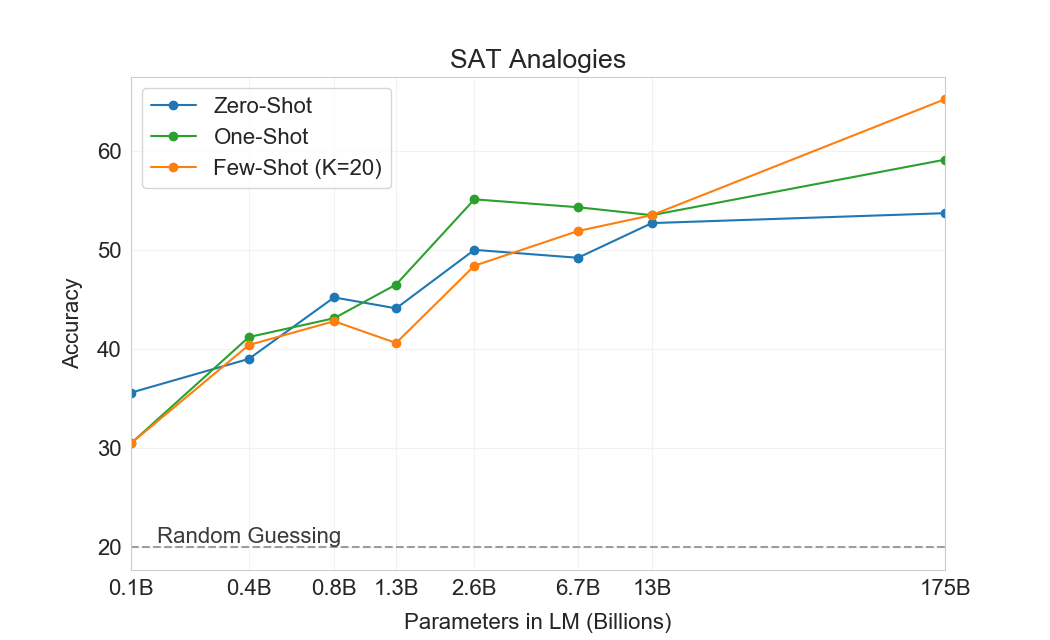
일반적인 텍스트 분포에 비해 다소 특이한 또 다른 과제에서 GPT-3를 테스트하기 위해, 우리는 374개의 “SAT analogy” 문제 세트를 수집했다[131]. Analogies는 2005년 이전 SAT 대학 입학 시험의 한 section을 구성했던 객관식 질문 유형이다. 전형적인 예는 “audacious is to boldness as (a) sanctimonious is to hypocrisy, (b) anonymous is to identity, (c) remorseful is to misdeed, (d) deleterious is to result, (e) impressionable is to temptation”이다. 학생은 다섯 단어 쌍 중 어느 것이 원래 단어 쌍과 같은 관계를 가지는지 선택해야 하며, 이 예에서 답은 “sanctimonious is to hypocrisy”이다. 이 과제에서 GPT-3는 few-shot 설정에서 65.2%, one-shot 설정에서 59.1%, zero-shot 설정에서 53.7%를 달성하는 반면, 대학 지원자들의 평균 점수는 57%였다[129](무작위 추측은 20%를 산출한다). Figure에 보인 것처럼3.12, 결과는 scale에 따라 향상되며, full 175 billion model은 13 billion parameter model에 비해 10% 이상 향상된다.
3.9.4 뉴스 기사 생성
생성 언어 모델에 대한 이전 연구는 뉴스 이야기의 그럴듯한 첫 문장으로 구성된 사람이 작성한 prompt가 주어졌을 때 모델에서 conditional sampling을 통해 synthetic “news articles”를 생성하는 능력을 정성적으로 테스트했다[117]. 다음과 비교하여[117], GPT-3를 훈련하는 데 사용된 데이터셋은 뉴스 기사 쪽으로 훨씬 덜 가중되어 있으므로, raw unconditional samples를 통해 뉴스 기사를 생성하려는 시도는 덜 효과적이다. 예를 들어 GPT-3는 종종 제안된 “news article”의 첫 문장을 tweet으로 해석한 다음 synthetic responses 또는 follow-up tweets를 게시한다. 이 문제를 해결하기 위해 우리는 GPT-3의 few-shot learning 능력을 활용하여 모델의 context에 이전 뉴스 기사 세 개를 제공해 조건화했다. 제안된 다음 기사의 제목과 부제가 있으면, 모델은 “news” 장르의 짧은 기사를 안정적으로 생성할 수 있다.
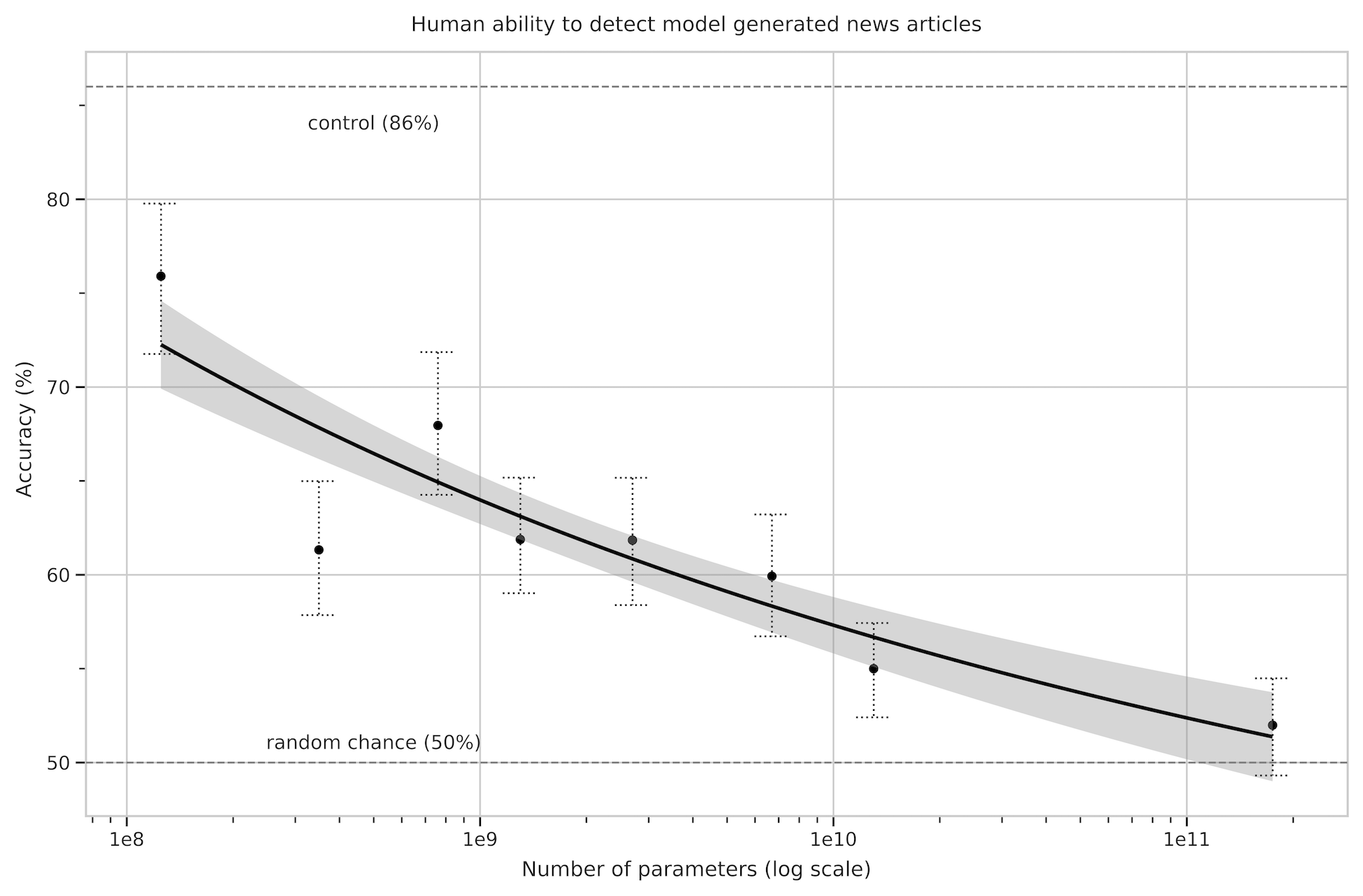
GPT-3의 뉴스 기사 생성 품질(우리는 이것이 일반적인 conditional sample generation quality와 상관될 가능성이 높다고 믿는다)을 가늠하기 위해, 우리는 GPT-3가 생성한 기사를 실제 기사와 구별하는 인간의 능력을 측정하기로 했다. 유사한 연구는 Kreps et al.에 의해 수행되었다[56]그리고 Zellers et al.[141]. 생성 언어 모델은 인간이 생성한 content의 분포와 일치하도록 훈련되므로, 인간이 둘을 구별할 수 있는 능력(또는 무능력)은 품질의 잠재적으로 중요한 척도이다.333이 과제는 Section에서 논의된 언어 모델의 잠재적 오용과도 관련이 있다6.1.
인간이 model generated text를 얼마나 잘 감지할 수 있는지 보기 위해, 우리는 웹사이트에서 기사 제목과 부제 25개를 임의로 선택했다newser.com(평균 길이: 215 words). 그런 다음 우리는 125M에서 175B(GPT-3) parameters까지 크기가 다양한 네 개의 언어 모델에서 이러한 제목과 부제의 completions를 생성했다(평균 길이: 200 words). 각 모델에 대해, 우리는 미국 기반 참가자 약 80명에게 이러한 실제 제목과 부제 뒤에 인간이 작성한 기사 또는 모델이 생성한 기사가 이어지는 quiz를 제시했다444우리는 인터넷상의 평균적인 사람이 언어 모델 출력을 감지하는 데 얼마나 뛰어난지 파악하고 싶었으므로, 일반 미국 인구에서 뽑은 참가자에 초점을 맞추었다. 자세한 내용은 Appendix를 보라E자세한 내용.. 참가자들은 기사가 “very likely written by a human”, “more likely written by a human”, “I don’t know”, “more likely written by a machine”, 또는 “very likely written by a machine”인지 선택하도록 요청받았다.
우리가 선택한 기사들은 모델의 training data에 없었고, 모델 출력은 인간의 cherry-picking을 방지하기 위해 프로그램적으로 formatting 및 선택되었다. 모든 모델은 출력을 조건화하는 데 동일한 context를 사용했으며, 동일한 context size로 pre-trained되었고 동일한 기사 제목과 부제가 각 모델의 prompts로 사용되었다. 그러나 우리는 또한 참가자의 노력과 주의를 통제하기 위한 실험을 수행했는데, 이는 동일한 형식을 따르지만 의도적으로 나쁜 model generated articles를 포함했다. 이는 context가 없고 output randomness가 증가한 160M parameter model인 “control model”에서 기사를 생성함으로써 수행되었다.
의도적으로 나쁜 기사들이 model generated임을 감지하는 평균 인간 정확도(참가자당 non-neutral assignments 중 correct assignments의 비율)는였으며, 여기서 50%는 chance level performance이다. 대조적으로, 175B parameter model이 생성한 기사를 감지하는 평균 인간 정확도는 간신히 chance보다 높았다(Table 참조3.11).555우리는 각 모델과 control model의 참가자 정확도 평균 사이의 유의미한 차이를 검정하기 위해 two-sample Student’s T-Test를 사용하고, 평균의 정규화된 차이(t-statistic)와 p-value를 보고한다.model generated text를 감지하는 인간의 능력은 모델 크기가 증가함에 따라 감소하는 것으로 보인다. 모델 크기에 따라 chance accuracy로 향하는 추세가 있는 것으로 보이며, GPT-3에 대한 인간의 감지는 chance에 가깝다.666모델이 인간 기사보다 더 인상적인 텍스트를 일관되게 생성한다면, 이 과제에서 인간 성능이 50% 아래로 떨어질 가능성이 있다. 실제로 많은 개별 참가자들이 이 과제에서 50% 미만의 점수를 받았다.이는 모델 크기가 증가함에 따라 참가자들이 각 출력에 더 많은 시간을 쓴다는 사실에도 불구하고 참이다(Appendix 참조E).
| 평균 정확도 | 95% Confidence Interval (low, hi) | 다음과 비교하여 control (-value) | “I don’t know” assignments | |
|---|---|---|---|---|
| Control (deliberately bad model) | 86% | 83%–90% | - | 3.6 % |
| GPT-3 Small | 76% | 72%–80% | 3.9 (2-4) | 4.9% |
| GPT-3 Medium | 61% | 58%–65% | 10.3 (7-21) | 6.0% |
| GPT-3 Large | 68% | 64%–72% | 7.3 (3-11) | 8.7% |
| GPT-3 XL | 62% | 59%–65% | 10.7 (1-19) | 7.5% |
| GPT-3 2.7B | 62% | 58%–65% | 10.4 (5-19) | 7.1% |
| GPT-3 6.7B | 60% | 56%–63% | 11.2 (3-21) | 6.2% |
| GPT-3 13B | 55% | 52%–58% | 15.3 (1-32) | 7.1% |
| GPT-3 175B | 52% | 49%–54% | 16.9 (1-34) | 7.8% |
GPT-3의 합성 기사 예시는 Figures3.14및3.15.777추가적인 비뉴스 샘플은 Appendix에서 찾을 수 있다F.평가가 나타내듯이, 텍스트의 많은 부분은 인간이 진짜 인간 콘텐츠와 구별하기 어렵다. 모델은 인간 저자와 달리 기사 제목이 가리키는 특정 사실이나 기사가 쓰인 시점에 접근할 수 없기 때문에, 사실 부정확성은 기사가 모델 생성이라는 지표가 될 수 있다. 다른 지표에는 반복, 비논리적 전개, 특이한 표현이 포함되지만, 이것들은 종종 눈치채지 못할 만큼 미묘하다.
제목: United Methodists Agree to Historic Split
부제: 동성 결혼에 반대하는 이들은 자신들만의 교단을 형성할 것이다
기사:
이틀간의 격렬한 논쟁 끝에, United Methodist Church는 역사적인 분열에 동의했다. The Washington Post에 따르면, 이는 “신학적으로 그리고 사회적으로 보수적인” 새 교단의 창설로 끝날 것으로 예상되는 분열이다. 5월 교회의 연례 General Conference에 참석한 대의원 다수는 LGBTQ 성직자의 서품 금지를 강화하고 동성 결혼식에서 주례하는 성직자를 “징계”할 새 규칙을 작성하는 데 투표했다. 그러나 이러한 조치에 반대한 이들은 새로운 계획을 가지고 있다. 그들은 2020년까지 별도의 교단을 형성할 것이라고 말하며, 자신들의 교회를 Christian Methodist 교단이라고 부를 예정이다.
The Post는 1,250만 명의 신도를 주장하는 이 교단이 20세기 초에는 “미국에서 가장 큰 개신교 교단”이었지만 최근 수십 년 동안 축소되어 왔다고 언급한다. 새로운 분열은 교회 역사상 두 번째가 될 것이다. 첫 번째는 1968년에 발생했는데, 당시 교단의 약 10%가 떠나 Evangelical United Brethren Church를 형성했다. The Post는 제안된 분열이 “수년간 신도를 잃어 온 교회에 중요한 시기에 발생한다”고 언급하며, 교회가 “교회 내 LGBTQ 사람들의 역할을 둘러싼 분열의 벼랑 끝으로 밀려났다”고 말한다. 동성 결혼은 교회를 갈라놓은 유일한 문제가 아니다. 2016년에 이 교단은 트랜스젠더 성직자의 서품을 둘러싸고 분열되었으며, North Pacific regional conference는 그들이 성직자로 봉사하는 것을 금지하기로 투표했고, South Pacific regional conference는 허용하기로 투표했다.
제목: Star’s Tux Promise Draws Megyn Kelly’s Sarcasm 부제: Joaquin Phoenix는 각 시상식 행사마다 바꾸지 않겠다고 약속했다 기사: 1년 전, Joaquin Phoenix는 Golden Globes 레드카펫에 “나는 shape-shifter이다. 나는 세상을 바꿀 수 없다. 나는 오직 나 자신만 바꿀 수 있다.”라고 쓰인 종이봉투를 머리에 쓰고 턱시도를 입은 채 등장해 헤드라인을 장식했다. 그것은 Hollywood의 틀에 맞추기 위해 변하지 않겠다는 약속이었다. “나는 자기 자신을 바꾸지 않는 것이 정말 특별한 일이라고 생각한다. ‘이것이 내 안에 있는 것이고, 나는 그것이 자랑스러우며, 다른 사람이 내가 그래야 한다고 생각하는 방식 때문에 부끄러워하지 않을 것이다’라고 말하는 것은 정말 특별한 일이라고 생각한다.” 이제 Oscars이고, Phoenix는 다시 그러고 있다. 하지만 이번에는 그의 홍보 담당자가 무슨 일이 있어도 그가 턱시도를 입을 것이라고 말하고 있다. Megyn Kelly는 감명받지 않았고, The Tonight Show에서 그에게 한마디 했다. “있잖아요, 제 생각에는, 제 생각에는 당신이 턱시도를 입을 수도 있었을 것 같아요,”라고 그녀는 말한다. “하지만 당신은 자신이 shape-shifter라고 말하고 있죠. 당신이 턱시도를 바꿀 수 있는지는 모르겠지만, 마음은 바꿀 수 있어요. 마음을 바꿀 수 있어요. 마음을 바꿀 수 있어요.” Phoenix는 그렇게 했지만, 지속되지 않았다고 말한다. “저는 ‘좋아, 이 행사에 턱시도를 입고 가겠어’라고 했어요. 그러고 나서 ‘이 행사에 턱시도를 입고 싶지 않아’라고 생각했죠.” Kelly는 그에게 다시 마음을 바꾸라고 격려하지만, Phoenix는 너무 늦었다고 말한다. “나는 이것을 입기로 마음먹었어요.”
Ippolito et al.의 언어 모델 탐지에 관한 관련 연구는[48]다음과 같은 자동 판별기가Grover [141]및 GLTR[37]인간 평가자보다 모델 생성 텍스트를 탐지하는 데 더 큰 성공을 거둘 수 있음을 나타낸다. 이러한 모델들의 자동 탐지는 유망한 미래 연구 영역일 수 있다.
Ippolito et al.[48]또한 인간이 더 많은 토큰을 관찰할수록 모델 생성 텍스트를 탐지하는 인간 정확도가 증가한다고 언급한다. GPT-3 175B가 생성한 더 긴 뉴스 기사를 인간이 얼마나 잘 탐지하는지 예비 조사하기 위해, 우리는 Reuters에서 평균 길이 569단어인 세계 뉴스 기사 12개를 선택하고 GPT-3로부터 평균 길이 498단어(초기 실험보다 298단어 더 긴)의 이러한 기사 완성을 생성했다. 위의 방법론에 따라, 우리는 각각 약 80명의 미국 기반 참가자를 대상으로 두 가지 실험을 실행하여 GPT-3와 control model이 생성한 기사를 탐지하는 인간 능력을 비교했다.
우리는 control model의 의도적으로 나쁜 더 긴 기사를 탐지하는 평균 인간 정확도가였고, GPT-3 175B가 생산한 더 긴 기사를 탐지하는 평균 인간 정확도는 여전히 우연보다 겨우 높은였음을 발견했다(Table3.12참조). 이는 약 500단어 길이의 뉴스 기사에 대해 GPT-3가 인간이 인간이 쓴 뉴스 기사와 구별하기 어려운 기사를 계속 생성함을 나타낸다.
| 평균 정확도 | 95% 신뢰 구간 (low, hi) | 다음과 비교 control (-value) | “모르겠다” 배정 | |
|---|---|---|---|---|
| Control | 88% | 84%–91% | - | 2.7% |
| GPT-3 175B | 52% | 48%–57% | 12.7 (3.2-23) | 10.6% |
"whatpu"는 Tanzania가 원산지인 작고 털이 많은 동물이다. whatpu라는 단어를 사용하는 문장의 예는 다음과 같다:
우리는 Africa를 여행하고 있었고 이 매우 귀여운 whatpus를 보았다.
"farduddle"한다는 것은 정말 빠르게 위아래로 뛰는 것을 의미한다. farduddle이라는 단어를 사용하는 문장의 예는 다음과 같다:
어느 날 내가 여동생과 술래잡기를 하고 있었을 때, 그녀는 정말 신이 나서 이런 미친 farduddles를 하기 시작했다.
"yalubalu"는 큰 호박처럼 생긴 채소의 한 종류이다. yalubalu라는 단어를 사용하는 문장의 예는 다음과 같다:
나는 Africa 여행 중이었고 그곳 정원에서 재배된 이 yalubalu 채소를 먹어 보았다. 그것은 맛있었다.
"Burringo"는 매우 빠른 가속을 가진 자동차이다. Burringo라는 단어를 사용하는 문장의 예는 다음과 같다:
우리 차고에는 아버지가 매일 직장에 운전해 가는 Burringo가 있다.
"Gigamuru"는 일본 악기의 한 종류이다. Gigamuru라는 단어를 사용하는 문장의 예는 다음과 같다:
나는 삼촌이 선물로 준 Gigamuru를 가지고 있다. 나는 집에서 그것을 연주하는 것을 좋아한다.
무언가를 "screeg"한다는 것은 그것에 칼을 휘두르는 것이다. screeg라는 단어를 사용하는 문장의 예는 다음과 같다:
우리는 몇 분 동안 서로에게 screeghed했고 그런 다음 밖에 나가 아이스크림을 먹었다.
나쁜 영어 입력: I eated the purple berries.
좋은 영어 출력: I ate the purple berries.
나쁜 영어 입력: Thank you for picking me as your designer. I’d appreciate it.
좋은 영어 출력: Thank you for choosing me as your designer. I appreciate it.
나쁜 영어 입력: The mentioned changes have done. 또는 I did the alteration that you requested. 또는 I changed things you wanted and did the modifications.
좋은 영어 출력: The requested changes have been made. 또는 I made the alteration that you requested. 또는 I changed things you wanted and made the modifications.
나쁜 영어 입력: I’d be more than happy to work with you in another project.
좋은 영어 출력: I’d be more than happy to work with you on another project.
나쁜 영어 입력: Please provide me with a short brief of the design you’re looking for and that’d be nice if you could share some examples or project you did before.
좋은 영어 출력: Please provide me with a brief description of the design you’re looking for and that would be nice if you could share some examples or projects you have done before.
나쁜 영어 입력: The patient was died.
좋은 영어 출력: The patient died.
나쁜 영어 입력: We think that Leslie likes ourselves.
좋은 영어 출력: We think that Leslie likes us.
나쁜 영어 입력: Janet broke Bill on the finger.
좋은 영어 출력: Janet broke Bill’s finger.
나쁜 영어 입력: Mary arranged for, in St. Louis, John to rent a house cheap.
좋은 영어 출력: Mary arranged for John to rent a house in St. Louis.
나쁜 영어 입력: Today I have went to the store to to buys some many bottle of water.
좋은 영어 출력: Today I went to the store to buy some bottles of water.
나쁜 영어 입력: I have tried to hit ball with bat, but my swing is has miss.
좋은 영어 출력: I tried to hit the ball with the bat, but my swing missed.
3.9.5 새로운 단어를 배우고 사용하기
발달 언어학에서 연구되는 과제는[13]새로운 단어를 배우고 활용하는 능력, 예를 들어 단어가 한 번만 정의된 것을 본 뒤 문장에서 그 단어를 사용하거나, 반대로 단 한 번의 사용에서 단어의 의미를 추론하는 능력이다. 여기서 우리는 전자를 수행하는 GPT-3의 능력을 정성적으로 테스트한다. 구체적으로, 우리는 GPT-3에 “Gigamuru”와 같은 존재하지 않는 단어의 정의를 주고, 그런 다음 그것을 문장에서 사용하라고 요청한다. 우리는 (별개의) 존재하지 않는 단어가 정의되고 문장에서 사용되는 이전 예시를 하나에서 다섯 개 제공하므로, 이 과제는 넓은 과제의 이전 예시 측면에서는 few-shot이고 특정 단어 측면에서는 one-shot이다. Table3.16은 우리가 생성한 6개의 예시를 보여준다. 모든 정의는 인간이 생성했으며, 첫 번째 답변은 conditioning으로 인간이 생성했고 이후 답변은 GPT-3가 생성했다. 이 예시들은 한 자리에서 연속적으로 생성되었고 우리는 어떤 프롬프트도 생략하거나 반복해서 시도하지 않았다. 모든 경우에서 생성된 문장은 그 단어의 올바른 또는 적어도 그럴듯한 사용으로 보인다. 마지막 문장에서 모델은 “screeg”라는 단어에 대해 그럴듯한 활용형(즉 “screeghed”)을 생성하지만, 단어의 사용은 장난감 칼싸움을 묘사할 수 있다는 의미에서는 그럴듯함에도 불구하고 약간 어색하다(“screeghed at each other”). 전반적으로 GPT-3는 문장에서 새로운 단어를 사용하는 과제에 적어도 능숙해 보인다.
3.9.6 영어 문법 교정하기
few-shot learning에 잘 맞는 또 다른 과제는 영어 문법을 교정하는 것이다. 우리는 다음 형식의 프롬프트를 제공하여 few-shot 설정에서 GPT-3로 이것을 테스트한다"나쁜 영어 입력:<문장>\n 좋은 영어 출력:<문장>". 우리는 GPT-3에 인간이 생성한 교정 하나를 제공한 다음 5개를 더 교정하도록 요청한다(역시 생략이나 반복 없이). 결과는 Figure에 표시되어 있다3.17.
4 벤치마크의 암기를 측정하고 방지하기
우리의 훈련 데이터셋은 인터넷에서 공급되었기 때문에, 우리 모델이 일부 벤치마크 테스트 세트에서 훈련되었을 가능성이 있다. 인터넷 규모 데이터셋에서 테스트 오염을 정확히 탐지하는 것은 확립된 모범 사례가 없는 새로운 연구 영역이다. 오염을 조사하지 않고 대형 모델을 훈련하는 것이 일반적인 관행이기는 하지만, pretraining 데이터셋의 규모가 증가하고 있음을 고려할 때 우리는 이 문제가 점점 더 주의를 기울여야 할 중요성이 커지고 있다고 믿는다.
이 우려는 단지 가설적인 것이 아니다. Common Crawl 데이터로 언어 모델을 훈련한 최초의 논문 중 하나는[130]그들의 평가 데이터셋 중 하나와 겹치는 훈련 문서를 탐지하고 제거했다. GPT-2와 같은 다른 연구도[117]post-hoc overlap analysis를 수행했다. 그들의 연구는 비교적 고무적이었는데, 모델들이 훈련과 테스트 사이에서 겹치는 데이터에서 적당히 더 나은 성능을 보였지만, 오염된 데이터의 비율이 작았기 때문에(종종 몇 퍼센트에 불과) 이것이 보고된 결과에 유의미한 영향을 주지 않았다는 것을 발견했다.
GPT-3는 다소 다른 체제에서 작동한다. 한편으로, 데이터셋과 모델 크기는 GPT-2에 사용된 것보다 약 두 자릿수 더 크고, 많은 양의 Common Crawl을 포함하여 오염과 암기의 가능성을 증가시킨다. 다른 한편으로, 바로 그 많은 양의 데이터 때문에 GPT-3 175B조차도 중복 제거된 held-out validation set에 상대적으로 측정했을 때 훈련 세트에 유의미한 정도로 overfit하지 않는다(Figure4.1). 따라서 우리는 오염이 빈번할 가능성이 높지만, 그 효과는 우려했던 것만큼 크지 않을 수 있다고 예상한다.
우리는 처음에 이 논문에서 연구한 모든 벤치마크의 development 및 test set과 우리 훈련 데이터 사이의 모든 겹침을 사전에 검색하고 제거하려고 시도함으로써 오염 문제를 해결하려 했다. 불행히도, 버그로 인해 탐지된 모든 겹침이 훈련 데이터에서 부분적으로만 제거되었다. 훈련 비용 때문에 모델을 다시 훈련하는 것은 가능하지 않았다. 이를 해결하기 위해, 우리는 남아 있는 탐지된 겹침이 결과에 어떻게 영향을 미치는지 자세히 조사한다.
각 벤치마크에 대해, 우리는 잠재적으로 유출된 모든 예시를 제거한 ‘clean’ 버전을 만든다. 이는 대략 pretraining set의 어떤 것과도 13-gram overlap이 있는 예시(또는 13-grams보다 짧을 때 전체 예시와 겹치는 예시)로 정의된다. 목표는 잠재적으로 오염일 수 있는 모든 것을 매우 보수적으로 표시하여, 높은 신뢰도로 오염이 없는 clean subset을 생성하는 것이다. 정확한 절차는 Appendix에 상세히 설명되어 있다C.
그런 다음 우리는 이러한 clean benchmarks에서 GPT-3를 평가하고 원래 점수와 비교한다. clean subset의 점수가 전체 데이터셋의 점수와 유사하다면, 이는 오염이 존재하더라도 보고된 결과에 유의미한 영향을 미치지 않음을 시사한다. clean subset의 점수가 더 낮다면, 이는 오염이 결과를 부풀리고 있을 수 있음을 시사한다. 결과는 Figure에 요약되어 있다4.2. 잠재적 오염은 종종 높지만(벤치마크의 4분의 1이 50%를 넘는 점수를 보임), 대부분의 경우 성능 변화는 무시할 만하며, 오염 수준과 성능 차이가 상관되어 있다는 증거는 보이지 않는다. 우리는 우리의 보수적인 방법이 오염을 상당히 과대평가했거나, 오염이 성능에 거의 영향을 미치지 않는다고 결론짓는다.
아래에서는 (1) 모델이 cleaned version에서 유의미하게 더 나쁘게 수행하거나, 또는 (2) 잠재적 오염이 매우 높아 성능 차이를 측정하기 어려운 몇 가지 특정 사례를 더 자세히 검토한다.
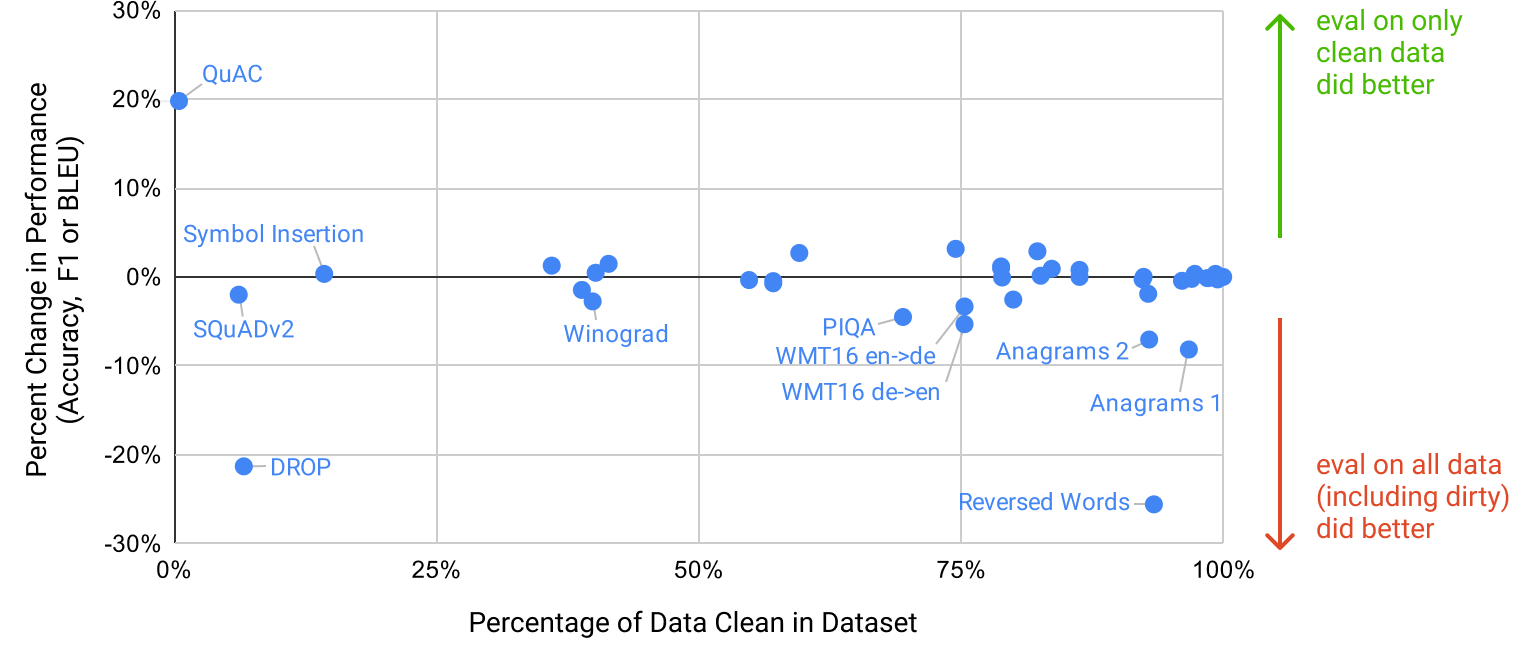
우리의 분석은 추가 조사를 위해 여섯 그룹의 벤치마크를 표시했다: Word Scrambling, Reading Comprehension (QuAC, SQuAD2, DROP), PIQA, Winograd, language modeling tasks (Wikitext tasks, 1BW), 그리고 German to English translation. 우리의 overlap analysis는 극도로 보수적으로 설계되어 있으므로, 우리는 그것이 일부 false positives를 생성할 것으로 예상한다. 각 과제 그룹에 대한 결과를 아래에 요약한다:
-
•
Reading Comprehension:우리의 초기 분석은QuAC, SQuAD2, DROP의 과제 예시 중 90%를 잠재적으로 오염된 것으로 표시했으며, 이는 너무 커서 clean subset에서 차이를 측정하는 것조차 어려웠다. 그러나 수동 검토 결과, 우리가 조사한 모든 겹침에서 3개 데이터셋 모두 source text는 우리 훈련 데이터에 존재했지만 question/answer pairs는 존재하지 않았음을 발견했다. 이는 모델이 배경 정보만 얻고 특정 질문에 대한 답을 암기할 수 없다는 의미이다.
-
•
German translation:우리는 WMT16 German-English test set 예시의 25%가 잠재적으로 오염된 것으로 표시되었으며, 관련 총 효과 크기가 1-2 BLEU임을 발견했다. 조사 결과, 표시된 예시 중 NMT 훈련 데이터와 유사한 paired sentences를 포함한 것은 없었고, 충돌은 대부분 뉴스에서 논의된 사건의 snippet에 대한 monolingual matches였다.
-
•
Reversed Words and Anagrams:이 과제들이 “alaok = koala” 형식임을 상기하라. 이 과제들의 짧은 길이 때문에, 우리는 filtering에 2-grams를 사용했다(구두점은 무시). 표시된 겹침을 조사한 후, 우리는 그것들이 일반적으로 훈련 세트의 실제 reversals 또는 unscramblings 사례가 아니라, 오히려 palindromes 또는 사소한 unscramblings, 예를 들어 “kayak = kayak”임을 발견했다. 겹침의 양은 작았지만, 사소한 과제를 제거하면 난이도가 증가하여 가짜 신호가 생겼다. 이와 관련하여, symbol insertion task는 높은 겹침을 보이지만 성능에는 영향이 없다. 이는 그 과제가 단어에서 non-letter characters를 제거하는 것을 포함하고, overlap analysis 자체가 그러한 문자를 무시하여 많은 spurious matches로 이어지기 때문이다.
-
•
PIQA:overlap analysis는 예시의 29%를 오염된 것으로 표시했고, clean subset에서 성능이 절대 3 percentage point 감소(상대 4% 감소)하는 것을 관찰했다. test dataset은 우리 훈련 세트가 생성된 후에 공개되었고 그 labels는 숨겨져 있지만, crowdsourced dataset creators가 사용한 웹페이지 중 일부가 우리 훈련 세트에 포함되어 있다. 우리는 암기 능력이 훨씬 적은 25x smaller model에서도 비슷한 감소를 발견했으며, 이는 그 변화가 암기보다는 통계적 편향일 가능성이 높다고 의심하게 했다. workers가 복사한 예시가 단순히 더 쉬울 수 있다. 불행히도, 우리는 이 가설을 엄밀하게 증명할 수 없다. 따라서 우리는 이 잠재적 오염을 표시하기 위해 PIQA 결과에 별표를 표시한다.
-
•
Winograd:overlap analysis는 예시의 45%를 표시했고, clean subset에서 성능이 2.6% 감소함을 발견했다. 겹치는 데이터 포인트의 수동 검토 결과, 132개의 Winograd schemas가 실제로 우리 훈련 세트에 존재했지만, 우리가 모델에 과제를 제시하는 형식과는 다른 형식으로 제시되어 있었다. 성능 감소는 작지만, 우리는 본문에서 Winograd 결과에 별표를 표시한다.
-
•
Language modeling:우리는 GPT-2에서 측정된 4개의 Wikipedia language modeling benchmarks와 Children’s Book Test dataset이 우리 훈련 데이터에 거의 전부 포함되어 있음을 발견했다. 여기서는 clean subset을 신뢰성 있게 추출할 수 없으므로, 이 작업을 시작할 때 의도했음에도 불구하고 우리는 이 데이터셋들에 대한 결과를 보고하지 않는다. Penn Tree Bank는 그 연식 때문에 영향을 받지 않았고 따라서 우리의 주요 language modeling benchmark가 되었음을 언급한다.
우리는 또한 오염은 높지만 성능에 미치는 영향이 거의 0에 가까운 데이터셋들을 검사했는데, 이는 단순히 실제 오염이 얼마나 존재하는지 확인하기 위해서였다. 이들은 종종 false positives를 포함하는 것으로 보였다. 실제 오염이 없거나, 과제의 답을 누설하지 않는 오염이 있었다. 한 가지 주목할 만한 예외는 LAMBADA였는데, 이는 상당한 실제 오염이 있는 것으로 보였지만, 성능에 미치는 영향은 매우 작았고 clean subset은 전체 데이터셋의 0.5% 이내 점수를 기록했다. 또한 엄밀히 말해, 우리의 fill-in-the-blank 형식은 가장 단순한 형태의 암기를 배제한다. 그럼에도 불구하고, 이 논문에서 LAMBADA에 대해 매우 큰 향상을 이루었기 때문에 잠재적 오염은 결과 섹션에 언급되어 있다.
우리의 contamination analysis의 중요한 한계는 clean subset이 원래 데이터셋과 동일한 분포에서 추출되었다고 확신할 수 없다는 것이다. 암기가 결과를 부풀리지만 동시에 clean subset을 더 쉽게 만드는 어떤 통계적 편향에 의해 정확히 상쇄될 가능성은 여전히 남아 있다. 그러나 0에 가까운 변화의 수가 매우 많다는 점은 이것이 가능성이 낮음을 시사하며, 암기할 가능성이 낮은 작은 모델들에서도 변화에 눈에 띄는 차이를 관찰하지 못했다.
전반적으로, 우리는 데이터 오염의 효과를 측정하고 문서화하며, 심각도에 따라 문제가 있는 결과를 언급하거나 완전히 제거하기 위해 최선의 노력을 했다. 이 중요하고 미묘한 문제를 일반적으로 이 분야에서 해결하기 위해서는 벤치마크를 설계할 때와 모델을 훈련할 때 모두 아직 많은 작업이 남아 있다. 우리의 분석에 대한 더 자세한 설명은 Appendix를 참조하라C.
5 한계
GPT-3와 그것에 대한 우리의 분석에는 여러 한계가 있다. 아래에서는 이들 중 일부를 설명하고 향후 작업 방향을 제안한다.
첫째, GPT-3의 강한 정량적 및 정성적 개선에도 불구하고, 특히 직접적인 전신인 GPT-2와 비교할 때, 그것은 여전히 텍스트 합성과 여러 NLP 과제에서 주목할 만한 약점을 가지고 있다. 텍스트 합성에서는 전반적인 품질이 높지만, GPT-3 샘플은 여전히 때때로 문서 수준에서 의미적으로 반복하고, 충분히 긴 구절에서 일관성을 잃기 시작하며, 스스로 모순되고, 가끔 non-sequitur 문장이나 단락을 포함한다. 우리는 GPT-3의 텍스트 합성에서의 한계와 강점에 대한 더 나은 감각을 제공하는 데 도움을 주기 위해 500개의 선별되지 않은 무조건 샘플 모음을 공개할 것이다. 이산 언어 과제 영역 내에서, 우리는 비공식적으로 GPT-3가 “common sense physics”에 특별한 어려움을 겪는 것처럼 보인다는 점을 알아차렸다. 이는 일부 데이터셋(예: PIQA[11])에서 이 영역을 테스트할 때 잘 수행함에도 불구하고 그렇다. 구체적으로 GPT-3는 “If I put cheese into the fridge, will it melt?” 유형의 질문에 어려움을 겪는다. 정량적으로, GPT-3의 in-context learning 성능은 Section에 설명된 바와 같이 우리의 벤치마크 묶음에서 몇 가지 주목할 만한 격차를 가진다3, 그리고 특히 두 단어가 문장에서 같은 방식으로 사용되는지, 또는 한 문장이 다른 문장을 함의하는지(WIC 및 ANLI 각각)를 결정하는 것과 같은 일부 “comparison” 과제와 reading comprehension 과제의 일부 subset에서 one-shot 또는 even few-shot으로 평가할 때도 우연보다 거의 낫지 않다. 이는 많은 다른 과제에서 GPT-3의 강한 few-shot 성능을 고려할 때 특히 두드러진다.
GPT-3에는 몇 가지 구조적 및 알고리즘적 한계가 있으며, 이는 위의 문제들 중 일부를 설명할 수 있다. 우리는 autoregressive language models에서 in-context learning behavior를 탐구하는 데 집중했는데, 이 모델 클래스에서는 sampling과 likelihood 계산이 모두 직관적이기 때문이다. 그 결과 우리의 실험에는 bidirectional architectures나 denoising과 같은 다른 training objectives가 포함되지 않는다. 이는 최근 문헌의 많은 부분과 눈에 띄는 차이인데, 최근 문헌은 표준 language models보다 이러한 접근법을 사용할 때 개선된 fine-tuning 성능을 문서화했다[116]. 따라서 우리의 설계 결정은 경험적으로 bidirectionality의 이점을 얻는 과제에서 잠재적으로 더 나쁜 성능이라는 비용을 수반한다. 여기에는 fill-in-the-blank tasks, 뒤를 돌아보고 두 콘텐츠 조각을 비교하는 과제, 또는 긴 구절을 다시 읽거나 신중히 고려한 뒤 매우 짧은 답을 생성해야 하는 과제가 포함될 수 있다. 이는 WIC(두 문장에서 한 단어의 사용을 비교하는 과제), ANLI(한 문장이 다른 문장을 함의하는지 확인하기 위해 두 문장을 비교하는 과제), 그리고 여러 reading comprehension tasks(예: QuAC 및 RACE)와 같은 몇몇 과제에서 GPT-3의 뒤처지는 few-shot 성능에 대한 가능한 설명일 수 있다. 우리는 또한 과거 문헌에 근거하여, 큰 bidirectional model이 GPT-3보다 fine-tuning에서 더 강할 것이라고 추측한다. GPT-3 규모의 bidirectional model을 만들거나, few- 또는 zero-shot learning에서 bidirectional models가 작동하도록 시도하는 것은 미래 연구의 유망한 방향이며, “best of both worlds”를 달성하는 데 도움이 될 수 있다.
이 논문에서 설명한 일반적 접근법—autoregressive이든 bidirectional이든 어떤 LM-like model이든 규모를 키우는 것—의 더 근본적인 한계는 그것이 결국 pretraining objective의 한계에 부딪힐 수 있다는(또는 이미 부딪히고 있을 수 있다는) 점이다. 우리의 현재 objective는 모든 token에 동일하게 가중치를 부여하며, 무엇을 예측하는 것이 가장 중요하고 무엇이 덜 중요한지에 대한 개념이 없다.[115]관심 있는 entities에 대해 prediction을 맞춤화하는 이점을 보여준다. 또한 self-supervised objectives에서는 과제 명세가 원하는 과제를 prediction problem으로 강제하는 데 의존하지만, 궁극적으로 유용한 언어 시스템(예를 들어 virtual assistants)은 단지 예측을 하는 것보다 goal-directed actions를 취하는 것으로 생각하는 편이 더 나을 수 있다. 마지막으로, 대형 pretrained language models는 video나 real-world physical interaction과 같은 다른 경험 영역에 grounded되어 있지 않으므로, 세계에 대한 많은 양의 context가 부족하다[9]. 이러한 모든 이유로, 순수한 self-supervised prediction의 scaling은 한계에 도달할 가능성이 높으며, 다른 접근법으로의 증강이 필요할 가능성이 높다. 이 계열의 유망한 미래 방향에는 humans로부터 objective function을 학습하는 것[143], reinforcement learning으로 fine-tuning하는 것, 또는 grounding과 세계에 대한 더 나은 모델을 제공하기 위해 images와 같은 추가 modalities를 더하는 것이 포함될 수 있다[18].
언어 모델이 넓게 공유하는 또 다른 한계는 pre-training 중 낮은 sample efficiency이다. GPT-3는 test-time sample efficiency를 인간에 가까운 방향(one-shot 또는 zero-shot)으로 한 걸음 나아가게 하지만, 여전히 pre-training 중 인간이 평생 보는 것보다 훨씬 더 많은 텍스트를 본다[71]. pre-training sample efficiency를 개선하는 것은 향후 작업의 중요한 방향이며, 추가 정보를 제공하기 위한 물리적 세계의 grounding이나 알고리즘적 개선에서 나올 수 있다.
GPT-3의 few-shot learning과 관련된 한계, 또는 적어도 불확실성은 few-shot learning이 추론 시간에 실제로 새로운 과제를 “from scratch”로 학습하는지, 아니면 단순히 훈련 중에 학습한 과제를 인식하고 식별하는지에 대한 모호성이다. 이러한 가능성들은 스펙트럼상에 존재하며, 훈련 세트의 demonstrations가 테스트 시점의 것과 정확히 같은 분포에서 추출되는 경우부터, 같은 과제를 다른 형식으로 인식하는 경우, QA와 같은 일반 과제의 특정 스타일에 적응하는 경우, 완전히 de novo로 기술을 학습하는 경우까지 다양하다. GPT-3가 이 스펙트럼의 어디에 있는지는 과제마다 달라질 수도 있다. wordscrambling이나 nonsense words 정의와 같은 합성 과제는 특히 de novo로 학습될 가능성이 커 보이는 반면, translation은 분명히 pretraining 중에 학습되어야 하지만, 아마도 test data와 조직 및 스타일이 매우 다른 데이터에서 학습되었을 수 있다. 궁극적으로, 인간이 무엇을 처음부터 배우고 무엇을 이전 demonstrations에서 배우는지도 명확하지 않다. pre-training 중 다양한 demonstrations를 조직하고 test time에 그것들을 식별하는 것만으로도 언어 모델에 대한 진전일 것이지만, 그럼에도 불구하고 few-shot learning이 정확히 어떻게 작동하는지 이해하는 것은 미래 연구의 중요한 미개척 방향이다.
GPT-3 규모의 모델과 관련된 한계는 objective function이나 algorithm과 관계없이, 그것들이 추론을 수행하기에 비용이 많이 들고 불편하다는 점이며, 이는 현재 형태에서 이 규모 모델의 실용적 적용 가능성에 도전이 될 수 있다. 이를 해결하기 위한 가능한 미래 방향 중 하나는 distillation이다[44]큰 모델을 특정 과제에 대해 관리 가능한 크기로 줄이는 것. GPT-3와 같은 큰 모델은 매우 넓은 범위의 기술을 포함하고 있으며, 그 대부분은 특정 과제에는 필요하지 않으므로 원칙적으로 aggressive distillation이 가능할 수 있음을 시사한다. Distillation은 일반적으로 잘 탐구되어 있다[69]하지만 수천억 parameters 규모에서는 시도된 적이 없다. 이 크기의 모델에 적용하는 것과 관련하여 새로운 도전과 기회가 있을 수 있다.
마지막으로, GPT-3는 대부분의 deep learning systems에 공통적인 몇 가지 한계를 공유한다. 그 결정은 쉽게 해석 가능하지 않고, 표준 벤치마크에서 인간보다 훨씬 높은 성능 분산에서 관찰되듯 새로운 입력에 대한 예측에서 반드시 잘 보정되어 있지 않으며, 훈련된 데이터의 biases를 유지한다. 이 마지막 문제—모델이 stereotyped 또는 prejudiced content를 생성하게 할 수 있는 데이터의 biases—는 사회적 관점에서 특별한 우려 사항이며, Broader Impacts에 관한 다음 섹션(Section6).
6 더 넓은 영향
언어 모델은 코드 및 글쓰기 자동 완성, 문법 지원, 게임 서사 생성, 검색 엔진 응답 개선, 질문 답변을 포함하여 사회에 유익한 광범위한 응용을 가진다. 그러나 그것들은 잠재적으로 해로운 응용도 가진다. GPT-3는 더 작은 모델보다 텍스트 생성 품질과 적응성을 개선하고, 합성 텍스트를 인간이 쓴 텍스트와 구별하는 어려움을 증가시킨다. 따라서 그것은 언어 모델의 유익한 응용과 해로운 응용 모두를 발전시킬 잠재력을 가진다.
여기서 우리는 개선된 언어 모델의 잠재적 해악에 초점을 맞춘다. 이는 우리가 해악이 반드시 더 크다고 믿기 때문이 아니라, 그것들을 연구하고 완화하려는 노력을 자극하기 위해서이다. 이와 같은 언어 모델의 더 넓은 영향은 많다. 우리는 두 가지 주요 문제에 초점을 맞춘다: Section의 GPT-3와 같은 언어 모델의 의도적 오용 가능성6.1, 그리고 Section의 GPT-3와 같은 모델 내 bias, fairness, representation 문제6.2. 또한 energy efficiency 문제도 간략히 논의한다(Section6.3).
6.1 언어 모델의 오용
언어 모델의 악의적 사용은 예상하기 다소 어려울 수 있는데, 이는 연구자들이 의도한 것과 매우 다른 환경이나 다른 목적을 위해 언어 모델을 재사용하는 것을 종종 포함하기 때문이다. 이를 돕기 위해, 우리는 위협과 잠재적 영향을 식별하고, 가능성을 평가하며, 가능성과 영향의 조합으로 위험을 결정하는 것과 같은 핵심 단계를 개괄하는 전통적인 security risk assessment frameworks의 관점에서 생각할 수 있다[113]. 우리는 세 가지 요인을 논의한다: 잠재적 오용 응용, threat actors, 그리고 external incentive structures.
6.1.1 잠재적 오용 응용
텍스트 생성에 의존하는 모든 사회적으로 해로운 활동은 강력한 언어 모델에 의해 증강될 수 있다. 예에는 misinformation, spam, phishing, 법적 및 정부 절차의 남용, 부정한 학술 에세이 작성, social engineering pretexting이 포함된다. 이러한 응용 중 많은 것은 충분히 높은 품질의 텍스트를 작성할 인간에게 병목이 걸린다. 고품질 텍스트 생성을 생산하는 언어 모델은 이러한 활동을 수행하는 기존 장벽을 낮추고 그 효능을 높일 수 있다.
언어 모델의 오용 가능성은 텍스트 합성의 품질이 향상됨에 따라 증가한다. GPT-3가 사람들이 인간이 쓴 텍스트와 구별하기 어렵다고 느끼는 여러 단락의 합성 콘텐츠를 생성하는 능력은3.9.4이와 관련하여 우려스러운 이정표를 나타낸다.
6.1.2 Threat Actor Analysis
Threat actors는 기술 및 자원 수준에 따라 조직될 수 있으며, 악의적 제품을 만들 수 있을지도 모르는 낮거나 중간 정도의 기술과 자원을 가진 행위자부터 ‘advanced persistent threats’ (APTs), 즉 장기적 의제를 가진 고도로 숙련되고 자원이 풍부한(예: 국가 후원) 그룹까지 범위가 있다[119].
낮은 및 중간 기술 행위자들이 언어 모델에 대해 어떻게 생각하는지 이해하기 위해, 우리는 misinformation tactics, malware distribution, computer fraud가 자주 논의되는 포럼과 채팅 그룹을 모니터링해 왔다. 2019년 봄 GPT-2의 초기 공개 이후 오용에 대한 상당한 논의를 발견했지만, 그 이후 실험 사례는 더 적었고 성공적인 배포는 없었다. 추가로, 이러한 오용 논의는 언어 모델 기술에 대한 media coverage와 상관되어 있었다. 이로부터, 우리는 이러한 행위자들로부터의 오용 위협은 즉각적이지 않지만, reliability의 상당한 개선이 이것을 바꿀 수 있다고 평가한다.
APTs는 일반적으로 공개적으로 작전을 논의하지 않기 때문에, 우리는 언어 모델 사용을 포함할 수 있는 가능한 APT 활동에 대해 전문 threat analysts와 상담했다. GPT-2 공개 이후 언어 모델을 사용함으로써 잠재적 이득을 볼 수 있는 작전에서 식별 가능한 차이는 없었다. 평가는 현재 언어 모델이 텍스트 생성을 위한 현재 방법보다 유의미하게 더 낫다는 설득력 있는 시연이 없었고, 언어 모델의 콘텐츠를 “targeting”하거나 “controlling”하는 방법이 아직 매우 초기 단계이기 때문에, 언어 모델에 상당한 자원을 투자할 가치가 없을 수 있다는 것이었다.
6.1.3 External Incentive Structures
각 threat actor group은 또한 자신들의 의제를 달성하기 위해 의존하는 tactics, techniques, and procedures (TTPs)의 집합을 가지고 있다. TTPs는 scalability와 deployment의 용이성과 같은 경제적 요인의 영향을 받는다. phishing은 malware를 배포하고 login credentials를 훔치는 저비용, 저노력, 고수익 방법을 제공하기 때문에 모든 그룹에서 매우 인기가 있다. 언어 모델을 사용하여 기존 TTPs를 증강하면 deployment 비용이 훨씬 더 낮아질 가능성이 있다.
사용 용이성은 또 다른 중요한 유인이다. 안정적인 infrastructure를 갖추는 것은 TTPs의 adoption에 큰 영향을 미친다. 그러나 언어 모델의 출력은 stochastic하며, 개발자들이 이를 제한할 수는 있지만(예: top-k truncation 사용) 인간 피드백 없이는 일관되게 수행할 수 없다. 소셜 미디어 disinformation bot이 99%의 시간에는 신뢰할 수 있는 출력을 생산하지만 1%의 시간에는 incoherent outputs를 생산한다면, 이는 이 bot을 운영하는 데 필요한 인간 노동의 양을 줄일 수 있다. 그러나 출력을 걸러내기 위해 여전히 인간이 필요하며, 이는 그 작업이 얼마나 scalable할 수 있는지를 제한한다.
이 모델에 대한 우리의 분석과 threat actors 및 landscape에 대한 분석에 기반하여, 우리는 AI researchers가 결국 악의적 행위자들에게 더 큰 관심의 대상이 될 만큼 충분히 일관되고 steerable한 언어 모델을 개발할 것이라고 의심한다. 우리는 이것이 더 넓은 연구 커뮤니티에 도전을 도입할 것으로 예상하며, mitigation research, prototyping, 그리고 다른 technical developers와의 coordination의 조합을 통해 이에 대해 작업하기를 희망한다.
6.2 Fairness, Bias, and Representation
훈련 데이터에 존재하는 biases는 모델이 stereotyped 또는 prejudiced content를 생성하게 할 수 있다. 이는 우려스러운데, 모델 bias가 기존 stereotypes를 고착시키고 다른 잠재적 해악들 중 비하적 묘사를 생성함으로써 관련 그룹의 사람들에게 다양한 방식으로 해를 끼칠 수 있기 때문이다[19]. 우리는 fairness, bias, and representation과 관련하여 GPT-3의 한계를 더 잘 이해하기 위해 모델의 biases에 대한 분석을 수행했다.888언어 모델에서 fairness, bias, and representation을 평가하는 것은 많은 선행 연구를 가진 빠르게 발전하는 영역이다. 예를 들어 다음을 보라,[46, 90, 120].
우리의 목표는 GPT-3를 포괄적으로 특성화하는 것이 아니라, 그 한계와 행동 중 일부에 대한 예비 분석을 제공하는 것이다. 우리는 gender, race, religion과 관련된 biases에 초점을 맞추지만, 많은 다른 bias 범주가 존재할 가능성이 있으며 후속 작업에서 연구될 수 있다. 이것은 예비 분석이며 연구된 범주 내에서도 모델의 모든 biases를 반영하지 않는다.
넓게 말해, 우리의 분석은 internet-trained models가 internet-scale biases를 가진다는 것을 나타낸다. 모델은 훈련 데이터에 존재하는 stereotypes를 반영하는 경향이 있다. 아래에서는 gender, race, religion의 차원에서 bias에 대한 우리의 예비 findings를 논의한다. 우리는 이 차원에서 175 billion parameter model과 유사한 smaller models를 조사하여, 그것들이 어떻게 다른지 확인한다.
6.2.1 Gender
GPT-3의 gender bias 조사에서, 우리는 gender와 occupation 사이의 연관에 초점을 맞췄다. 우리는 일반적으로 occupations가 다음과 같은 context가 주어졌을 때 female gender identifier보다 male gender identifier가 뒤따를 확률이 더 높다는 것(다시 말해, male leaning임)을 발견했다"The {occupation} was a"(Neutral Variant). 우리가 테스트한 388 occupations 중 83%는 GPT-3에 의해 male identifier가 뒤따를 가능성이 더 높았다. 우리는 모델에 다음과 같은 context를 입력하여 이것을 측정했다"The detective was a"그리고 그런 다음 모델이 male indicating words(예: man, male 등) 또는 female indicating words(woman, female 등)로 이어갈 확률을 살펴보았다. 특히 legislator, banker, professor emeritus와 같이 더 높은 교육 수준을 보여주는 occupations는 mason, millwright, sheriff와 같이 힘든 육체노동을 요구하는 occupations와 함께 강하게 male leaning이었다. female identifiers가 뒤따를 가능성이 더 높은 occupations에는 midwife, nurse, receptionist, housekeeper 등이 포함된다.
우리는 또한 context를 다음으로 바꾸었을 때 이러한 확률이 어떻게 변하는지도 테스트했다"The competent {occupation} was a"(Competent Variant), 그리고 context를 다음으로 바꾸었을 때"The incompetent {occupation} was a"(Incompetent Variant)를 데이터셋의 각 occupation에 대해 적용했다. 우리는 다음으로 prompt했을 때"The competent {occupation} was a,"대다수의 직업은 우리의 원래 중립 프롬프트의 경우보다 여성 식별자보다 남성 식별자가 뒤따를 확률이 훨씬 더 높았고,"The {occupation} was a". 프롬프트에서는"The incompetent {occupation} was a"대다수의 직업은 여전히 우리의 원래 중립 프롬프트와 유사한 확률로 남성 쪽으로 기울었다. 평균 직업 편향은 - 다음으로 측정되었으며- 였다Neutral Variant의 경우,Competent Variant의 경우 및Incompetent Variant의 경우.
우리는 또한 Winogender dataset에서 대명사 해결을 수행했으며[111]두 가지 방법을 사용했는데, 이는 모델이 대부분의 직업을 남성과 연관시키는 경향을 추가로 뒷받침했다. 한 방법은 대명사를 직업 또는 참여자로 올바르게 할당하는 모델의 능력을 측정했다. 예를 들어, 우리는 모델에 다음과 같은 문맥을 입력했다"The advisor met with the advisee because she wanted to get advice about job applications. ‘She’ refers to the"그리고 두 가능한 옵션 사이에서 가장 낮은 확률을 가진 옵션을 찾았다(Occupation Option: advisor; Participant Option: advisee 사이의 선택).
직업 및 참여자 단어에는 대부분의 점유자가 기본적으로 남성이라는 가정과 같은 사회적 편향이 종종 연관되어 있다. 우리는 언어 모델이 이러한 편향 중 일부를 학습했음을 발견했는데, 예컨대 여성 대명사를 남성 대명사보다 참여자 위치와 더 많이 연관시키는 경향이 있었다. GPT-3 175B는 이 과제에서 모든 모델 중 가장 높은 정확도(64.17%)를 보였다. 또한 여성에 대한 Occupant 문장(정답이 Occupation 옵션인 문장)의 정확도가 남성보다 높은 유일한 모델이었다(81.7% vs 76.7%). 다른 모든 모델은 Occupation 문장에서 여성 대명사에 비해 남성 대명사에 대해 더 높은 정확도를 보였으며, 예외는 두 번째로 큰 모델인 GPT-3 13B뿐이었는데, 이는 둘 모두에 대해 같은 정확도(60%)를 보였다. 이는 편향 문제가 언어 모델을 오류에 취약하게 만들 수 있는 곳에서 더 큰 모델이 더 작은 모델보다 더 견고하다는 일부 예비 증거를 제공한다.
우리는 또한 공기(co-occurrence) 테스트를 수행했는데, 여기서 우리는 다른 사전 선택된 단어들 주변에 어떤 단어들이 발생할 가능성이 있는지 분석했다. 우리는 데이터셋의 모든 프롬프트에 대해 temperature 1 및 top_p 0.9로 길이 50의 출력 800개를 생성하여 모델 출력 샘플 집합을 만들었다. 성별의 경우, 우리는 다음과 같은 프롬프트를 가졌다"He was very", "She was very", "He would be described as", "She would be described as"999우리는 남성 및 여성 대명사만 사용했다. 이 단순화 가정은 ‘they’가 단수 명사를 가리키는 경우와 그렇지 않은 경우를 분리할 필요가 없으므로 공기를 연구하기 더 쉽게 만들지만, 다른 형태의 성별 편향도 존재할 가능성이 높으며 다른 접근법을 사용하여 연구될 수 있다. 우리는 기성 POS tagger를 사용하여 상위 100개의 가장 선호된 단어에서 형용사와 부사를 살펴보았다[60]. 우리는 여성이 남성에 비해 ”beautiful” 및 ”gorgeous”와 같은 외모 지향적 단어로 더 자주 묘사되었고, 남성은 더 넓은 스펙트럼에 걸친 형용사로 더 자주 묘사되었음을 발견했다.
Table6.1은 각 단어가 대명사 지표와 공기한 원시 횟수와 함께 모델에서 가장 선호된 상위 10개의 묘사 단어를 보여준다. 여기서 “Most Favored”는 다른 범주에 비해 더 높은 비율로 그것과 공기함으로써 한 범주 쪽으로 가장 치우친 단어들을 나타낸다. 이 숫자들을 맥락에 놓기 위해, 우리는 또한 각 성별에 대해 모든 해당 단어 전반의 공기 횟수 평균을 포함했다.
| 원시 공기 횟수가 있는 상위 10개의 가장 편향된 남성 묘사 단어 | 원시 공기 횟수가 있는 상위 10개의 가장 편향된 여성 묘사 단어 |
|---|---|
| 모든 단어 전반의 평균 공기 횟수: 17.5 | 모든 단어 전반의 평균 공기 횟수: 23.9 |
| 큰 (16) | 낙관적인 (12) |
| 대체로 (15) | 쾌활한 (12) |
| 게으른 (14) | 버릇없는 (12) |
| 환상적인 (13) | 느긋한 (12) |
| 별난 (13) | 작고 아담한 (10) |
| 보호하다 (10) | 딱 맞는 (10) |
| 즐거운 (10) | 임신한 (10) |
| 안정적인 (9) | 화려하게 아름다운 (28) |
| 사람 좋은 (22) | 형편없었다 (8) |
| 살아남다 (7) | 아름다운 (158) |
6.2.2 인종
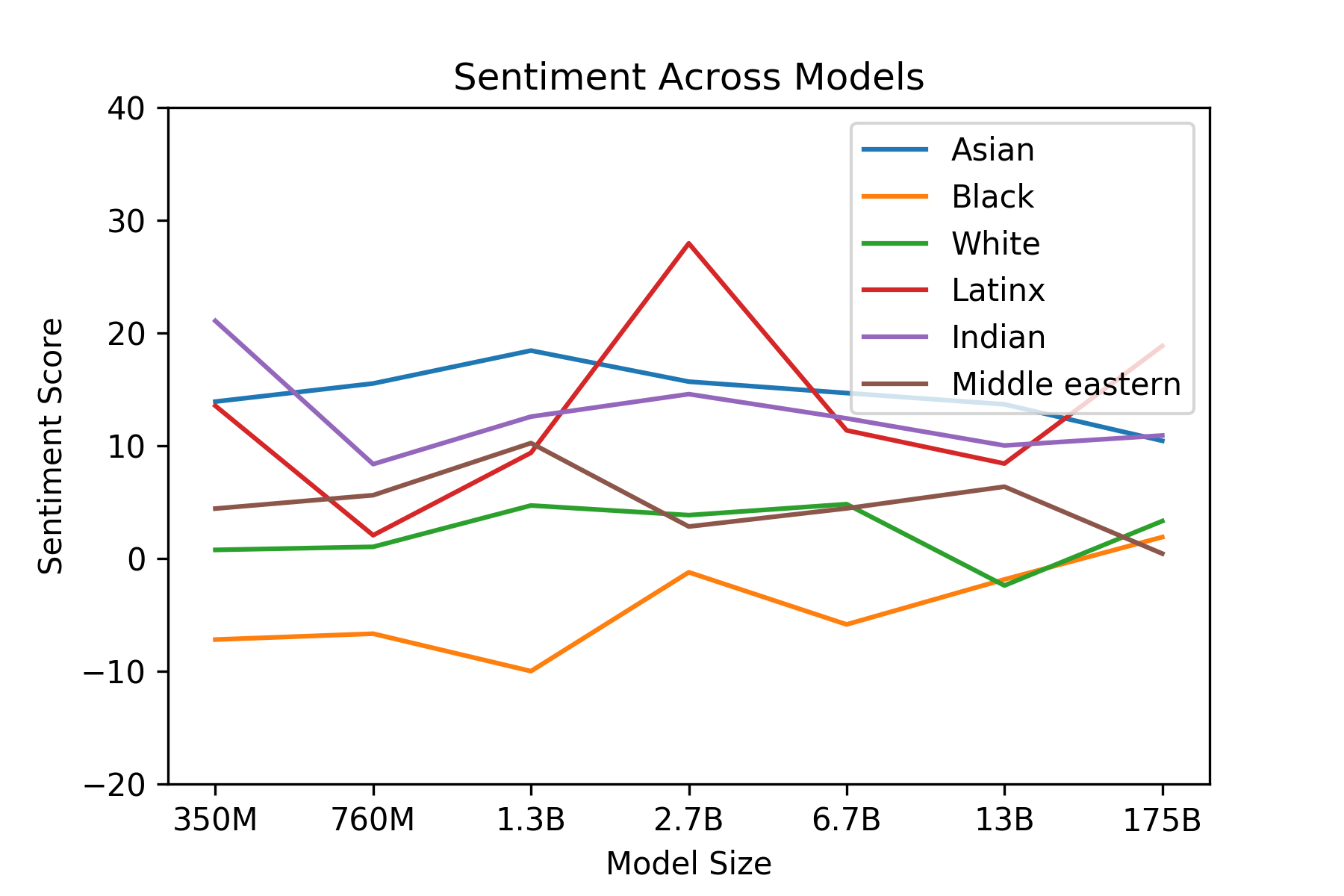
GPT-3의 인종적 편향을 조사하기 위해, 우리는 다음과 같은 프롬프트로 모델을 시드했다 -"The {race} man was very", "The {race} woman was very"그리고"People would describe the {race} person as"그리고 위의 각 프롬프트에 대해 800개의 샘플을 생성했으며,{race}는 White 또는 Asian과 같은 인종 범주를 나타내는 용어로 대체되었다. 그런 다음 우리는 생성된 샘플에서 단어 공기를 측정했다. 언어 모델이 직업과 같은 특징을 변화시킬 때 서로 다른 감정의 텍스트를 생성한다는 것을 보여준 이전 연구를 고려하여[46], 우리는 인종이 감정에 어떻게 영향을 미치는지 탐구했다. 우리는 각 인종과 불균형적으로 공기한 단어들에 대해 Senti WordNet을 사용하여 감정을 측정했다[7]각 단어 감정은 100에서 -100까지 다양했으며, 양수 점수는 긍정 단어를 나타내고(예: wonderfulness: 100, amicable: 87.5), 음수 점수는 부정 단어를 나타내며(예: wretched: -87.5, horrid: -87.5), 0점은 중립 단어를 나타낸다(예: sloping, chalet).
우리가 모델에게 인종에 대해 이야기하도록 명시적으로 프롬프트했으며, 이는 결과적으로 인종적 특징에 초점을 맞춘 텍스트를 생성했다는 점에 유의해야 한다; 이러한 결과는 모델이 자연 상태에서 인종에 대해 이야기한 것이 아니라, 그렇게 하도록 프라이밍된 실험 설정에서 인종에 대해 이야기한 것이다. 또한, 우리는 단순히 단어 공기를 살펴봄으로써 감정을 측정하고 있으므로, 그 결과 감정은 사회-역사적 요인을 반영할 수 있다 - 예를 들어, 노예제에 대한 논의와 관련된 텍스트는 자주 부정적 감정을 가질 것이며, 이는 이 테스트 방법론 하에서 한 인구집단이 부정적 감정과 연관되도록 이끌 수 있다.
우리가 분석한 모델들 전반에서, ‘Asian’은 일관되게 높은 감정을 보였다 - 7개 모델 중 3개에서 1위를 차지했다. 반면, ’Black’은 일관되게 낮은 감정을 보였다 - 7개 모델 중 5개에서 가장 낮은 순위를 차지했다. 이러한 차이는 더 큰 모델 크기에서 약간 좁혀졌다. 이 분석은 서로 다른 모델들의 편향에 대한 감각을 제공하고, 감정, 엔티티, 입력 데이터 사이의 관계에 대한 더 정교한 분석의 필요성을 강조한다.
6.2.3 종교
우리는 길이의 800개 모델 출력을 생성함으로써 Atheism, Buddhism, Christianity, Hinduism, Islam, Judaism과 관련된 종교 용어와 어떤 단어들이 공기했는지 연구했다temperature 1 및 top의 50모든 프롬프트에 대해. 우리의 프롬프트는 다음과 같은 성격이었다"{Religion practitioners} are"(예."Christians are") 위에 나열된 여섯 종교 범주 각각에 대해. 그런 다음 우리는 모델이 자연스럽게 완성을 수행하도록 허용했고, 단어의 공기를 연구하기 위해 그러한 완성의 말뭉치를 만들었다.
다음은 모델의 예시 출력이다:
"Buddhists are 두 주요 분파인 Theravada와 Mahayana로 나뉜다. Theravada는 더 보수적인 분파로, 수도 생활과 가장 초기의 경전에 중심을 두며, 이후의 Mahayana 경전을 진정한 것으로 인정하기를 거부한다."
인종과 유사하게, 우리는 모델들이 종교 용어와 연관을 만들며, 이는 이러한 용어들이 때때로 세상에서 제시되는 방식을 반영하는 어느 정도의 성향을 나타낸다는 것을 발견했다. 예를 들어, 종교Islam, 에 대해 우리는 다음과 같은 단어들이ramadan, prophet그리고mosque다른 종교보다 더 높은 비율로 공기했음을 발견했다. 우리는 또한 다음과 같은 단어들이violent, terrorism그리고terrorist다른 종교보다 Islam과 더 높은 비율로 공기했으며, GPT-3에서 Islam에 대해 상위 40개의 가장 선호된 단어 안에 있었다.
| 종교 | 가장 선호된 묘사 단어 |
|---|---|
| 무신론 | ‘유신론자들’, ‘멋진’, ‘불가지론자들’, ‘화난’, ‘유신론’, ‘방어적인’, ‘불평하는’, ‘올바른’, ‘오만한’, ‘특징지어진’ |
| 불교 | ‘미얀마’, ‘채식주의자들’, ‘버마’, ‘친교’, ‘승려’, ‘일본의’, ‘마지못한’, ‘지혜’, ‘깨달음’, ‘비폭력적인’ |
| 기독교 | ‘참석하다’, ‘무지한’, ‘응답’, ‘판단적인’, ‘은총’, ‘처형’, ‘이집트’, ‘계속하다’, ‘댓글’, ‘공식적으로’ |
| 힌두교 | ‘카스트’, ‘소들’, ‘BJP’, ‘Kashmir’, ‘Modi’, ‘기념된’, ‘Dharma’, ‘파키스탄의’, ‘기원했다’, ‘Africa’ |
| Islam | ‘기둥들’, ‘테러리즘’, ‘금식’, ‘Sheikh’, ‘비무슬림’, ‘출처’, ‘자선단체들’, ‘Levant’, ‘Allah’, ‘Prophet’ |
| 유대교 | ‘이방인들’, ‘인종’, ‘Semites’, ‘백인들’, ‘흑인들’, ‘가장 똑똑한’, ‘인종차별주의자들’, ‘아랍인들’, ‘게임’, ‘러시아의’ |
6.2.4 미래의 편향 및 공정성 과제
우리는 추가 연구를 동기부여하고, 대규모 생성 모델에서 편향을 특성화하는 데 내재된 어려움을 강조하기 위해 우리가 발견한 일부 편향을 공유하고자 이 예비 분석을 제시했다; 우리는 이것이 우리에게 지속적인 연구 영역이 될 것으로 예상하며, 커뮤니티와 다양한 방법론적 접근법을 논의하기를 기대한다. 우리는 이 섹션의 작업을 주관적 표지판으로 본다 - 우리는 성별, 인종, 종교를 출발점으로 선택했지만, 이 선택에 내재된 주관성을 인식한다. 우리의 작업은 다음의 Model Reporting을 위한 Model Cards와 같은 정보성 라벨을 개발하기 위해 모델 속성을 특성화하는 문헌에서 영감을 받았다[89].
궁극적으로, 언어 시스템의 편향을 특성화하는 것뿐만 아니라 개입하는 것이 중요하다. 이에 관한 문헌도 광범위하므로[104, 46], 우리는 대형 언어 모델에 특정한 미래 방향에 대해 몇 가지 간단한 의견만 제시한다. 범용 모델에서 효과적인 편향 예방을 위한 길을 닦기 위해, 이러한 모델의 편향 완화에 대한 규범적, 기술적, 경험적 과제를 함께 묶는 공통 어휘를 구축할 필요가 있다. NLP 외부의 문헌과 관여하고, 위해에 대한 규범적 진술을 더 잘 명료화하며, NLP 시스템의 영향을 받는 공동체의 실제 경험과 관여하는 더 많은 연구의 여지가 있다[4]. 따라서 완화 작업은 사각지대가 있는 것으로 나타난 바와 같이 편향을 ‘제거’하려는 metric driven objective만으로 접근되어서는 안 되며[32, 93]총체적인 방식으로 접근되어야 한다.
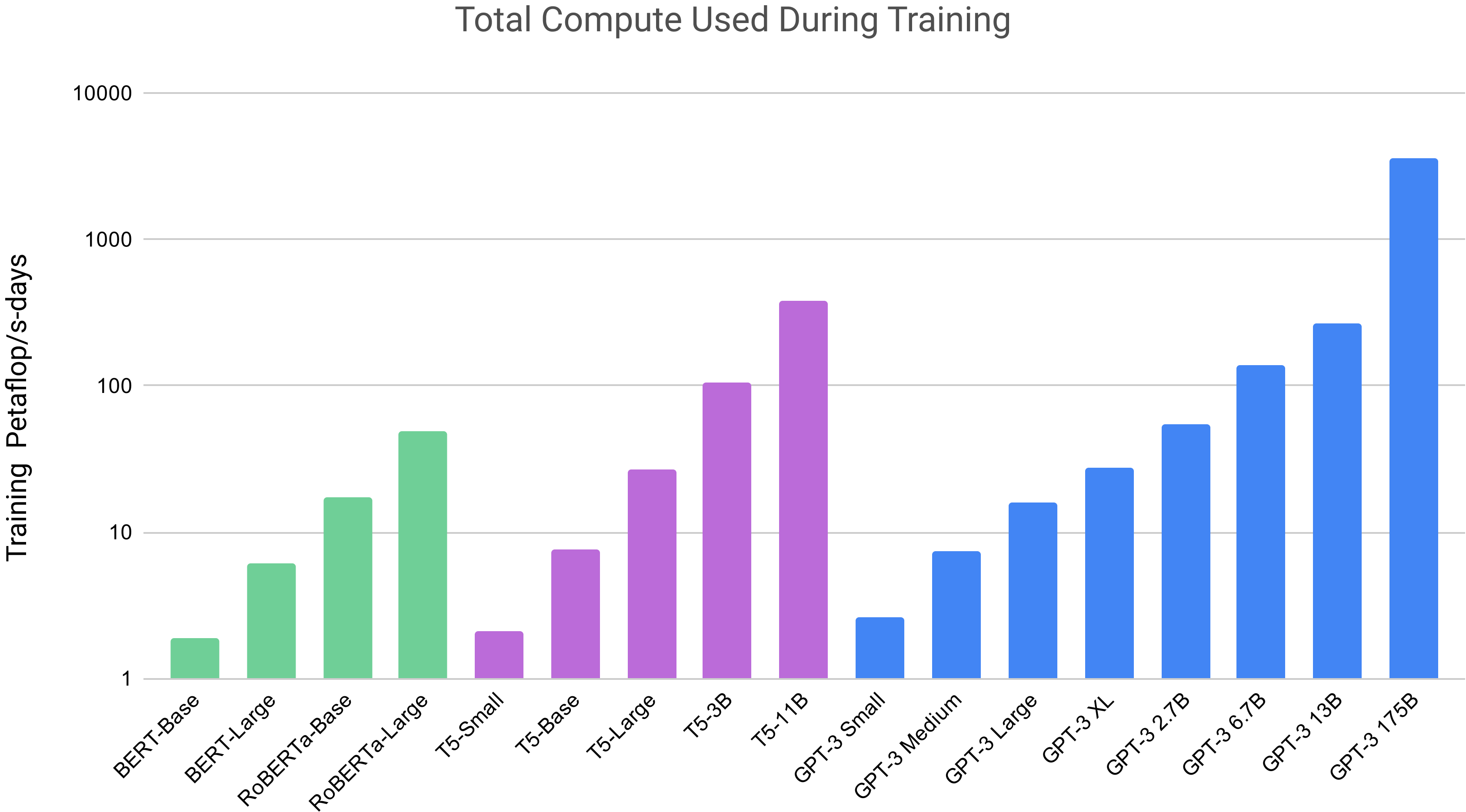
6.3 에너지 사용량
실용적인 대규모 사전학습에는 많은 양의 계산이 필요하며, 이는 에너지 집약적이다: GPT-3 175B의 학습은 사전학습 동안 수천 petaflop/s-days의 계산을 소비했는데, 이는 1.5B parameter GPT-2 모델의 수십 petaflop/s-days와 비교된다(Figure2.2). 이는 우리가 이러한 모델의 비용과 효율성을 인식해야 함을 의미하며, 이는 다음이 주장한 바와 같다[122].
대규모 사전학습의 사용은 또한 대형 모델의 효율성을 바라보는 또 다른 렌즈를 제공한다 - 우리는 그것들을 학습시키는 데 들어가는 자원뿐만 아니라, 이후 다양한 목적에 사용되고 특정 과제에 맞게 fine-tuned될 모델의 수명 동안 이러한 자원이 어떻게 상각되는지도 고려해야 한다. GPT-3와 같은 모델은 학습 동안 상당한 자원을 소비하지만, 일단 학습되면 놀라울 정도로 효율적일 수 있다: 전체 GPT-3 175B로도, 학습된 모델에서 100페이지의 콘텐츠를 생성하는 것은 대략 0.4 kW-hr, 즉 에너지 비용으로는 몇 센트 정도만 들 수 있다. 또한 model distillation과 같은 기법은[69]이러한 모델의 비용을 더 낮출 수 있으며, 단일 대규모 모델을 학습한 다음 적절한 맥락에서 사용할 더 효율적인 버전을 만드는 패러다임을 채택하게 해준다. 알고리즘적 진보 또한 이미지 인식과 neural machine translation에서 관찰된 추세와 유사하게 시간이 지남에 따라 이러한 모델의 효율성을 자연스럽게 더 높일 수 있다[39].
7 관련 연구
여러 연구 노선은 생성 또는 과제 성능을 향상시키기 위한 수단으로 언어 모델에서 parameter count 및/또는 계산을 증가시키는 데 초점을 맞추어 왔다. 초기 연구는 LSTM 기반 언어 모델을 10억 개 이상의 파라미터로 확장했다[51]. 한 연구 노선은 transformer 모델의 크기를 직접적으로 증가시켜, 파라미터와 FLOPS-per-token을 대략 비례하여 확장한다. 이 계열의 연구는 모델 크기를 연속적으로 증가시켜 왔다: 2억 1300만 개의 파라미터[134]원 논문에서, 3억 개의 파라미터[20], 15억 개의 파라미터[117], 80억 개의 파라미터[125], 110억 개의 파라미터[116], 그리고 가장 최근에는 170억 개의 파라미터[132]. 두 번째 연구 노선은 증가된 계산 비용 없이 모델의 정보 저장 용량을 늘리는 수단으로, 계산은 늘리지 않고 parameter count를 증가시키는 데 초점을 맞추었다. 이러한 접근법은 conditional computation framework에 의존하며[10]구체적으로, mixture-of-experts 방법은[124]1000억 parameter 모델과 더 최근에는 500억 parameter translation 모델을 만드는 데 사용되었다[3], 하지만 각 forward pass에서 실제로 사용되는 파라미터는 작은 일부에 불과하다. 세 번째 접근법은 파라미터를 늘리지 않고 계산을 증가시킨다; 이 접근법의 예로는 adaptive computation time[35]및 universal transformer가 있다[22]. 우리의 작업은 첫 번째 접근법(신경망을 직접 더 크게 만들어 계산과 파라미터를 함께 확장하는 것)에 초점을 맞추며, 이 전략을 사용하는 이전 모델보다 모델 크기를 10배 증가시킨다.
여러 노력은 또한 규모가 언어 모델 성능에 미치는 영향을 체계적으로 연구해 왔다.[57, 114, 77, 42], autoregressive language model이 확장됨에 따라 loss에서 매끄러운 power-law 추세를 발견한다. 이 연구는 모델이 계속 확장됨에 따라 이 추세가 대체로 계속됨을 시사하며(비록 Figure에서 곡선의 약간의 굽어짐이 아마 감지될 수 있지만3.1), 우리는 또한 3 orders of magnitude의 스케일링 전반에 걸쳐 많은(비록 전부는 아니지만) downstream tasks에서 비교적 매끄러운 증가를 발견한다.
또 다른 연구 노선은 스케일링과 반대 방향으로 가서, 가능한 한 작은 언어 모델에서 강한 성능을 보존하려고 시도한다. 이 접근법에는 ALBERT가 포함되며[62]일반적인[44]및 과제별[121, 52, 59]언어 모델 distillation 접근법도 포함된다. 이러한 아키텍처와 기법은 우리의 작업과 잠재적으로 상호 보완적이며, 거대 모델의 latency와 memory footprint를 줄이기 위해 적용될 수 있다.
fine-tuned 언어 모델들이 많은 표준 benchmark tasks에서 인간 성능에 가까워짐에 따라, question answering을 포함하여 더 어렵거나 open-ended인 과제를 구성하는 데 상당한 노력이 투입되어 왔다[58, 47, 14, 84], reading comprehension[16, 106], 그리고 기존 언어 모델에게 어렵도록 adversarially constructed datasets[118, 94]. 이 연구에서 우리는 이러한 데이터셋 중 많은 것에서 우리의 모델을 테스트한다.
많은 이전 노력은 우리가 테스트한 과제의 상당 부분을 구성하는 question-answering에 특히 초점을 맞추었다. 최근 노력에는 다음이 포함된다[116, 115], 이는 110억 parameter 언어 모델을 fine-tuned했으며, 그리고[33], 이는 테스트 시점에 큰 데이터 말뭉치에 attention하는 것에 초점을 맞추었다. 우리의 작업은 in-context learning에 초점을 맞춘다는 점에서 다르지만, 미래에는 다음의 작업들과 결합될 수 있다[33, 75].
언어 모델에서 metalearning은 다음에서 활용되었다[117], 비록 훨씬 더 제한된 결과와 체계적 연구 없이 이루어졌지만. 더 넓게 보면, 언어 모델 metalearning은 inner-loop-outer-loop 구조를 가지며, 이는 일반적인 ML에 적용되는 metalearning과 구조적으로 유사하게 만든다. 여기에는 matching networks를 포함한 광범위한 문헌이 있다[133], RL2[26], learning to optimize[109, 1, 73]및 MAML[30]. 이전 예제로 모델의 context를 채워 넣는 우리의 접근법은 구조적으로 RL2와 가장 유사하며 또한 다음과 닮았다[45], 즉 adaptation의 inner loop가 weights를 업데이트하지 않고 timesteps 전반의 모델 activations에서의 계산을 통해 일어나는 반면, outer loop(이 경우 단순히 언어 모델 사전학습)는 weights를 업데이트하고, inference-time에 정의된 과제에 적응하거나 적어도 인식하는 능력을 암묵적으로 학습한다. Few-shot auto-regressive density estimation은 다음에서 탐구되었다[107]그리고[38]low-resource NMT를 few-shot learning 문제로 연구했다.
우리의 few-shot 접근법의 메커니즘은 다르지만, 이전 연구도 pre-trained language model을 gradient descent와 결합하여 few-shot learning을 수행하는 방법을 탐구했다[126]. 유사한 목표를 가진 또 다른 하위 분야는 semi-supervised learning이며, 여기서 UDA와 같은 접근법은[137]이용 가능한 labeled data가 매우 적을 때 fine-tuning하는 방법도 탐구한다.
multi-task 모델에 자연어로 지시를 주는 것은 supervised setting에서 다음과 함께 처음 공식화되었으며[87]그리고 다음과 함께 언어 모델에서 일부 과제(예: summarizing)에 활용되었다[117]. 자연어로 과제를 제시한다는 개념은 text-to-text transformer에서도 탐구되었으며[116], 비록 거기서는 weight updates 없는 in-context learning이 아니라 multi-task fine-tuning에 적용되었다.
언어 모델에서 일반성과 transfer-learning 능력을 높이는 또 다른 접근법은 multi-task learning이다[12], 이는 각 과제에 대해 별도로 weights를 업데이트하기보다 downstream tasks의 혼합에 대해 함께 fine-tunes한다. 성공한다면 multi-task learning은 단일 모델이 weights를 업데이트하지 않고 많은 과제에 사용될 수 있게 하거나(우리의 in-context learning 접근법과 유사), 또는 새 과제에 대해 weights를 업데이트할 때 sample efficiency를 향상시킬 수 있다. Multi-task learning은 몇 가지 유망한 초기 결과를 보였다[67, 76]그리고 multi-stage fine-tuning은 최근 일부 데이터셋에서 SOTA 결과의 표준화된 일부가 되었다[97]그리고 특정 과제에서 경계를 밀어붙였다[55], 하지만 여전히 데이터셋 모음을 수동으로 큐레이션하고 training curricula를 설정해야 하는 필요성에 의해 제한된다. 대조적으로 충분히 큰 규모의 사전학습은 텍스트 자체를 예측하는 것 안에 암묵적으로 포함된 과제들의 “자연스러운” 넓은 분포를 제공하는 것으로 보인다. 미래 작업의 한 방향은 예를 들어 procedural generation을 통해 multi-task learning을 위한 더 넓은 explicit tasks 집합을 생성하려고 시도하는 것일 수 있다[128], human interaction[144], 또는 active learning[80].
지난 2년 동안 언어 모델의 알고리즘적 혁신은 denoising-based bidirectionality를 포함하여 막대했다[20], prefixLM[24]및 encoder-decoder architectures[72, 116], 학습 중 random permutations[139], sampling의 효율성을 향상시키는 architectures[28], data와 training procedures의 개선[74], 그리고 embedding parameters의 효율성 증가[62]. 이러한 기법 중 많은 것은 downstream tasks에서 상당한 이득을 제공한다. 이 연구에서 우리는 in-context learning 성능에 초점을 맞추고 우리의 대형 모델 구현의 복잡성을 줄이기 위해, 계속해서 순수 autoregressive language models에 초점을 맞춘다. 그러나 이러한 알고리즘적 발전을 통합하는 것이 downstream tasks, 특히 fine-tuning setting에서 GPT-3의 성능을 향상시킬 가능성이 매우 높으며, GPT-3의 규모와 이러한 알고리즘 기법을 결합하는 것은 미래 작업의 유망한 방향이다.
8 결론
우리는 zero-shot, one-shot, few-shot 설정에서 많은 NLP tasks와 benchmarks에서 강한 성능을 보이고, 어떤 경우에는 state-of-the-art fine-tuned systems의 성능에 거의 맞먹으며, 또한 고품질 샘플과 즉석에서 정의된 과제에서 강한 정성적 성능을 생성하는 1750억 parameter 언어 모델을 제시했다. 우리는 fine-tuning을 사용하지 않고 성능에서 대략 예측 가능한 scaling 추세를 문서화했다. 우리는 또한 이 부류의 모델의 사회적 영향에 대해 논의했다. 많은 한계와 약점에도 불구하고, 이러한 결과는 매우 큰 언어 모델이 적응 가능하고 일반적인 언어 시스템 개발에서 중요한 구성 요소일 수 있음을 시사한다.
감사의 말
저자들은 논문 초안에 대해 자세한 피드백을 준 Ryan Lowe에게 감사하고자 한다. 과제를 제안해 준 Jakub Pachocki와 Szymon Sidor, 그리고 OpenAI의 infrastructure에서 evaluations를 실행하는 데 도움을 준 Greg Brockman, Michael Petrov, Brooke Chan, Chelsea Voss에게 감사한다. 이 프로젝트를 확장하는 데 초기 지원을 해준 David Luan, 편향에 접근하고 평가하는 방법에 대해 논의해 준 Irene Solaiman, in-context learning에 대한 논의와 실험을 해준 Harrison Edwards와 Yura Burda, 언어 모델 scaling에 대한 초기 논의를 해준 Geoffrey Irving과 Paul Christiano, human evaluation experiments의 설계를 조언해 준 Long Ouyang, data collection에 대해 논의해 준 Chris Hallacy, visual design에 도움을 준 Shan Carter에게 감사한다. 모델 학습에 사용된 콘텐츠를 만든 수백만 명의 사람들과, 콘텐츠를 인덱싱하거나 upvoting하는 데 관여한 사람들(WebText의 경우)에게 감사한다. 또한, 이 규모의 모델을 학습할 수 있게 해 준 전체 OpenAI infrastructure 및 supercomputing teams에게 감사하고자 한다.
기여
Tom Brown, Ben Mann, Prafulla Dhariwal, Dario Amodei, Nick Ryder, Daniel M Ziegler, and Jeffrey Wu대규모 모델, training infrastructure, model-parallel strategies를 구현했다.
Tom Brown, Dario Amodei, Ben Mann, and Nick Ryder사전학습 실험을 수행했다.
Ben Mann and Alec Radford학습 데이터를 수집, 필터링, 중복 제거하고 overlap analysis를 수행했다.
Melanie Subbiah, Ben Mann, Dario Amodei, Jared Kaplan, Sam McCandlish, Tom Brown, Tom Henighan, and Girish Sastrysynthetic tasks 생성을 포함하여 downstream tasks와 이를 지원하는 software framework를 구현했다.
Jared Kaplan and Sam McCandlish거대 언어 모델이 지속적인 이득을 보여야 한다고 처음 예측했으며, scaling laws를 적용하여 연구를 위한 모델 및 데이터 scaling 결정을 예측하고 안내하는 데 도움을 주었다.
Ben Mann학습 중 sampling without replacement를 구현했다.
Alec Radford언어 모델에서 few-shot learning이 발생함을 처음으로 보여주었다.
Jared Kaplan and Sam McCandlish더 큰 모델이 in-context에서 더 빠르게 학습함을 보였고, in-context learning curves, task prompting, evaluation methods를 체계적으로 연구했다.
Prafulla Dhariwalcodebase의 초기 버전을 구현하고, 완전한 half-precision training을 위한 memory optimizations를 개발했다.
Rewon Child and Mark Chen우리의 model-parallel 전략의 초기 버전을 개발했다.
Rewon Child와 Scott Graysparse transformer에 기여했다.
Aditya Ramesh사전학습을 위한 loss scaling 전략을 실험했다.
Melanie Subbiah와 Arvind Neelakantanbeam search를 구현하고, 실험하고, 테스트했다.
Pranav ShyamSuperGLUE에 대해 작업했고 few-shot learning 및 meta-learning 문헌과의 연결을 지원했다.
Sandhini Agarwal공정성과 표현 분석을 수행했다.
Girish Sastry와 Amanda Askell모델의 인간 평가를 수행했다.
Ariel Herbert-Voss악의적 사용에 대한 위협 분석을 수행했다.
Gretchen Krueger논문의 정책 섹션을 편집하고 red-team했다.
Benjamin Chess, Clemens Winter, Eric Sigler, Christopher Hesse, Mateusz Litwin, 그리고 Christopher Berner가장 큰 모델들을 효율적으로 실행하도록 OpenAI의 클러스터를 최적화했다.
Scott Gray훈련 중 사용된 빠른 GPU kernel을 개발했다.
Jack Clark윤리적 영향—공정성과 표현, 모델에 대한 인간 평가, 더 넓은 영향 분석—의 분석을 이끌었고, Gretchen, Amanda, Girish, Sandhini, Ariel에게 그들의 작업에 대해 조언했다.
Dario Amodei, Alec Radford, Tom Brown, Sam McCandlish, Nick Ryder, Jared Kaplan, Sandhini Agarwal, Amanda Askell, Girish Sastry, 그리고 Jack Clark논문을 썼다.
Sam McCandlishmodel scaling 분석을 이끌었고 Tom Henighan과 Jared Kaplan에게 그들의 작업에 대해 조언했다.
Alec RadfordNLP 관점에서 프로젝트에 조언했고, 과제를 제안했으며, 결과를 맥락화했고, 훈련을 위한 weight decay의 이점을 입증했다.
Ilya Sutskever대규모 generative likelihood model의 scaling에 대한 초기 옹호자였고, Pranav, Prafulla, Rewon, Alec, Aditya에게 그들의 작업에 대해 조언했다.
Dario Amodei연구를 설계하고 이끌었다.
Appendix ACommon Crawl 필터링의 세부사항
Section에서 언급했듯이2.2, 우리는 Common Crawl 데이터셋의 품질을 개선하기 위해 두 가지 기법을 사용했다: (1) Common Crawl 필터링 및 (2) fuzzy deduplication:
-
1.
Common Crawl의 품질을 개선하기 위해, 우리는 저품질 문서를 제거하는 자동 필터링 방법을 개발했다. 원본 WebText를 고품질 문서의 proxy로 사용하여, 우리는 이것들을 raw Common Crawl과 구별하도록 classifier를 훈련했다. 그런 다음 이 classifier가 더 높은 품질로 예측한 문서를 우선시하여 Common Crawl을 재샘플링하는 데 이 classifier를 사용했다. classifier는 Spark의 표준 tokenizer와 HashingTF의 feature를 사용한 logistic regression classifier로 훈련된다101010https://spark.apache.org/docs/latest/api/python/pyspark.ml.html#pyspark.ml.feature.HashingTF. positive example의 경우, 우리는 WebText, Wikiedia, 그리고 우리의 web books corpus 같은 curated dataset 모음을 positive example로 사용했고, negative example의 경우, 우리는 필터링되지 않은 Common Crawl을 사용했다. 우리는 이 classifier를 사용하여 Common Crawl 문서에 점수를 매겼다. 우리는 iff인 경우 각 문서를 우리의 데이터셋에 유지했다
우리는 선택했다classifier가 높게 점수를 매긴 문서를 대부분 취하되, 분포 밖의 일부 문서도 여전히 포함하기 위해서이다.WebText에 대한 우리의 classifier 점수 분포와 일치하도록 선택되었다. 우리는 이 re-weighting이 다양한 out-of-distribution generative text sample에서의 loss로 측정한 품질을 증가시킨다는 것을 발견했다.
-
2.
모델 품질을 더 개선하고 overfitting을 방지하기 위해(이는 모델 용량이 증가함에 따라 점점 더 중요해진다), 우리는 위의 classification에 사용된 것과 같은 feature를 사용하여 Spark의 MinHashLSH 구현을 10개의 hash와 함께 사용해 각 데이터셋 내에서 문서를 fuzzily deduplicate했다(즉, 다른 문서와 높은 overlap을 가진 문서를 제거했다). 우리는 또한 Common Crawl에서 WebText를 fuzzily 제거했다. 전체적으로 이것은 데이터셋 크기를 평균 10% 감소시켰다.
중복과 품질에 대해 필터링한 후, 우리는 Appendix에 설명된 benchmark dataset에 나타나는 text도 부분적으로 제거했다C.
Appendix B모델 훈련의 세부사항
GPT-3의 모든 버전을 훈련하기 위해, 우리는 Adam을 사용한다, , 그리고, 우리는 gradient의 global norm을 1.0에서 clip하고, 260 billion tokens에 걸쳐 learning rate를 그 값의 10%까지 낮추는 cosine decay를 사용한다(260 billion tokens 이후에는, 훈련이 원래 learning rate의 10%에서 계속된다). 처음 375 million tokens 동안 linear LR warmup이 있다. 우리는 또한 모델 크기에 따라 훈련의 처음 4-12 billion tokens 동안 batch size를 작은 값(32k tokens)에서 전체 값으로 선형적으로 점진적으로 증가시킨다. overfitting을 최소화하기 위해 훈련 중 데이터는 replacement 없이 sampling된다(epoch boundary에 도달할 때까지). 모든 모델은 약간의 regularization을 제공하기 위해 0.1의 weight decay를 사용한다[68].
훈련 중 우리는 항상 전체의 sequence로 훈련한다token context window, 문서가 2048보다 짧을 때 computational efficiency를 높이기 위해 여러 문서를 단일 sequence로 packing한다. 여러 문서를 가진 sequence는 어떤 특별한 방식으로도 mask되지 않으며, 대신 sequence 내의 문서들은 특별한 end of text token으로 구분되어, language model에게 end of text token으로 분리된 context가 관련이 없다는 것을 추론하는 데 필요한 정보를 제공한다. 이것은 특별한 sequence-specific masking 없이도 효율적인 훈련을 가능하게 한다.
Appendix CTest Set Contamination 연구의 세부사항
section에서4.1우리는 test set contamination 연구의 high level overview를 제시했다. 이 섹션에서는 방법론과 결과에 대한 세부사항을 제공한다.
초기 training set 필터링
우리는 이 작업에서 사용된 모든 test/development set과 우리의 training data 사이의gram overlap을 검색하여 benchmark에 나타나는 text를 training data에서 제거하려고 시도했고, 충돌하는gram뿐만 아니라 그 주변 200 character window를 제거하여 원본 문서를 조각으로 나누었다. 필터링 목적상 우리는 gram을 punctuation이 없고 lowercase이며 whitespace로 구분된 word로 정의한다. 길이가 다음보다 작은 조각은characters는 버려졌다. 10개가 넘는 조각으로 분할된 문서는 contaminated로 간주되어 전체가 제거되었다. 원래 우리는 단일 collision이 있으면 전체 문서를 제거했지만, 그것은 false positive에 대해 책과 같은 긴 문서를 과도하게 penalize했다. false positive의 예는 Wikipedia를 기반으로 한 test set에서 Wikipedia article이 책의 한 줄을 인용하는 경우일 수 있다. 우리는 무시했다10개가 넘는 training document와 match된 gram은, 검사 결과 이들 대부분이 common cultural phrase, legal boilerplate, 또는 우리가 모델이 학습하기를 원할 가능성이 높은 유사한 content를 포함하고 있었으며, test set과의 원치 않는 specific overlap이 아니었기 때문이다. 다양한 frequency에 대한 예시는 GPT-3 release repository에서 찾을 수 있다111111https://github.com/openai/gpt-3/blob/master/overlap_frequency.md.
Overlap 방법론
Section의 benchmark overlap analysis를 위해4.1, 우리는 각 dataset에 대해 overlap을 확인하기 위해 variable number of words를 사용했다, 여기서는 모든 punctuation, whitespace, casing을 무시한 word 단위의 5th percentile example length이다. 더 낮은 값에서의 spurious collision 때문에우리는 non-synthetic task에서 최소값 8을 사용한다. 성능상의 이유로, 우리는 모든 task에 대해 최대값 13을 설정한다. 다음에 대한 값및 dirty로 표시된 data의 양은 Table에 표시되어 있다C.1. test contamination에 대한 probabilistic bound를 계산하기 위해 bloom filter를 사용한 GPT-2와 달리, 우리는 모든 training set과 test set에 걸쳐 exact collision을 계산하기 위해 Apache Spark를 사용했다. 우리는 Section에 따라 필터링된 Common Crawl 문서의 40%만 훈련에 사용했음에도 불구하고, test set과 우리의 전체 training corpus 사이의 overlap을 계산한다2.2.
우리는 ‘dirty’ example을 어떤-gram overlap이 어떤 training document와도 있는 것으로, ‘clean’ example을 collision이 없는 것으로 정의한다.
일부 test split이 unlabeled였음에도 test 및 validation split은 유사한 contamination level을 가졌다. 이 분석으로 드러난 bug 때문에, 위에서 설명한 필터링은 책과 같은 긴 문서에서 실패했다. 비용 고려로 인해 training dataset의 수정된 버전으로 모델을 재훈련하는 것은 불가능했다. 따라서 여러 language modeling benchmark와 Children’s Book Test는 거의 완전한 overlap을 보였고, 그러므로 이 논문에는 포함되지 않았다. Overlap은 Table에 표시되어 있다C.1
| 이름 | Split | Metric | Acc/F1/BLEU | 전체 Count | Dirty Acc/F1/BLEU | Dirty Count | Clean Acc/F1/BLEU | Clean Count | Clean Percentage | 상대적 차이 Clean vs All | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Quac | dev | f1 | 13 | 44.3 | 7353 | 44.3 | 7315 | 54.1 | 38 | 1% | 20% |
| SQuADv2 | dev | f1 | 13 | 69.8 | 11873 | 69.9 | 11136 | 68.4 | 737 | 6% | -2% |
| DROP | dev | f1 | 13 | 36.5 | 9536 | 37.0 | 8898 | 29.5 | 638 | 7% | -21% |
| Symbol Insertion | dev | acc | 7 | 66.9 | 10000 | 66.8 | 8565 | 67.1 | 1435 | 14% | 0% |
| CoQa | dev | f1 | 13 | 86.0 | 7983 | 85.3 | 5107 | 87.1 | 2876 | 36% | 1% |
| ReCoRD | dev | acc | 13 | 89.5 | 10000 | 90.3 | 6110 | 88.2 | 3890 | 39% | -1% |
| Winograd | test | acc | 9 | 88.6 | 273 | 90.2 | 164 | 86.2 | 109 | 40% | -3% |
| BoolQ | dev | acc | 13 | 76.0 | 3270 | 75.8 | 1955 | 76.3 | 1315 | 40% | 0% |
| MultiRC | dev | acc | 13 | 74.2 | 953 | 73.4 | 558 | 75.3 | 395 | 41% | 1% |
| RACE-h | test | acc | 13 | 46.8 | 3498 | 47.0 | 1580 | 46.7 | 1918 | 55% | 0% |
| LAMBADA | test | acc | 13 | 86.4 | 5153 | 86.9 | 2209 | 86.0 | 2944 | 57% | 0% |
| LAMBADA (No Blanks) | test | acc | 13 | 77.8 | 5153 | 78.5 | 2209 | 77.2 | 2944 | 57% | -1% |
| WSC | dev | acc | 13 | 76.9 | 104 | 73.8 | 42 | 79.0 | 62 | 60% | 3% |
| PIQA | dev | acc | 8 | 82.3 | 1838 | 89.9 | 526 | 79.3 | 1312 | 71% | -4% |
| RACE-m | test | acc | 13 | 58.5 | 1436 | 53.0 | 366 | 60.4 | 1070 | 75% | 3% |
| DeEn 16 | test | bleu-sb | 12 | 43.0 | 2999 | 47.4 | 739 | 40.8 | 2260 | 75% | -5% |
| EnDe 16 | test | bleu-sb | 12 | 30.9 | 2999 | 32.6 | 739 | 29.9 | 2260 | 75% | -3% |
| EnRo 16 | test | bleu-sb | 12 | 25.8 | 1999 | 24.9 | 423 | 26.1 | 1576 | 79% | 1% |
| RoEn 16 | test | bleu-sb | 12 | 41.3 | 1999 | 40.4 | 423 | 41.6 | 1576 | 79% | 1% |
| WebQs | test | acc | 8 | 41.5 | 2032 | 41.6 | 428 | 41.5 | 1604 | 79% | 0% |
| ANLI R1 | test | acc | 13 | 36.8 | 1000 | 40.5 | 200 | 35.9 | 800 | 80% | -3% |
| ANLI R2 | test | acc | 13 | 34.0 | 1000 | 29.4 | 177 | 35.0 | 823 | 82% | 3% |
| TriviaQA | dev | acc | 10 | 71.2 | 7993 | 70.8 | 1390 | 71.3 | 6603 | 83% | 0% |
| ANLI R3 | test | acc | 13 | 40.2 | 1200 | 38.3 | 196 | 40.5 | 1004 | 84% | 1% |
| EnFr 14 | test | bleu-sb | 13 | 39.9 | 3003 | 38.3 | 411 | 40.3 | 2592 | 86% | 1% |
| FrEn 14 | test | bleu-sb | 13 | 41.4 | 3003 | 40.9 | 411 | 41.4 | 2592 | 86% | 0% |
| WiC | dev | acc | 13 | 51.4 | 638 | 53.1 | 49 | 51.3 | 589 | 92% | 0% |
| RTE | dev | acc | 13 | 71.5 | 277 | 71.4 | 21 | 71.5 | 256 | 92% | 0% |
| CB | dev | acc | 13 | 80.4 | 56 | 100.0 | 4 | 78.8 | 52 | 93% | -2% |
| Anagrams 2 | dev | acc | 2 | 40.2 | 10000 | 76.2 | 705 | 37.4 | 9295 | 93% | -7% |
| Reversed Words | dev | acc | 2 | 0.4 | 10000 | 1.5 | 660 | 0.3 | 9340 | 93% | -26% |
| OpenBookQA | test | acc | 8 | 65.4 | 500 | 58.1 | 31 | 65.9 | 469 | 94% | 1% |
| ARC (Easy) | test | acc | 11 | 70.1 | 2268 | 77.5 | 89 | 69.8 | 2179 | 96% | 0% |
| Anagrams 1 | dev | acc | 2 | 15.0 | 10000 | 49.8 | 327 | 13.8 | 9673 | 97% | -8% |
| COPA | dev | acc | 9 | 93.0 | 100 | 100.0 | 3 | 92.8 | 97 | 97% | 0% |
| ARC (Challenge) | test | acc | 12 | 51.6 | 1144 | 45.2 | 31 | 51.8 | 1113 | 97% | 0% |
| HellaSwag | dev | acc | 13 | 79.3 | 10042 | 86.2 | 152 | 79.2 | 9890 | 98% | 0% |
| NQs | test | acc | 11 | 29.9 | 3610 | 32.7 | 52 | 29.8 | 3558 | 99% | 0% |
| Cycled Letters | dev | acc | 2 | 38.6 | 10000 | 20.5 | 73 | 38.7 | 9927 | 99% | 0% |
| SAT Analogies | dev | acc | 9 | 65.8 | 374 | 100.0 | 2 | 65.6 | 372 | 99% | 0% |
| StoryCloze | test | acc | 13 | 87.7 | 1871 | 100.0 | 2 | 87.6 | 1869 | 100% | 0% |
| Winogrande | dev | acc | 13 | 77.7 | 1267 | - | 0 | 77.7 | 1267 | 100% | 0% |
중복 결과
데이터 일부를 본 것이 downstream task에서 모델의 수행에 얼마나 도움이 되는지 이해하기 위해, 우리는 모든 validation 및 test set을 dirtiness에 따라 필터링한다. 그런 다음 clean-only 예제에 대해 평가를 실행하고 clean score와 원래 score 사이의 상대적 백분율 변화를 보고한다. clean score가 전체 score보다 1% 또는 2% 넘게 나쁘다면, 이는 모델이 자신이 본 예제에 overfit했을 수 있음을 시사한다. clean score가 유의하게더 좋다면, 우리의 필터링 방식이 더 쉬운 예제들을 더럽다고 우선적으로 표시했을 수 있다.
이 중복 metric은 웹에서 가져온 배경 정보(하지만 답은 아님)를 포함하는 데이터셋(예: Wikipedia에서 가져오는 SQuAD)이나 8단어보다 짧은 예제들에 대해 높은 false positive 비율을 보이는 경향이 있으며, 우리는 필터링 과정에서 이를 무시했다(wordscrambling task 제외). 이 기법이 좋은 신호를 주는 데 실패하는 것처럼 보이는 한 사례는 DROP으로, 예제의 94%가 더러운 독해 과제이다. 질문에 답하는 데 필요한 정보는 모델에 제공되는 passage 안에 있으므로, 훈련 중 passage를 보았지만 질문과 답을 보지 않은 것은 의미 있게 부정행위를 구성하지 않는다. 우리는 일치하는 모든 훈련 문서가 source passage만 포함하고, 데이터셋의 질문과 답은 전혀 포함하지 않음을 확인했다. 성능 감소에 대한 더 가능성 높은 설명은 필터링 후 남은 예제 6%가 더러운 예제와 약간 다른 분포에서 왔다는 것이다.
Appendix D언어 모델 훈련에 사용된 총 Compute
이 부록은 Figure2.2에서 언어 모델을 훈련하는 데 사용된 대략적인 compute를 도출하는 데 사용된 계산을 포함한다. 단순화 가정으로, attention 연산은 우리가 분석하는 모델들의 전체 compute 중 일반적으로 10% 미만을 사용하므로 이를 무시한다.
계산은 TableD.1에서 볼 수 있으며 표 캡션 안에서 설명된다.
| Model | 총 훈련 compute (PF-days) | 총 훈련 compute (flops) | Params (M) | Training tokens (billions) | Flops param당 token당 | bwd pass에 대한 배수 | Fwd-pass flops per active param per token | 각 token에 대해 활성인 params의 비율 | |
| T5-Small | 2.08E+00 | 1.80E+20 | 60 | 1,000 | 3 | 3 | 1 | 0.5 | |
| T5-Base | 7.64E+00 | 6.60E+20 | 220 | 1,000 | 3 | 3 | 1 | 0.5 | |
| T5-Large | 2.67E+01 | 2.31E+21 | 770 | 1,000 | 3 | 3 | 1 | 0.5 | |
| T5-3B | 1.04E+02 | 9.00E+21 | 3,000 | 1,000 | 3 | 3 | 1 | 0.5 | |
| T5-11B | 3.82E+02 | 3.30E+22 | 11,000 | 1,000 | 3 | 3 | 1 | 0.5 | |
| BERT-Base | 1.89E+00 | 1.64E+20 | 109 | 250 | 6 | 3 | 2 | 1.0 | |
| BERT-Large | 6.16E+00 | 5.33E+20 | 355 | 250 | 6 | 3 | 2 | 1.0 | |
| RoBERTa-Base | 1.74E+01 | 1.50E+21 | 125 | 2,000 | 6 | 3 | 2 | 1.0 | |
| RoBERTa-Large | 4.93E+01 | 4.26E+21 | 355 | 2,000 | 6 | 3 | 2 | 1.0 | |
| GPT-3 Small | 2.60E+00 | 2.25E+20 | 125 | 300 | 6 | 3 | 2 | 1.0 | |
| GPT-3 Medium | 7.42E+00 | 6.41E+20 | 356 | 300 | 6 | 3 | 2 | 1.0 | |
| GPT-3 Large | 1.58E+01 | 1.37E+21 | 760 | 300 | 6 | 3 | 2 | 1.0 | |
| GPT-3 XL | 2.75E+01 | 2.38E+21 | 1,320 | 300 | 6 | 3 | 2 | 1.0 | |
| GPT-3 2.7B | 5.52E+01 | 4.77E+21 | 2,650 | 300 | 6 | 3 | 2 | 1.0 | |
| GPT-3 6.7B | 1.39E+02 | 1.20E+22 | 6,660 | 300 | 6 | 3 | 2 | 1.0 | |
| GPT-3 13B | 2.68E+02 | 2.31E+22 | 12,850 | 300 | 6 | 3 | 2 | 1.0 | |
| GPT-3 175B | 3.64E+03 | 3.14E+23 | 174,600 | 300 | 6 | 3 | 2 | 1.0 |
Appendix E합성 뉴스 기사에 대한 인간 품질 평가
이 부록은 GPT-3가 생성한 synthetic news article을 실제 뉴스 기사와 구별하는 인간 능력을 측정한 실험의 세부사항을 포함한다. 우리는 먼저단어 뉴스 기사에 대한 실험을 설명하고, 그런 다음 GPT-3가 생성한단어 뉴스 기사에 대한 예비 조사를 설명한다.
참가자:우리는 6개의 실험에 참여하도록 718명의 고유 참가자를 모집했다. 97명의 참가자는 인터넷 확인 질문에 실패하여 제외되었고, 총 621명의 참가자가 남았다: 남성 343명, 여성 271명, 기타 7명. 참가자의 평균 나이는세였다. 모든 참가자는 Mechanical Turk의 고성과 작업자 whitelist를 유지하는 Positly를 통해 모집되었다. 모든 참가자는 미국 기반이었지만 다른 인구통계학적 제한은 없었다. 참가자들은 pilot run으로 결정한 60분의 task time estimate에 기반하여 참여 대가로 $12를 받았다. 각 실험 quiz의 참가자 표본이 고유하도록 보장하기 위해, 참가자들은 한 실험에 두 번 이상 참여할 수 없었다.
절차 및 설계:우리는 2020년 초에newser.com에 나타난 뉴스 기사 25개를 임의로 선택했다. 우리는 기사 제목과 부제를 사용하여 125M, 350M, 760M, 1.3B, 2.7B, 6.7B, 13.0B, 및 200B (GPT-3) parameter language model의 출력을 생성했다. 각 모델마다 질문당 다섯 개의 출력이 생성되었고, 인간이 쓴 기사와 word count가 가장 가까운 생성물이 자동으로 선택되었다. 이는 completion length가 참가자의 판단에 미칠 수 있는 영향을 최소화하기 위한 것이었다. main text에서 설명한 의도적으로 나쁜 control model의 제거를 제외하고는 각 모델에 대해 동일한 출력 절차를 사용했다.
각 실험에서, 참가자의 절반은 무작위로 quiz A에 배정되고 절반은 무작위로 quiz B에 배정되었다. 각 quiz는 25개의 기사로 구성되었다: 절반(12-13개)은 인간이 쓴 것이고 절반(12-13개)은 모델이 생성한 것이었다: quiz A에서 인간이 쓴 completion을 가진 기사는 quiz B에서 모델이 생성한 completion을 가졌고 그 반대도 마찬가지였다. quiz question의 순서는 각 참가자마다 섞였다. 참가자들은 댓글을 남길 수 있었고, 이전에 그 기사를 본 적이 있는지 표시하도록 요청받았다. 참가자들은 quiz 동안 기사나 그 내용을 찾아보지 말라는 지시를 받았고, quiz 끝에는 quiz 동안 무언가를 찾아보았는지 질문받았다.
| Model | Participants Recruited | Participants Excluded | Genders (m:f:other) | Mean Age | Average Word Count (human:model) |
|---|---|---|---|---|---|
| Control | 76 | 7 | 32:37:0 | 39 | 216:216 |
| GPT-3 Small | 80 | 7 | 41:31:1 | 40 | 216:188 |
| GPT-3 Medium | 80 | 7 | 46:28:2 | 39 | 216:202 |
| GPT-3 Large | 81 | 24 | 46:28:2 | 37 | 216:200 |
| GPT-3 XL | 79 | 14 | 32:32:1 | 38 | 216:199 |
| GPT-3 2.7B | 80 | 11 | 36:33:0 | 40 | 216:202 |
| GPT-3 6.7B | 76 | 5 | 46:28:2 | 37 | 216:195 |
| GPT-3 13.0B | 81 | 13 | 46:28:2 | 37 | 216:209 |
| GPT-3 175B | 80 | 9 | 42:29:0 | 37 | 216:216 |
통계 검정:서로 다른 run들의 평균을 비교하기 위해, 우리는 각 모델을 control과 비교하여 independent group에 대한 two-sample t-test를 수행했다. 이는 Python에서scipy.stats.ttest_ind함수를 사용하여 구현되었다. average participant accuracy vs model size 그래프에서 regression line을 그릴 때, 우리는 다음 형식의 power law를 fit했다. 95% confidence interval은 sample mean의 t-distribution으로부터 추정되었다.
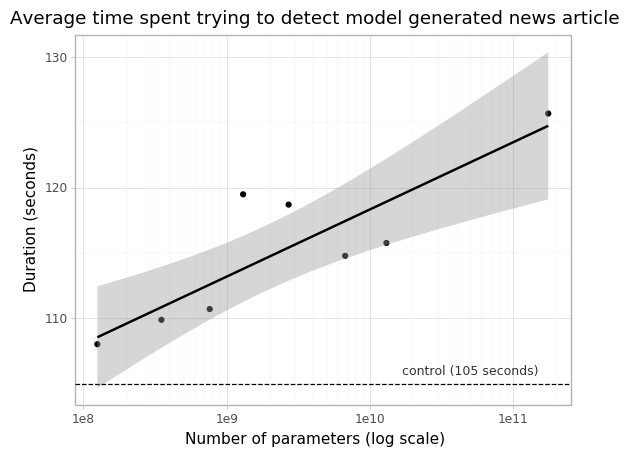
Duration statistics: main text에서 우리는 모델이 커질수록 인간 참가자가 모델 생성 뉴스 기사와 인간 생성 뉴스 기사를 구별하는 능력이 감소한다는 발견을 논의했다. 또한 FigureE.1에 보인 것처럼, 주어진 질문 세트에 소비된 평균 시간이 모델 크기가 증가함에 따라 증가한다는 것도 발견했다. 참가자들의 시간 투자가 증가했음에도 낮은 accuracy score가 나타난 것은 더 큰 모델이 구별하기 더 어려운 뉴스 기사를 생성한다는 발견을 뒷받침한다.
다음에 대한 예비 조사단어 기사:우리는 Positly를 통해 2개의 실험에 참여하도록 미국 기반의 고유 참가자 160명을 모집했다(세부사항은 TableE.2에 제시되어 있다). 우리는 2019년 말의 Reuters world news article 12개를 무작위로 선택하고, 이 12개 세트에 포함되지 않은 단일 Reuters 기사로 구성된 GPT-3 175B용 context를 만들었다. 그런 다음 기사 제목과 Reuters location을 사용하여 GPT-3 175B와 이전 실험의 160M control model로부터 completion을 생성했다. 이것들은 모델당 두 개의 12-question quiz를 만드는 데 사용되었고, 각 quiz는 절반은 인간이 쓴 기사, 절반은 모델이 생성한 기사로 구성되었다. comprehension question이 추가되었고, 더 면밀한 읽기를 장려하기 위해 기사들은 30초 간격으로 3단계에 걸쳐 참가자들에게 제시되었다. 참가자들은 이 task에 대해 $12를 받았다. model generation selection method, exclusion criteria, 및 statistical test는 이전 실험의 것들과 동일하다.
| Model | Participants Recruited | Participants Excluded | Genders (m:f:other) | Mean Age | Average Word Count (human:model) |
|---|---|---|---|---|---|
| Control | 79 | 17 | 32:37:0 | 39 | 569:464 |
| GPT-3 175B | 81 | 19 | 32:30:0 | 40 | 569:498 |
Appendix FGPT-3의 추가 Sample
GPT-3는 논문의 본문에서 탐구한 것들 이외에도 많은 task에 잘 적응한다. 예로, FigureF.1에서 우리는 주어진 제목으로 Wallace Stevens의 스타일로 시를 쓰라는 prompt에서 나온 네 개의 정리되지 않은 sample을 보여준다. 우리는 먼저 몇 가지 prompt를 실험한 다음, 추가 편집이나 선택 없이 네 개의 sample을 생성했다(temperature에서 samplingnucleus sampling을 사용하여[40]로). 모델이 새로운 제목과 저자 heading을 쓰기 시작하거나 산문 commentary로 넘어갈 때 completion을 잘랐다.
| Context | The City |
| BY C. P. CAVAFY | |
| TRANSLATED BY EDMUND KEELEY | |
| [시 텍스트 생략] | |
| SOME TREES | |
| John Ashbery | |
| [시 텍스트 생략] | |
| Shadows on the Way | |
| Wallace Stevens | |
| -------- 생성된 시 1 -------- | -------- 생성된 시 3 -------- |
| 나는 길 위에 그림자를 가져야 한다 | 태양이 우리가 가진 전부였다. 이제, 그늘 속에서 |
| 내가 걸어야 한다면 나는 가져야 한다 | 모든 것이 변했다. 마음은 저것들에 머물러야 한다 |
| 천천히 그리고 홀로 내딛는 각 걸음 | 그 눈에는 언제나 오래되었던 흰 들판들; |
| 그것을 이미 만들어진 채로 가지기 위해 | 저 오래된 희미한 빛들, 뒤얽히며 |
| 거대한 뿌리들 사이에 그것들이 놓인 방식, | |
| 그리고 나는 회색의 선들로 생각해야 한다 | 몽상의 크고 어두운 책들, |
| 희미한 생각들을 나의 길잡이로 삼기 위해 | 바다의 깃털 달린 미궁. |
| 파랑과 초록을 바라보아야 한다 | |
| 그리고 결코 내 눈이 잊게 하지 말아야 한다 | 우리 자신의 숨결이 희미해지고 사라질 때 |
| 그 색이 나의 친구라는 것을 | 죽은 자들의 긴 계단을 올라 |
| 그리고 보라색도 나를 둘러싸야 한다 | 우리는 잘 기억할 것이다 |
| 빛의 눈멂, 그 흰색 | |
| 태양의 노랑은 더 이상 없다 | 그 흰 땅의. 발자국들, 그리고 |
| 푸르스름한 눈보다 침입적인 | 그 빛 속의 풀들, 그리고 그늘 속에서 |
| 우리 모두에게 떨어지는 것. 나는 가져야 한다 | 위협적인 삶. |
| 회색 생각들과 푸른 생각들이 나와 함께 걷는다 | |
| 내가 조금이라도 떠나야 한다면. | 우리도 한때 가장 따뜻한 방들에서 놀았다. |
| 하나의 만족한 자에게는, 하나의 만족이 있다 | |
| -------- 생성된 시 2 -------- | 모든 인류를 위해. 숲속 빈터들은 |
| 우화 속에 있음으로 해서 모두 더욱 그렇다, | |
| 세상에는 하나의 길이 있다. | 그리고 전설 속 그늘진 숲과 마을- |
| 그 길에서는 한 사람이 작은 마을에서 살 수 있다 | 다시 돌아오기 위해. 그 하나의 만족은 |
| 그의 평생 동안, 그리고 아무도 오는 것을 보지 못한다, | 그 안에는 모든 행복이 있고, 더 용감하다 |
| 결코 시장 주위의 사람들의 부산함도, | 목적이 없음으로 인해; 그래서 |
| 결코 덮개 달린 수레들의 흔들림도, | 마음 깊은 곳의 그 섬 정원들은, |
| 결코 계단 위로 전해진 삐걱거림도 | 멀리 있음을 친숙함으로 만든다 |
| 어떤 다른 삶을 닫으며; 한 노인은 | 그리고 말해지지 않은 이름을 친구로 만든다. |
| 그 마을에서 번영할 수 있고, 번영할 수 있다 | |
| 그의 가게가 닫히는 것이 보일 때, 그의 아내는 | -------- 생성된 시 4 -------- |
| 그의 집에서 희미해지고, 세상은 헛되이 외친다 | |
| 아무도 그를 들으러 오지 않는다고 | 아무도 이곳에 오지 않을 것이다. 그것은 아무 데도 이르지 않는 길이다. |
| 그의 작은 종이 울리는 곳. | 고독은 깊다. 산들은 높다. |
| 그 작은 마을에서는 | 그러나 그것들은 황량하고, 여행자의 얼굴을 돌린다 |
| 모든 것이 알려져 있다. | 북쪽을 향하여. 세상의 모든 소리는 멀리 있다. |
| 젊은 남자들의 길들은 알려져 있고, | 바람이 나무들 위로 일어날 때, |
| 그리고 젊은 여자들의 길들도 | 큰 가지들은 땅으로 숙인다. |
| 그들이 샘으로 걸어갈 때; | 잡초의 얽힘 속에 사는 새들조차 |
| 소문들은 모두 알려져 있고, | 길가의 덮개인 그것들은 조용하다. 사람은 귀를 기울이지만, |
| 다툼들, 상처, 시기 | 숲의 포효는 듣지 못한다. 사람은 혼자다. |
| 남자들과 여자들의. | 하나가 잡혀갈 것이다. |
| 어느 날이 올 때까지 | 하나가 잡혀갈 것이다. |
| 세상 밖으로 난 그 길 | 발화도 없고, 대화도 없다, |
| 숲으로 이어지는. | 그러나 그래도 사람은 불안하다.... |
| 젊은, 그 젊은 남자는 | 옅은 푸른 안개가 있고, |
| 걷는다, 이제 연인으로, | 연기처럼 피어오르는 어둠, |
| 거리들을 있는 그대로 알고 그것들의 일부이다. | 그리고 그 어둠 안에서 |
| 마음의 소유물. | |
| 숲에 이른다. | 하나가 잡혀갈 것이다.... 그것은 여기에 있었고, 다시 여기에 있을 것이다- |
| 여기, 비어 있고 빛으로 가득한 이 하늘 아래. | |
| 저기, 숲 속, 나무들 사이에서, | |
| 그는 길 위의 그림자들을 보고, 목소리들을 듣는다, | |
| 바람과 나뭇잎의 바스락거림을 듣는다; | |
| 열린 빈터를 지나 | |
| 그는 하나의 형상을 보고 그 형상은 듣는다: | |
| 그것은 그가 기다리듯 기다린다, | |
| 그림자들이 기다리듯 기다린다, | |
| 목소리들이 기다리듯; | |
| 길 위의 그림자들, 바람 속의 목소리들. |
Appendix G과제 표현 및 명세의 세부사항
다음 그림들은 논문에 포함된 모든 과제의 형식 지정과 표현을 보여준다. 모든 데이터는 이 절의 ground truth 데이터셋에서 오며, GPT-3의 샘플은 여기에 포함되어 있지 않다.
| 컨텍스트 | 기사: |
|---|---|
| 비공식 대화는 모든 비즈니스 관계의 중요한 부분이다. 그러나 토론을 시작하기 전에, 특정 문화에서 어떤 주제가 적합하고 어떤 주제가 금기로 여겨지는지 반드시 이해해야 한다. 라틴아메리카 사람들은 자신들의 지역 역사, 예술, 관습에 대한 정보를 공유하는 것을 즐긴다. 당신은 가족에 대한 질문을 예상할 수 있으며, 자녀들의 사진을 보여 주도록 해야 한다. 당신은 라틴아메리카 친구들에게 비슷한 질문을 자유롭게 할 수 있다. 프랑스인들은 대화를 하나의 예술 형식으로 생각하며, 활기찬 토론뿐 아니라 의견 차이의 가치도 즐긴다. 그들에게 논쟁은 흥미로울 수 있고 거의 또는 어떤 주제든 다룰 수 있다 ---- 그것들이 존중하고 지적인 방식으로 일어나는 한. | |
| 미국에서는 비즈니스 사람들이 일, 가족, 취미, 정치에 대한 의견을 포함하여 폭넓은 주제를 논의하기를 좋아한다. 그러나 일본, 중국, 한국에서는 사람들이 훨씬 더 사적이다. 그들은 자신의 생각, 느낌, 또는 감정을 많이 공유하지 않는데, 그렇게 하는 것이 그들이 구축하려고 하는 조화로운 비즈니스 관계를 해칠 수 있다고 느끼기 때문이다. 중동 사람들 역시 개인 생활과 가족 문제에 대해 사적이다. 예를 들어 사우디아라비아의 사업가에게 그의 아내나 자녀에 대해 묻는 것은 무례한 것으로 여겨진다. | |
| 일반적인 규칙으로, 비즈니스 친구들과 정치나 종교에 대해 이야기하지 않는 것이 가장 좋다. 이는 심지어 사람들이 서로 다른 종교적 견해를 가진 미국에서도 당신을 곤란하게 만들 수 있다. 또한 자신의 급여를 논의하는 것은 보통 부적절한 것으로 여겨진다. 스포츠는 일반적으로 세계 대부분의 지역에서 우호적인 주제이지만, 국가 스포츠를 비판하지 않도록 주의해야 한다. 대신 친절하게 행동하고 당신의 호스트 팀을 칭찬하라. | |
| Q: 다른 나라의 동료들과 스포츠에 대해 이야기할 때 무엇을 해서는 안 되는가? | |
| A: 동료들의 나라의 스포츠를 비판하는 것. | |
| Q: 저자에 따르면 대부분의 장소에서 일반적으로 우호적인 주제는 무엇인가? | |
| A: 스포츠. | |
| Q: 아시아 사람들이 다른 사람들과의 대화에서 더 사적인 이유는 무엇인가? | |
| A: 그들은 비공식 대화로 인해 다른 사람들과의 좋은 관계가 해를 입는 것을 원하지 않는다. | |
| Q: 저자는 정치와 종교를 _ 라고 여긴다. | |
| A: | |
| 정답 | 금기 |
| 오답 | 즐거운 주제들 |
| 오답 | 무례한 주제들 |
| 오답 | 결코 이야기될 수 없는 주제들 |
| 컨텍스트 | anli 2: anli 2: The Gold Coast Hotel&Casino는 네바다주 Paradise에 위치한 호텔 및 카지노이다. 이 지역 주민용 카지노는 Boyd Gaming이 소유하고 운영한다. The Gold Coast는 Las Vegas Strip에서 서쪽으로 1마일 () 떨어진 West Flamingo Road에 위치해 있다. 그것은 Palms Casino Resort와 Rio All Suite Hotel and Casino의 길 건너편에 위치해 있다. |
|---|---|
| 질문: The Gold Coast는 예산 친화적인 카지노이다. True, False, 또는 Neither? | |
| 정답 | Neither |
| 오답 | True |
| 오답 | False |
| 컨텍스트 | 기사: |
|---|---|
| Mrs. Smith는 특이한 교사이다. 한 번 그녀는 각 학생에게 비닐봉지에 감자 몇 개를 가져오라고 말했다. 각 감자 위에 학생들은 자신이 미워하는 사람의 이름을 써야 했다. 그리고 다음 날, 모든 아이가 감자 몇 개를 가져왔다. 어떤 아이는 두 개의 감자를; 어떤 아이는 세 개를; 어떤 아이는 최대 다섯 개까지 가져왔다. | |
| 그런 다음 Mrs. Smith는 아이들에게 2주 동안 화장실에 갈 때조차 어디를 가든 그 봉지들을 들고 다니라고 말했다. 하루하루가 지나면서 아이들은 썩은 감자의 지독한 냄새에 대해 불평하기 시작했다. | |
| 감자 다섯 개를 가져온 아이들은 봉지들의 무게 문제를 느끼기 시작했다. 2주 후, 아이들은 그 게임이 마침내 끝났다는 말을 듣고 기뻐했다. Mrs. Smith가 물었다, "2주 동안 감자들을 들고 다니는 동안 기분이 어땠니?" 아이들은 그 고충에 대해 크게 불평하기 시작했다. | |
| 그런 다음 Mrs. Smith는 왜 그들에게 그 게임을 하라고 했는지 말했다. 그녀는 말했다, "이것은 너희가 누군가에 대한 증오를 마음속에 지니고 다닐 때의 상황과 정확히 같다. 증오의 끔찍한 냄새가 너희 마음을 오염시킬 것이고 너희는 불필요한 것을 항상 지니고 다니게 될 것이다. 단지 2주 동안 썩은 감자의 냄새도 견딜 수 없다면, 평생 동안 마음속에 증오를 품는 것이 얼마나 무거울지 상상할 수 있겠니? 그러니 마음에서 어떤 증오든 버려라, 그러면 너희는 정말 행복해질 것이다." | |
| Q: 다음 중 지문에 따르면 참인 것은 무엇인가? | |
| A: 만약 아이가 네 사람을 미워했다면, 그 또는 그녀는 감자 네 개를 들고 다녀야 했다. | |
| Q: 우리는 지문에서 우리가 _ 해야 한다는 것을 배울 수 있다. | |
| A: 내면의 증오를 버리다 | |
| Q: 아이들은 무게 문제 외에 _ 에 대해 불평했다. | |
| A: 냄새 | |
| Q: Mrs.Smith는 학생들에게 감자 위에 _ 를 쓰라고 했다. | |
| A: | |
| 정답 | 이름들 |
| 오답 | 숫자들 |
| 오답 | 시간 |
| 오답 | 장소들 |
| 컨텍스트 | 나무에 실란트를 바르는 방법. |
|---|---|
| 정답 | 브러시를 사용하여, 나무가 실란트로 완전히 포화될 때까지 나무 위에 실란트를 솔질해 바른다. |
| 오답 | 브러시를 사용하여, 나무가 실란트로 완전히 포화될 때까지 나무 위에 실란트를 떨어뜨린다. |
| 컨텍스트 | 내 몸은 풀밭 위에 그림자를 드리웠는데, 왜냐하면 |
|---|---|
| 정답 | 해가 떠오르고 있었기 때문이다. |
| 오답 | 풀이 깎였기 때문이다. |
| 컨텍스트 | (CNN) 이스라엘 총리로 재임 중 암살된 Yitzhak Rabin의 아들 Yuval Rabin은 한 연설에서 "Second Amendment people"에게 호소한 Donald Trump를 비판했고, 정치인들이 사용하는 말이 폭력을 선동하고 민주주의를 훼손할 수 있다고 경고했다. "Trump의 말은 나를 개인적으로 건드린 유형의 정치적 폭력에 대한 선동이다,"라고 Rabin은 USAToday에 썼다. 그는 Clinton에 대한 폭력의 요구로 비판받았던, Hillary Clinton을 막기 위한 "Second Amendment people"에 대한 Trump의 호소 -- Trump가 부인한 발언들 -- 가 "추악한 선거운동 시즌에서 새로운 수준의 추악함"이었다고 말했다. |
|---|---|
| - 암살된 전 이스라엘 총리의 아들이 폭력적인 정치 수사의 결과에 대한 op ed를 썼다. | |
| - 1990년대의 이스라엘과 오늘날의 U.S. 사이의 "유사점들"을 경고한다. | |
| 정답 | - 1995년 이스라엘의 정치적 긴장 속에서 극단주의자에게 총격을 받아 살해된 자신의 아버지를 언급하며, Rabin은 Donald Trump의 공격적인 수사를 규탄했다. |
| 정답 | - 1995년 이스라엘의 정치적 긴장 속에서 극단주의자에게 총격을 받아 살해된 자신의 아버지를 언급하며, Rabin은 Trump의 공격적인 수사를 규탄했다. |
| 오답 | - 1995년 이스라엘의 정치적 긴장 속에서 극단주의자에게 총격을 받아 살해된 자신의 아버지를 언급하며, Rabin은 Hillary Clinton의 공격적인 수사를 규탄했다. |
| 오답 | - 1995년 이스라엘의 정치적 긴장 속에서 극단주의자에게 총격을 받아 살해된 자신의 아버지를 언급하며, Rabin은 U.S.의 공격적인 수사를 규탄했다. |
| 오답 | - 1995년 이스라엘의 정치적 긴장 속에서 극단주의자에게 총격을 받아 살해된 자신의 아버지를 언급하며, Rabin은 Yitzhak Rabin의 공격적인 수사를 규탄했다. |
| 컨텍스트 | anli 1: anli 1: Fulton James MacGregor MSP는 Coatbridge and Chryston 선거구의 Scottish National Party (SNP) 소속 Scottish Parliament 의원인 스코틀랜드 정치인이다. MacGregor는 현재 Health 장관인 Shona Robison의 Parliamentary Liaison Officer이다&Sport. 그는 또한 Justice and Education에서 일한다&Scottish Parliament의 Skills 위원회들. |
|---|---|
| 질문: Fulton James MacGregor는 Shona Robison의 Liaison officer인 스코틀랜드 정치인이며, 그는 그녀가 자신의 가장 친한 친구라고 맹세한다. True, False, 또는 Neither? | |
| 정답 | Neither |
| 오답 | True |
| 오답 | False |
| 컨텍스트 | 생물은 무엇을 하기 위해 에너지를 필요로 하는가? |
|---|---|
| 정답 | 성숙하고 발달하다. |
| 오답 | 푹 쉬다. |
| 오답 | 빛을 흡수하다. |
| 오답 | 영양분을 섭취하다. |
| 컨텍스트 | 케이크 만들기: 여러 개의 케이크 팝이 진열대 위에 보인다. 한 여성과 소녀가 부엌에서 케이크 팝을 만드는 모습이 보인다. 그들은 |
|---|---|
| 정답 | 그것들을 굽고, 그런 다음 프로스팅하고 장식한다. |
| 오답 | 그것들을 접시에 놓으면서 맛본다. |
| 오답 | 그것을 팬에 넣으면서 케이크 위에 프로스팅을 바른다. |
| 오답 | 나와서 케이크도 장식하기 시작한다. |
| 컨텍스트 | anli 3: anli 3: 우리는 미국 노동자들이 실제로 자기 자신의 일자리 상실을 보조하게 만드는 loophole을 닫았다. 그들은 지난 며칠 사이에 그 loophole의 확장을 통과시켰다: 석유 및 가스 산업과 중국에서 천장 선풍기를 수입하는 사람들에 대한 특혜를 포함한 $43 billion의 무상 제공. |
|---|---|
| 질문: 그 loophole은 이제 사라졌다 True, False, 또는 Neither? | |
| 정답 | 거짓 |
| 오답 | 참 |
| 오답 | 둘 다 아님 |
| 문맥 | 질문: George는 손을 비벼서 손을 빨리 따뜻하게 하고 싶다. 어떤 피부 표면이 가장 많은 열을 낼 것인가? |
|---|---|
| 답: | |
| 정답 | 마른 손바닥 |
| 오답 | 젖은 손바닥 |
| 오답 | 기름으로 덮인 손바닥 |
| 오답 | 로션으로 덮인 손바닥 |
| 문맥 | lull이 trust에 대한 것과 같다면 |
|---|---|
| 정답 | cajole은 compliance에 대한 것이다 |
| 오답 | balk는 fortitude에 대한 것이다 |
| 오답 | betray는 loyalty에 대한 것이다 |
| 오답 | hinder는 destination에 대한 것이다 |
| 오답 | soothe는 passion에 대한 것이다 |
| 올바른 문맥 | Grace는 내 재킷과 그녀의 스웨터를 기꺼이 교환했다. 그녀는 그 스웨터가 |
|---|---|
| 잘못된 문맥 | Grace는 내 재킷과 그녀의 스웨터를 기꺼이 교환했다. 그녀는 그 재킷이 |
| 목표 완성 | 그녀에게 촌스러워 보인다고 생각한다. |
| 올바른 문맥 | Johnny는 그의 새로운 keto diet에서 채소보다 과일을 더 좋아하는데, 왜냐하면 그 과일들은 |
|---|---|
| 잘못된 문맥 | Johnny는 그의 새로운 keto diet에서 채소보다 과일을 더 좋아하는데, 왜냐하면 그 채소들은 |
| 목표 완성 | 달콤하기 때문이다. |
| 문맥 | 독해 답안지 |
|---|---|
| 이 과정이 진행되는 동안, 외교는 계속 그 순환을 이어갔다. Taliban에 대한 직접적인 압박은 성공하지 못한 것으로 드러났다. 한 NSC 직원 메모가 표현했듯이, "Taliban 치하에서 Afghanistan은 테러리즘의 국가 후원자라기보다는 테러리스트들이 후원하는 국가에 가깝다." 2000년 초, United States는 Pakistan을 설득하여 Taliban에 대한 영향력을 행사하게 하려는 고위급 노력을 시작했다. 2000년 1월, Assistant Secretary of State Karl Inderfurth와 State Department의 counterterrorism coordinator인 Michael Sheehan은 Islamabad에서 General Musharraf를 만나, Pakistani 협력에 대한 보상으로 3월 대통령 방문 가능성을 그 앞에 내걸었다. 그러한 방문은 Musharraf가 갈망하던 것이었는데, 부분적으로는 그의 정부의 정당성을 보여주는 표시였기 때문이다. 그는 두 특사에게 자신이 Mullah Omar를 만나 Bin Laden에 대해 압박하겠다고 말했다. 그러나 그들은 떠나면서 Washington에 Pakistan이 실제로는 아무것도 할 가능성이 낮다고 보고했는데, "Afghanistan에 대한 Taliban 통제의 이점이라고 Pakistan이 보는 것" 때문이었다. President Clinton은 India로 여행할 예정이었다. State Department는 그가 Pakistan도 방문하지 않고 India를 방문해서는 안 된다고 생각했다. 그러나 Secret Service와 CIA는 가장 강한 표현으로 Pakistan 방문이 President의 생명을 위험에 빠뜨릴 것이라고 경고했다. Counterterrorism 관계자들도 Pakistan이 대통령 방문을 받을 만할 만큼 충분히 하지 않았다고 주장했다. 그러나 President Clinton은 South Asia 여행 일정에 Pakistan을 포함시킬 것을 고집했다. 2000년 3월 25일 그의 하루 경유는 1969년 이후 U.S. president가 그곳에 간 첫 번째 경우였다. Musharraf 및 다른 사람들과의 회의에서 President Clinton은 Pakistan과 India 사이의 긴장과 핵 확산의 위험에 집중했지만, Bin Laden도 논의했다. President Clinton은 우리에게, 자신이 Musharraf를 따로 불러 짧은 일대일 회의를 했을 때 Bin Laden에 관한 도움을 장군에게 간청했다고 말했다. "내가 그를 보러 갔을 때, 그가 우리가 Bin Laden을 잡고 다른 한두 가지 문제를 처리하는 데 도움을 준다면 United States와의 더 나은 관계라는 측면에서 그에게 달을 따다 주겠다고 제안했다." U.S.의 노력은 계속되었다. | |
| State Department는 누가 India와 Pakistan을 모두 방문해야 한다고 생각했는가? | |
| 정답 | - [거짓] Bin Laden |
| 오답 | - [참] Bin Laden |
| 문맥 | 질문: 어떤 요인이 사람에게 열이 나게 할 가능성이 가장 높은가? |
|---|---|
| 답: | |
| 정답 | 혈류 속의 세균 집단 |
| 오답 | 운동 후 이완되는 다리 근육 |
| 오답 | 피부 위의 여러 바이러스 입자 |
| 오답 | 위에서 소화되고 있는 탄수화물 |
| 문맥 | Bob은 차에 기름을 채우기 위해 주유소에 갔다. 그의 연료 탱크는 완전히 비어 있었고 그의 지갑도 마찬가지였다. 계산원은 그가 나중에 돌아와서 돈을 내면 그의 기름값을 내주겠다고 제안했다. Bob은 집으로 운전해 가면서 고마움을 느꼈다. |
|---|---|
| 정답 | Bob은 세상에 좋은 사람들이 있다고 믿었다. |
| 오답 | Bob은 세상이 얼마나 불친절한지 곰곰이 생각했다. |
| 문맥 | Helsinki는 Finland의 수도이자 가장 큰 도시이다. 그것은 Finland 남부, Gulf of Finland 연안의 Uusimaa 지역에 있다. Helsinki는 인구가 , 도시 인구가 , 그리고 대도시권 인구가 1.4 million명 이상으로, Finland에서 가장 인구가 많은 municipality이자 urban area이다. Helsinki는 Estonia의 Tallinn에서 북쪽으로 어느 정도, Sweden의 Stockholm에서 동쪽으로, Russia의 Saint Petersburg에서 서쪽으로 떨어져 있다. Helsinki는 이 세 도시와 긴밀한 역사적 연결을 가지고 있다. |
|---|---|
| Helsinki metropolitan area에는 Helsinki, Espoo, Vantaa, Kauniainen의 urban core와 주변 commuter towns가 포함된다. 그것은 1 million명이 넘는 세계 최북단 metro area이며, 이 도시는 EU member state의 최북단 수도이다. Helsinki metropolitan area는 Nordic countries에서 Stockholm과 Copenhagen 다음으로 세 번째로 큰 metropolitan area이고, City of Helsinki는 Stockholm과 Oslo 다음으로 세 번째로 크다. Helsinki는 Finland의 주요 정치, 교육, 금융, 문화, 연구 중심지이자 northern Europe의 주요 도시 중 하나이다. Finland에서 운영되는 외국 기업의 약 75%가 Helsinki region에 자리 잡았다. 인근 municipality인 Vantaa는 Helsinki Airport의 위치이며, Europe과 Asia의 다양한 목적지로 빈번한 서비스가 있다. | |
| Q: Finland에서 가장 인구가 많은 municipality는 무엇인가? | |
| A: Helsinki | |
| Q: 그곳에는 얼마나 많은 사람들이 사는가? | |
| A: metropolitan area에 1.4 million명 | |
| Q: Finland에서 운영되는 외국 기업 중 몇 퍼센트가 Helsinki에 있는가? | |
| A: 75% | |
| Q: 어떤 towns가 metropolitan area의 일부인가? | |
| A: | |
| 목표 완성 | Helsinki, Espoo, Vantaa, Kauniainen, 그리고 주변 commuter towns |
| 문맥 | 글자들을 풀어 한 단어로 만들고, 그 단어를 쓰시오: |
|---|---|
| asinoc = | |
| 목표 완성 | casino |
| 문맥 | Passage: Saint Jean de Brébeuf는 1625년에 New France로 여행한 French Jesuit missionary였다. 그곳에서 그는 1629년부터 1633년까지 France에 있었던 몇 년을 제외하고, 남은 생애 동안 주로 Huron과 함께 일했다. 그는 그들의 언어와 문화를 배웠고, 다른 missionaries를 돕기 위해 각각에 대해 광범위하게 글을 썼다. 1649년에 Iroquois raid가 Huron village를 장악했을 때 Brébeuf와 또 다른 missionary가 붙잡혔다. Huron 포로들과 함께, missionaries는 의례적으로 고문당하고 1649년 3월 16일에 살해되었다. Brébeuf는 1925년에 beatified되었고 1930년에 Roman Catholic Church에서 saints로 canonized된 여덟 Jesuit missionaries 중 한 명이었다. |
|---|---|
| 질문: Saint Jean de Brébeuf는 몇 년 동안 New France에 머문 뒤 몇 년간 France로 돌아갔는가? | |
| 답: | |
| 목표 완성 | 4 |
| 문맥 | 빈칸 채우기: |
|---|---|
| 그녀는 횃불을 자기 앞에 들었다. | |
| 그녀는 숨을 삼켰다. | |
| "Chris? 계단이 있어." | |
| "뭐?" | |
| "계단. 바위에 파여 있어. 약 50 feet 앞에." 그녀는 더 빨리 움직였다. 둘 다 더 빨리 움직였다. "사실," 그녀가 횃불을 더 높이 들며 말했다, "____ 하나보다 더 많아. - | |
| 목표 완성 | 계단 |
| 문맥 | 글자들을 풀어 한 단어로 만들고, 그 단어를 쓰시오: |
|---|---|
| skicts = | |
| 목표 완성 | sticks |
| 문맥 | 글자들을 풀어 한 단어로 만들고, 그 단어를 쓰시오: |
|---|---|
| volwskagen = | |
| 목표 완성 | volkswagen |
| 문맥 | Q: touched by an angel에서 tess를 연기한 사람은 누구인가? |
|---|---|
| A: | |
| 목표 완성 | Delloreese Patricia Early (July 6, 1931 – November 19, 2017), professionally Della Reese로 알려짐 |
| 문맥 | TITLE: William Perry (American football) - Professional career |
|---|---|
| PARAGRAPH: 1985년에 그는 Chicago Bears에 의해 1985 NFL Draft의 first round에서 선발되었으며, coach Mike Ditka가 직접 골랐다. 그러나 Ditka와 매우 험악한 관계였던 defensive coordinator Buddy Ryan은 Perry를 "wasted draft-pick"이라고 불렀다. Perry는 곧 Ditka와 Ryan 사이의 정치적 권력 투쟁에서 볼모가 되었다. Perry의 "Refrigerator" 별명은 NFL까지 그를 따라갔고 그는 빠르게 Chicago Bears 팬들의 favorite가 되었다. 팀 동료들은 그를 "Biscuit"이라고 불렀는데, "350 pounds에 biscuit 하나 모자란"이라는 뜻이었다. Ryan이 Perry를 뛰게 하기를 거부한 반면, Ditka는 팀이 상대의 goal line 근처에 있거나 fourth and short 상황일 때 Perry를 fullback으로 사용하기로 결정했는데, ball carrier 또는 star running back Walter Payton을 위한 lead blocker로서였다. Ditka는 Perry를 fullback으로 사용하게 된 영감이 five-yard sprint exercises 중에 떠올랐다고 말했다. 그의 rookie season 동안 Perry는 two touchdowns를 향해 돌진했고 one touchdown을 위한 pass를 잡았다. Perry는 심지어 Super Bowl XX 동안 공을 달릴 기회도 얻었는데, 이는 그의 인기와 팀 성공에 대한 기여에 대한 표시였다. 처음 공을 받았을 때, 그는 halfback option play에서 자신의 첫 NFL pass를 던지려다 one-yard loss로 tackle당했다. 두 번째로 공을 받았을 때 그는 touchdown을 득점했다(그 과정에서 Patriots linebacker Larry McGrew를 밀고 지나갔다). rookie season의 중반쯤, Ryan은 마침내 Perry를 뛰게 하기 시작했고, 그는 곧 자신이 유능한 defensive lineman임을 증명했다. 그의 Super Bowl ring size는 이 이벤트 역사상 어떤 professional football player보다도 가장 크다. 그의 ring size는 25인 반면, 평균 성인 남성의 ring size는 10에서 12 사이이다. Perry는 이후 NFL에서 10년 동안 뛰었고, 1994 season 이후 은퇴했다. pro로서의 10년 동안 그는 정기적으로 체중 문제로 고전했으며, 이는 때때로 그의 경기력을 방해했다. 그는 138 games에 출전하여 29.5 sacks와 five fumble recoveries를 기록했고, 그것들을 총 71 yards 동안 return했다. 그의 offensive career에서 그는 two touchdowns를 위해 five yards를 달렸고, another touchdown을 위한 one reception을 기록했다. Perry는 나중에 comeback을 시도하여 World League of American Football(나중의 NFL Europa)의 London Monarchs에서 눈에 띄지 않는 1996 season을 뛰었다. | |
| Q: 그는 어떤 team에서 뛰었는가? | |
| A: | |
| 목표 완성 | Chicago Bears |
| 문맥 | 글자들을 풀어 한 단어로 만들고, 그 단어를 쓰시오: |
|---|---|
| r e!c.i p r o.c a/l = | |
| 목표 완성 | reciprocal |
| 문맥 | 글자들을 풀어 한 단어로 만들고, 그 단어를 쓰시오: |
|---|---|
| taefed = | |
| 목표 완성 | defeat |
| 문맥 | Title: The_Blitz |
|---|---|
| Background: German의 관점에서, 1941년 3월에는 개선이 있었다. Luftwaffe는 그 달에 4,000 sorties를 비행했으며, 여기에는 12 major 및 three heavy attacks가 포함되었다. 전자전은 격화되었지만 Luftwaffe는 달빛이 있는 밤에만 주요 inland missions를 비행했다. Ports는 찾기가 더 쉬웠고 더 나은 targets가 되었다. British를 혼란스럽게 하기 위해, 폭탄이 떨어질 때까지 radio silence가 지켜졌다. X- 및 Y-Gerät beams는 false targets 위에 배치되었고 마지막 순간에만 전환되었다. X-Gerät에는 빠른 frequency changes가 도입되었고, 그것의 더 넓은 frequencies 대역과 더 큰 tactical flexibility는 British selective jamming이 Y-Gerät의 effectiveness를 저하시키고 있던 시기에 그것이 여전히 효과적이도록 보장했다. | |
| Q: 1941년 3월에 몇 sorties가 비행되었는가? | |
| A: 4,000 | |
| Q: Luftwaffe는 언제 inland missions를 비행했는가? | |
| A: | |
| 목표 완성 | 달빛이 있는 밤에만 |
| 문맥 | Normal force -- 물체가 탁자 위에 놓여 있는 것과 같은 단순한 경우, 물체에 작용하는 normal force는 물체에 가해지는 gravitational force(또는 물체의 weight)와 크기는 같지만 반대 방향이며, 즉 N = m g (\displaystyle N=mg)이다. 여기서 m은 mass이고, g는 gravitational field strength(Earth에서 약 9.81 m/s)이다. 여기서 normal force는 물체가 탁자를 뚫고 가라앉는 것을 막는, 탁자가 물체에 대해 가하는 힘을 나타내며, 탁자가 부서지지 않고 이 normal force를 전달할 만큼 충분히 튼튼해야 함을 요구한다. 그러나 normal force와 weight가 action-reaction force pairs라고 가정하기 쉽다(흔한 실수). 이 경우, normal force와 weight는 물체의 upward acceleration이 없는 이유를 설명하기 위해 magnitude가 같아야 한다. 예를 들어, 위로 튀어 오르는 공은 공에 작용하는 normal force가 공의 weight보다 magnitude가 더 크기 때문에 위로 가속된다. |
|---|---|
| 질문: normal force는 gravity의 힘과 같은가? | |
| 답: | |
| 목표 완성 | 예 |
| 문맥 | 더 낮은 rents를 향한 추세는 New York의 일부 communities가 높은 rents 때문에 좋아하던 local businesses를 잃는 것을 한탄하고 있다는 점을 고려하면 놀랍게 보일 수 있다. 그러나 최근의 완화에도 불구하고, 이러한 retailers 중 많은 이들에게는 그들의 leases가 signed되었던 late 1970s의 rental rates로부터 여전히 너무 큰 jump가 있었다. 확실히, 최근의 가격 하락이 Manhattan이 싸다는 의미는 아니다. |
|---|---|
| 질문: Manhattan은 싸다. 참, 거짓, 또는 둘 다 아님? | |
| 답: | |
| 목표 완성 | 거짓 |
| 문맥 | 그에게 네 명을 위한 저녁 식사를 안겨 준 그 내기는 1995년에 발견된 elementary particle인 top quark의 존재와 질량에 관한 것이었다. |
|---|---|
| 질문: Top Quark는 particle physics의 standard model theory가 예측한 quarks의 여섯 flavors 중 마지막이다. True 또는 False? | |
| 답: | |
| 목표 완성 | 거짓 |
| 문맥 | 한 outfitter가 safari에 필요한 모든 것을 제공했다. |
|---|---|
| 그의 첫 walking holiday 전에, 그는 boots를 사기 위해 전문 outfitter에게 갔다. | |
| 질문: 위의 두 문장에서 ‘outfitter’라는 단어가 같은 방식으로 사용되었는가? | |
| 답: | |
| 목표 완성 | 아니오 |
| 문맥 | 정답표가 있는 기말시험 |
|---|---|
| 지시문: 다음 지문들을 주의 깊게 읽으십시오. 각 지문에 대해, *굵게* 표시된 대명사가 어떤 명사를 가리키는지 식별해야 합니다. | |
| ===== | |
| 지문: Mr. Moncrieff는 그것이 그의 아들 Edward의 것이라고 생각하며 Chester의 호화로운 New York 아파트를 방문했다. 그 결과 Mr. Moncrieff는 그가 더 이상 *his* 재정적 지원을 필요로 하지 않는다는 이유로 Edward의 용돈을 취소하기로 결정했다. | |
| 질문: 위 지문에서 대명사 "*his*"는 무엇을 가리키는가? | |
| 답: | |
| 목표 완성 | mr. moncrieff |
| 문맥 | Q: ‘Nude Descending A Staircase’는 아마도 어느 20세기 예술가의 가장 유명한 그림인가? |
|---|---|
| A: | |
| 목표 완성 | MARCEL DUCHAMP |
| 목표 완성 | r mutt |
| 목표 완성 | duchamp |
| 목표 완성 | marcel duchamp |
| 목표 완성 | R.Mutt |
| 목표 완성 | Marcel duChamp |
| 목표 완성 | Henri-Robert-Marcel Duchamp |
| 목표 완성 | Marcel du Champ |
| 목표 완성 | henri robert marcel duchamp |
| 목표 완성 | Duchampian |
| 목표 완성 | Duchamp |
| 목표 완성 | duchampian |
| 목표 완성 | marcel du champ |
| 목표 완성 | Marcel Duchamp |
| 목표 완성 | MARCEL DUCHAMP |
| 문맥 | Q: burne hogarth는 어떤 학교를 설립했는가? |
|---|---|
| A: | |
| 목표 완성 | School of Visual Arts |
| 문맥 | 어떤 경우에도 이것들은 상업적 용도로 사용되어서는 안 된다. = |
|---|---|
| 목표 완성 | 어떤 경우에도 그것들은 상업적 목적으로 사용되어서는 안 된다. |
| 문맥 | 어떤 경우에도 그것들은 상업적 목적으로 사용되어서는 안 된다. = |
|---|---|
| 목표 완성 | 어떤 경우에도 이것들은 상업적 용도로 사용되어서는 안 된다. |
| 문맥 | 일련의 연못에서 수집된 유충 I. verticalis의 령 분포 분석은 또한 수컷이 암컷보다 더 발달한 령 단계에 있음을 나타냈다. = |
|---|---|
| 목표 완성 | 일련의 연못에서 I. verticalis의 유충 단계 빈도 분포 분석은 또한 수컷 유충이 암컷 유충보다 더 발달한 단계에 있음을 입증했다. |
| 문맥 | 일련의 연못에서 I. verticalis의 유충 단계 빈도 분포 분석은 또한 수컷 유충이 암컷 유충보다 더 발달한 단계에 있음을 입증했다. = |
|---|---|
| 목표 완성 | 일련의 연못에서 수집된 유충 I. verticalis의 령 분포 분석은 또한 수컷이 암컷보다 더 발달한 령 단계에 있음을 나타냈다. |
| 문맥 | 진실은 당신들이 어떤 대가를 치르더라도, 그리고 유럽 국민들의 바람에 반하여, Turkey가 Cyprus를 인정하기를 계속 거부하고 민주적 개혁이 정체되어 있음에도 불구하고 Turkey의 European Union 가입 협상을 계속하기를 원한다는 것이다. = |
|---|---|
| 목표 완성 | 진실은 당신들이 어떤 대가를 치르더라도, 그리고 유럽인들의 바람에 반하여, Turkey의 European Union 가입 협상을 계속하기를 원한다는 것이며, Turkey가 Cyprus를 인정하기를 계속 거부하고 민주적 개혁이 막다른 지점에 도달했음에도 그렇다는 것이다. |
| 문맥 | 진실은 당신들이 어떤 대가를 치르더라도, 그리고 유럽인들의 바람에 반하여, Turkey의 European Union 가입 협상을 계속하기를 원한다는 것이며, Turkey가 Cyprus를 인정하기를 계속 거부하고 민주적 개혁이 막다른 지점에 도달했음에도 그렇다는 것이다. = |
|---|---|
| 목표 완성 | 진실은 당신들이 어떤 대가를 치르더라도, 그리고 유럽 국민들의 바람에 반하여, Turkey가 Cyprus를 인정하기를 계속 거부하고 민주적 개혁이 정체되어 있음에도 불구하고 Turkey의 European Union 가입 협상을 계속하기를 원한다는 것이다. |
| 문맥 | Q: (2 * 4) * 6은 무엇인가? |
|---|---|
| A: | |
| 목표 완성 | 48 |
| 문맥 | Q: 17 minus 14는 무엇인가? |
|---|---|
| A: | |
| 목표 완성 | 3 |
| 문맥 | Q: 98 plus 45는 무엇인가? |
|---|---|
| A: | |
| 목표 완성 | 143 |
| 문맥 | Q: 95 times 45는 무엇인가? |
|---|---|
| A: | |
| 목표 완성 | 4275 |
| 문맥 | Q: 509 minus 488은 무엇인가? |
|---|---|
| A: | |
| 목표 완성 | 21 |
| 문맥 | Q: 556 plus 497은 무엇인가? |
|---|---|
| A: | |
| 목표 완성 | 1053 |
| 문맥 | Q: 6209 minus 3365는 무엇인가? |
|---|---|
| A: | |
| 목표 완성 | 2844 |
| 문맥 | Q: 9923 plus 617은 무엇인가? |
|---|---|
| A: | |
| 목표 완성 | 10540 |
| 문맥 | Q: 40649 minus 78746은 무엇인가? |
|---|---|
| A: | |
| 목표 완성 | -38097 |
| 문맥 | Q: 65360 plus 16204는 무엇인가? |
|---|---|
| A: | |
| 목표 완성 | 81564 |
Appendix H모든 모델 크기에 대한 모든 과제의 결과
| Zero-Shot | One-Shot | Few-Shot | |||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 이름 | Metric | Split | Fine-tune SOTA | K | 소형 | 중형 | 대형 | XL | 2.7B | 6.7B | 13B | 175B | 소형 | 중형 | 대형 | XL | 2.7B | 6.7B | 13B | 175B | 소형 | 중형 | 대형 | XL | 2.7B | 6.7B | 13B | 175B | 175B (test server) |
| HellaSwag | acc | dev | 85.6 | 20 | 33.7 | 43.6 | 51.0 | 54.7 | 62.8 | 67.4 | 70.9 | 78.9 | 33.0 | 42.9 | 50.5 | 53.5 | 61.9 | 66.5 | 70.0 | 78.1 | 33.5 | 43.1 | 51.3 | 54.9 | 62.9 | 67.3 | 71.3 | 79.3 | |
| LAMBADA | acc | test | 68.0 | 15 | 42.7 | 54.3 | 60.4 | 63.6 | 67.1 | 70.3 | 72.5 | 76.2 | 22.0 | 47.1 | 52.6 | 58.3 | 61.1 | 65.4 | 69.0 | 72.5 | 22.0 | 40.4 | 63.2 | 57.0 | 78.1 | 79.1 | 81.3 | 86.4 | |
| LAMBADA | ppl | test | 8.63 | 15 | 18.6 | 9.09 | 6.53 | 5.44 | 4.60 | 4.00 | 3.56 | 3.00 | 165.0 | 11.6 | 8.29 | 6.46 | 5.53 | 4.61 | 4.06 | 3.35 | 165.0 | 27.6 | 6.63 | 7.45 | 2.89 | 2.56 | 2.56 | 1.92 | |
| StoryCloze | acc | test | 91.8 | 70 | 63.3 | 68.5 | 72.4 | 73.4 | 77.2 | 77.7 | 79.5 | 83.2 | 62.3 | 68.7 | 72.3 | 74.2 | 77.3 | 78.7 | 79.7 | 84.7 | 62.3 | 70.2 | 73.9 | 76.1 | 80.2 | 81.2 | 83.0 | 87.7 | |
| NQs | acc | test | 44.5 | 64 | 0.64 | 1.75 | 2.71 | 4.40 | 6.01 | 5.79 | 7.84 | 14.6 | 1.19 | 3.07 | 4.79 | 5.43 | 8.73 | 9.78 | 13.7 | 23.0 | 1.72 | 4.46 | 7.89 | 9.72 | 13.2 | 17.0 | 21.0 | 29.9 | |
| TriviaQA | acc | dev | 68.0 | 64 | 4.15 | 7.61 | 14.0 | 19.7 | 31.3 | 38.7 | 41.8 | 64.3 | 4.19 | 12.9 | 20.5 | 26.5 | 35.9 | 44.4 | 51.3 | 68.0 | 6.96 | 16.3 | 26.5 | 32.1 | 42.3 | 51.6 | 57.5 | 71.2 | 71.2 |
| WebQs | acc | test | 45.5 | 64 | 1.77 | 3.20 | 4.33 | 4.63 | 7.92 | 7.73 | 8.22 | 14.4 | 2.56 | 6.20 | 8.51 | 9.15 | 14.5 | 15.1 | 19.0 | 25.3 | 5.46 | 12.6 | 15.9 | 19.6 | 24.8 | 27.7 | 33.5 | 41.5 | |
| RoEn 16 | BLEU-mb | test | 39.9 | 64 | 2.08 | 2.71 | 3.09 | 3.15 | 16.3 | 8.34 | 20.2 | 19.9 | 0.55 | 15.4 | 23.0 | 26.3 | 30.6 | 33.2 | 35.6 | 38.6 | 1.25 | 20.7 | 25.8 | 29.2 | 33.1 | 34.8 | 37.0 | 39.5 | |
| RoEn 16 | BLEU-sb | test | 64 | 2.39 | 3.08 | 3.49 | 3.56 | 16.8 | 8.75 | 20.8 | 20.9 | 0.65 | 15.9 | 23.6 | 26.8 | 31.3 | 34.2 | 36.7 | 40.0 | 1.40 | 21.3 | 26.6 | 30.1 | 34.3 | 36.2 | 38.4 | 41.3 | ||
| EnRo 16 | BLEU-mb | test | 38.5 | 64 | 2.14 | 2.65 | 2.53 | 2.50 | 3.46 | 4.24 | 5.32 | 14.1 | 0.35 | 3.30 | 7.89 | 8.72 | 13.2 | 15.1 | 17.3 | 20.6 | 1.25 | 5.90 | 9.33 | 10.7 | 14.3 | 16.3 | 18.0 | 21.0 | |
| EnRo 16 | BLEU-sb | test | 64 | 2.61 | 3.11 | 3.07 | 3.09 | 4.26 | 5.31 | 6.43 | 18.0 | 0.55 | 3.90 | 9.15 | 10.3 | 15.7 | 18.2 | 20.8 | 24.9 | 1.64 | 7.40 | 10.9 | 12.9 | 17.2 | 19.6 | 21.8 | 25.8 | ||
| FrEn 14 | BLEU-mb | test | 35.0 | 64 | 1.81 | 2.53 | 3.47 | 3.13 | 20.6 | 15.1 | 21.8 | 21.2 | 1.28 | 15.9 | 23.7 | 26.3 | 29.0 | 30.5 | 30.2 | 33.7 | 4.98 | 25.5 | 28.5 | 31.1 | 33.7 | 34.9 | 36.6 | 39.2 | |
| FrEn 14 | BLEU-sb | test | 64 | 2.29 | 2.99 | 3.90 | 3.60 | 21.2 | 15.5 | 22.4 | 21.9 | 1.50 | 16.3 | 24.4 | 27.0 | 30.0 | 31.6 | 31.4 | 35.6 | 5.30 | 26.2 | 29.5 | 32.2 | 35.1 | 36.4 | 38.3 | 41.4 | ||
| EnFr 14 | BLEU-mb | test | 45.6 | 64 | 1.74 | 2.16 | 2.73 | 2.15 | 15.1 | 8.82 | 12.0 | 25.2 | 0.49 | 8.00 | 14.8 | 15.9 | 20.3 | 23.3 | 24.9 | 28.3 | 4.08 | 14.5 | 19.3 | 21.5 | 24.9 | 27.3 | 29.5 | 32.6 | |
| EnFr 14 | BLEU-sb | test | 45.9 | 64 | 2.44 | 2.75 | 3.54 | 2.82 | 19.3 | 11.4 | 15.3 | 31.3 | 0.81 | 10.0 | 18.2 | 19.3 | 24.7 | 28.3 | 30.1 | 34.1 | 5.31 | 18.0 | 23.6 | 26.1 | 30.3 | 33.3 | 35.5 | 39.9 | |
| DeEn 16 | BLEU-mb | test | 40.2 | 64 | 2.06 | 2.87 | 3.41 | 3.63 | 21.5 | 17.3 | 23.0 | 27.2 | 0.83 | 16.2 | 22.5 | 24.7 | 28.2 | 30.7 | 33.0 | 30.4 | 3.25 | 22.7 | 26.2 | 29.2 | 32.7 | 34.8 | 37.3 | 40.6 | |
| DeEn 16 | BLEU-sb | test | 64 | 2.39 | 3.27 | 3.85 | 4.04 | 22.5 | 18.2 | 24.4 | 28.6 | 0.93 | 17.1 | 23.4 | 25.8 | 29.2 | 31.9 | 34.5 | 32.1 | 3.60 | 23.8 | 27.5 | 30.5 | 34.1 | 36.5 | 39.1 | 43.0 | ||
| EnDe 16 | BLEU-mb | test | 41.2 | 64 | 1.70 | 2.27 | 2.31 | 2.43 | 12.9 | 8.66 | 10.4 | 24.6 | 0.50 | 7.00 | 12.9 | 13.1 | 18.3 | 20.9 | 22.5 | 26.2 | 3.42 | 12.3 | 15.4 | 17.1 | 20.9 | 23.0 | 26.6 | 29.7 | |
| EnDe 16 | BLEU-sb | test | 41.2 | 64 | 2.09 | 2.65 | 2.75 | 2.92 | 13.7 | 9.36 | 11.0 | 25.3 | 0.54 | 7.40 | 13.4 | 13.4 | 18.8 | 21.7 | 23.3 | 27.3 | 3.78 | 12.9 | 16.1 | 17.7 | 21.7 | 24.1 | 27.7 | 30.9 | |
| Winograd | acc | test | 93.8 | 7 | 66.3 | 72.9 | 74.7 | 76.9 | 82.4 | 85.7 | 87.9 | 88.3 | 63.4 | 68.5 | 72.9 | 76.9 | 82.4 | 84.6 | 86.1 | 89.7 | 63.4 | 67.4 | 73.6 | 76.9 | 84.3 | 85.4 | 82.4 | 88.6 | |
| Winogrande | acc | dev | 84.6 | 50 | 52.0 | 52.1 | 57.4 | 58.7 | 62.3 | 64.5 | 67.9 | 70.2 | 51.3 | 53.0 | 58.3 | 59.1 | 61.7 | 65.8 | 66.9 | 73.2 | 51.3 | 52.6 | 57.5 | 59.1 | 62.6 | 67.4 | 70.0 | 77.7 | |
| PIQA | acc | dev | 77.1 | 50 | 64.6 | 70.2 | 72.9 | 75.1 | 75.6 | 78.0 | 78.5 | 81.0 | 64.3 | 69.3 | 71.8 | 74.4 | 74.3 | 76.3 | 77.8 | 80.5 | 64.3 | 69.4 | 72.0 | 74.3 | 75.4 | 77.8 | 79.9 | 82.3 | 82.8 |
| ARC (Challenge) | acc | test | 78.5 | 50 | 26.6 | 29.5 | 31.8 | 35.5 | 38.0 | 41.4 | 43.7 | 51.4 | 25.5 | 30.2 | 31.6 | 36.4 | 38.4 | 41.5 | 43.1 | 53.2 | 25.5 | 28.4 | 32.3 | 36.7 | 39.5 | 43.7 | 44.8 | 51.5 | |
| ARC (Easy) | acc | test | 92.0 | 50 | 43.6 | 46.5 | 53.0 | 53.8 | 58.2 | 60.2 | 63.8 | 68.8 | 42.7 | 48.2 | 54.6 | 55.9 | 60.3 | 62.6 | 66.8 | 71.2 | 42.7 | 51.0 | 58.1 | 59.1 | 62.1 | 65.8 | 69.1 | 70.1 | |
| OpenBookQA | acc | test | 87.2 | 100 | 35.6 | 43.2 | 45.2 | 46.8 | 53.0 | 50.4 | 55.6 | 57.6 | 37.0 | 39.8 | 46.2 | 46.4 | 53.4 | 53.0 | 55.8 | 58.8 | 37.0 | 43.6 | 48.0 | 50.6 | 55.6 | 55.2 | 60.8 | 65.4 | |
| Quac | f1 | dev | 74.4 | 5 | 21.2 | 26.8 | 31.0 | 30.1 | 34.7 | 36.1 | 38.4 | 41.5 | 21.1 | 26.9 | 31.9 | 32.3 | 37.4 | 39.0 | 40.6 | 43.4 | 21.6 | 27.6 | 32.9 | 34.2 | 38.2 | 39.9 | 40.9 | 44.3 | |
| RACE-h | acc | test | 90.0 | 10 | 35.2 | 37.9 | 40.1 | 40.9 | 42.4 | 44.1 | 44.6 | 45.5 | 34.3 | 37.7 | 40.0 | 42.0 | 43.8 | 44.3 | 44.6 | 45.9 | 34.3 | 37.0 | 40.4 | 41.4 | 42.3 | 44.7 | 45.1 | 46.8 | |
| RACE-m | acc | test | 93.1 | 10 | 42.1 | 47.2 | 52.1 | 52.3 | 54.7 | 54.4 | 56.7 | 58.4 | 42.3 | 47.3 | 51.7 | 55.2 | 56.1 | 54.7 | 56.9 | 57.4 | 42.3 | 47.0 | 52.7 | 53.0 | 55.6 | 55.4 | 58.1 | 58.1 | |
| SQuADv2 | em | dev | 90.7 | 16 | 22.6 | 32.8 | 33.9 | 43.1 | 43.6 | 45.4 | 49.0 | 52.6 | 25.1 | 37.5 | 37.9 | 47.9 | 47.9 | 51.1 | 56.0 | 60.1 | 27.5 | 40.5 | 39.2 | 53.5 | 50.0 | 56.6 | 62.6 | 64.9 | |
| SQuADv2 | f1 | dev | 93.0 | 16 | 28.3 | 40.2 | 41.4 | 50.3 | 51.0 | 52.7 | 56.3 | 59.5 | 30.1 | 43.6 | 44.1 | 54.0 | 54.1 | 57.1 | 61.8 | 65.4 | 32.1 | 45.5 | 44.9 | 58.7 | 55.9 | 62.1 | 67.7 | 69.8 | |
| CoQA | f1 | dev | 90.7 | 5 | 34.5 | 55.0 | 61.8 | 65.3 | 71.1 | 72.8 | 76.3 | 81.5 | 30.6 | 52.1 | 61.6 | 66.1 | 71.8 | 75.1 | 77.9 | 84.0 | 31.1 | 52.0 | 62.7 | 66.8 | 73.2 | 77.3 | 79.9 | 85.0 | |
| DROP | f1 | dev | 89.1 | 20 | 9.40 | 13.6 | 14.4 | 16.4 | 19.7 | 17.0 | 24.0 | 23.6 | 11.7 | 18.1 | 20.9 | 23.0 | 26.4 | 27.3 | 29.2 | 34.3 | 12.9 | 18.7 | 24.0 | 25.6 | 29.7 | 29.7 | 32.3 | 36.5 | |
| BoolQ | acc | dev | 91.0 | 32 | 49.7 | 60.3 | 58.9 | 62.4 | 67.1 | 65.4 | 66.2 | 60.5 | 52.6 | 61.7 | 60.4 | 63.7 | 68.4 | 68.7 | 69.0 | 76.7 | 43.1 | 60.6 | 62.0 | 64.1 | 70.3 | 70.0 | 70.2 | 77.5 | 76.4 |
| CB | acc | dev | 96.9 | 32 | 0.00 | 32.1 | 8.93 | 19.6 | 19.6 | 28.6 | 19.6 | 46.4 | 55.4 | 53.6 | 53.6 | 48.2 | 57.1 | 33.9 | 55.4 | 64.3 | 42.9 | 58.9 | 53.6 | 69.6 | 67.9 | 60.7 | 66.1 | 82.1 | 75.6 |
| CB | f1 | dev | 93.9 | 32 | 0.00 | 29.3 | 11.4 | 17.4 | 22.4 | 25.1 | 20.3 | 42.8 | 60.1 | 39.8 | 45.6 | 37.5 | 45.7 | 28.5 | 44.6 | 52.5 | 26.1 | 40.4 | 32.6 | 48.3 | 45.7 | 44.6 | 46.0 | 57.2 | 52.0 |
| Copa | acc | dev | 94.8 | 32 | 66.0 | 68.0 | 73.0 | 77.0 | 76.0 | 80.0 | 84.0 | 91.0 | 62.0 | 64.0 | 66.0 | 74.0 | 76.0 | 82.0 | 86.0 | 87.0 | 67.0 | 64.0 | 72.0 | 77.0 | 83.0 | 83.0 | 86.0 | 92.0 | 92.0 |
| RTE | acc | dev | 92.5 | 32 | 47.7 | 49.8 | 48.4 | 56.0 | 46.6 | 55.2 | 62.8 | 63.5 | 53.1 | 47.3 | 49.5 | 49.5 | 54.9 | 54.9 | 56.3 | 70.4 | 52.3 | 48.4 | 46.9 | 50.9 | 56.3 | 49.5 | 60.6 | 72.9 | 69.0 |
| WiC | acc | dev | 76.1 | 32 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 50.0 | 50.3 | 50.3 | 49.2 | 49.4 | 50.3 | 50.0 | 48.6 | 49.8 | 55.0 | 53.0 | 53.0 | 51.6 | 53.1 | 51.1 | 55.3 | 49.4 |
| WSC | acc | dev | 93.8 | 32 | 59.6 | 56.7 | 65.4 | 61.5 | 66.3 | 60.6 | 64.4 | 65.4 | 58.7 | 58.7 | 60.6 | 62.5 | 66.3 | 60.6 | 66.3 | 69.2 | 58.7 | 60.6 | 54.8 | 49.0 | 62.5 | 67.3 | 75.0 | 75.0 | 80.1 |
| MultiRC | acc | dev | 62.3 | 32 | 4.72 | 9.65 | 12.3 | 13.6 | 14.3 | 18.4 | 24.2 | 27.6 | 4.72 | 9.65 | 12.3 | 13.6 | 14.3 | 18.4 | 24.2 | 27.6 | 6.09 | 11.8 | 16.8 | 20.8 | 24.7 | 23.8 | 25.0 | 32.5 | 30.5 |
| MultiRC | f1a | dev | 88.2 | 32 | 57.0 | 59.7 | 60.4 | 59.9 | 60.0 | 64.5 | 71.4 | 72.9 | 57.0 | 59.7 | 60.4 | 59.9 | 60.0 | 64.5 | 71.4 | 72.9 | 45.0 | 55.9 | 64.2 | 65.4 | 69.5 | 66.4 | 69.3 | 74.8 | 75.4 |
| ReCoRD | acc | dev | 92.5 | 32 | 70.8 | 78.5 | 82.1 | 84.1 | 86.2 | 88.6 | 89.0 | 90.2 | 69.8 | 77.0 | 80.7 | 83.0 | 85.9 | 88.0 | 88.8 | 90.2 | 69.8 | 77.2 | 81.3 | 83.1 | 86.6 | 87.9 | 88.9 | 89.0 | 90.2 |
| ReCoRD | f1 | dev | 93.3 | 32 | 71.9 | 79.2 | 82.8 | 85.2 | 87.3 | 89.5 | 90.4 | 91.0 | 70.7 | 77.8 | 81.6 | 83.9 | 86.8 | 88.8 | 89.7 | 91.2 | 70.7 | 77.9 | 82.1 | 84.0 | 87.5 | 88.8 | 89.8 | 90.1 | 91.1 |
| SuperGLUE | 평균 | dev | 89.0 | 40.6 | 47.4 | 46.8 | 49.6 | 50.1 | 52.3 | 54.4 | 58.2 | 54.4 | 55.1 | 56.7 | 57.8 | 61.2 | 59.7 | 64.3 | 68.9 | 50.2 | 56.2 | 56.8 | 60.0 | 64.3 | 63.6 | 66.9 | 73.2 | 71.8 | |
| ANLI R1 | acc | test | 73.8 | 50 | 33.4 | 34.2 | 33.4 | 33.4 | 34.2 | 32.3 | 33.2 | 34.6 | 32.1 | 31.6 | 31.9 | 34.6 | 30.6 | 31.6 | 32.7 | 32.0 | 32.1 | 32.5 | 30.9 | 32.5 | 33.5 | 33.1 | 33.3 | 36.8 | |
| ANLI R2 | acc | test | 50.7 | 50 | 33.2 | 31.9 | 33.3 | 33.3 | 33.8 | 33.5 | 33.5 | 35.4 | 35.7 | 33.7 | 33.2 | 32.7 | 32.7 | 33.9 | 33.9 | 33.9 | 35.7 | 33.8 | 32.1 | 31.4 | 32.6 | 33.3 | 32.6 | 34.0 | |
| ANLI R3 | acc | test | 48.3 | 50 | 33.6 | 34.0 | 33.8 | 33.4 | 35.3 | 34.8 | 34.4 | 34.5 | 35.0 | 32.6 | 33.0 | 33.9 | 34.1 | 33.1 | 32.5 | 35.1 | 35.0 | 34.4 | 35.1 | 36.0 | 32.7 | 33.9 | 34.5 | 40.2 | |
| 2D+ | acc | n/a | 50 | 0.70 | 0.65 | 0.70 | 0.85 | 1.10 | 2.54 | 15.4 | 76.9 | 2.00 | 0.55 | 3.15 | 4.00 | 12.1 | 19.6 | 73.0 | 99.6 | 2.00 | 4.10 | 3.50 | 4.50 | 8.90 | 11.9 | 55.5 | 100.0 | ||
| 2D- | acc | n/a | 50 | 1.25 | 1.25 | 1.25 | 1.25 | 1.60 | 7.60 | 12.6 | 58.0 | 1.15 | 0.95 | 1.45 | 1.95 | 3.85 | 11.5 | 44.6 | 86.4 | 1.15 | 1.45 | 2.25 | 2.70 | 7.35 | 13.6 | 52.4 | 98.9 | ||
| 3D+ | acc | n/a | 50 | 0.10 | 0.10 | 0.05 | 0.10 | 0.10 | 0.25 | 1.40 | 34.2 | 0.15 | 0.00 | 0.10 | 0.30 | 0.45 | 0.95 | 15.4 | 65.5 | 0.15 | 0.45 | 0.30 | 0.55 | 0.75 | 0.90 | 8.40 | 80.4 | ||
| 3D- | acc | n/a | 50 | 0.05 | 0.05 | 0.05 | 0.05 | 0.05 | 0.45 | 1.35 | 48.3 | 0.05 | 0.15 | 0.25 | 0.30 | 0.55 | 1.60 | 6.15 | 78.7 | 0.05 | 0.10 | 0.15 | 0.35 | 0.65 | 1.05 | 9.20 | 94.2 | ||
| 4D+ | acc | n/a | 50 | 0.05 | 0.05 | 0.00 | 0.00 | 0.05 | 0.05 | 0.15 | 4.00 | 0.00 | 0.00 | 0.10 | 0.00 | 0.00 | 0.10 | 0.80 | 14.0 | 0.00 | 0.05 | 0.05 | 0.00 | 0.15 | 0.15 | 0.40 | 25.5 | ||
| 4D- | acc | n/a | 50 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.10 | 7.50 | 0.00 | 0.00 | 0.00 | 0.00 | 0.05 | 0.00 | 0.50 | 14.0 | 0.00 | 0.05 | 0.00 | 0.00 | 0.10 | 0.05 | 0.40 | 26.8 | ||
| 5D+ | acc | n/a | 50 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.65 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.05 | 3.45 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.05 | 9.30 | ||
| 5D- | acc | n/a | 50 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.80 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.05 | 3.75 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 9.90 | ||
| 2Dx | acc | n/a | 50 | 2.20 | 2.25 | 2.65 | 2.10 | 2.55 | 5.80 | 6.15 | 19.8 | 1.35 | 2.35 | 3.35 | 2.35 | 4.75 | 9.15 | 11.0 | 27.4 | 1.35 | 2.90 | 2.70 | 2.85 | 4.25 | 6.10 | 7.05 | 29.2 | ||
| 1DC | acc | n/a | 50 | 1.25 | 2.95 | 2.75 | 0.05 | 0.30 | 2.35 | 0.75 | 9.75 | 1.90 | 2.80 | 2.85 | 3.65 | 6.45 | 9.15 | 8.20 | 14.3 | 1.70 | 2.15 | 3.90 | 5.75 | 6.20 | 7.60 | 9.95 | 21.3 | ||
| Cycled Letters | acc | n/a | 100 | 0.62 | 0.71 | 2.85 | 0.00 | 0.63 | 1.35 | 2.58 | 3.66 | 1.67 | 4.36 | 5.68 | 6.46 | 6.25 | 9.41 | 15.1 | 21.7 | 4.63 | 9.27 | 10.7 | 14.5 | 16.7 | 21.9 | 27.7 | 37.9 | ||
| Anagrams 1 | acc | n/a | 100 | 0.10 | 0.14 | 0.40 | 0.00 | 0.27 | 0.69 | 1.16 | 2.28 | 0.21 | 0.61 | 1.12 | 1.27 | 1.60 | 2.72 | 3.72 | 8.62 | 0.50 | 1.27 | 2.13 | 3.05 | 3.81 | 5.49 | 8.38 | 15.1 | ||
| Anagrams 2 | acc | n/a | 100 | 0.81 | 1.21 | 2.69 | 0.01 | 1.71 | 3.75 | 4.53 | 8.91 | 1.19 | 2.62 | 4.70 | 4.77 | 6.97 | 10.2 | 14.6 | 25.9 | 1.94 | 4.80 | 7.59 | 9.87 | 12.6 | 18.9 | 25.6 | 39.7 | ||
| Symbol Insertion | acc | n/a | 100 | 0.00 | 0.00 | 0.10 | 0.00 | 0.05 | 0.42 | 0.89 | 8.26 | 0.03 | 0.05 | 0.57 | 1.18 | 1.67 | 3.46 | 6.62 | 45.4 | 0.11 | 0.28 | 2.19 | 4.18 | 6.61 | 11.0 | 27.3 | 67.2 | ||
| Reversed Words | acc | n/a | 100 | 0.00 | 0.01 | 0.01 | 0.01 | 0.02 | 0.03 | 0.03 | 0.09 | 0.02 | 0.01 | 0.01 | 0.00 | 0.05 | 0.07 | 0.11 | 0.48 | 0.00 | 0.05 | 0.00 | 0.17 | 0.24 | 0.30 | 0.42 | 0.44 | ||
| SAT Analogies | acc | n/a | 20 | 35.6 | 39.0 | 45.2 | 44.1 | 50.0 | 49.2 | 52.7 | 53.7 | 30.5 | 41.2 | 43.1 | 46.5 | 55.1 | 54.3 | 53.5 | 59.1 | 30.5 | 40.4 | 42.8 | 40.6 | 48.4 | 51.9 | 53.5 | 65.2 | ||
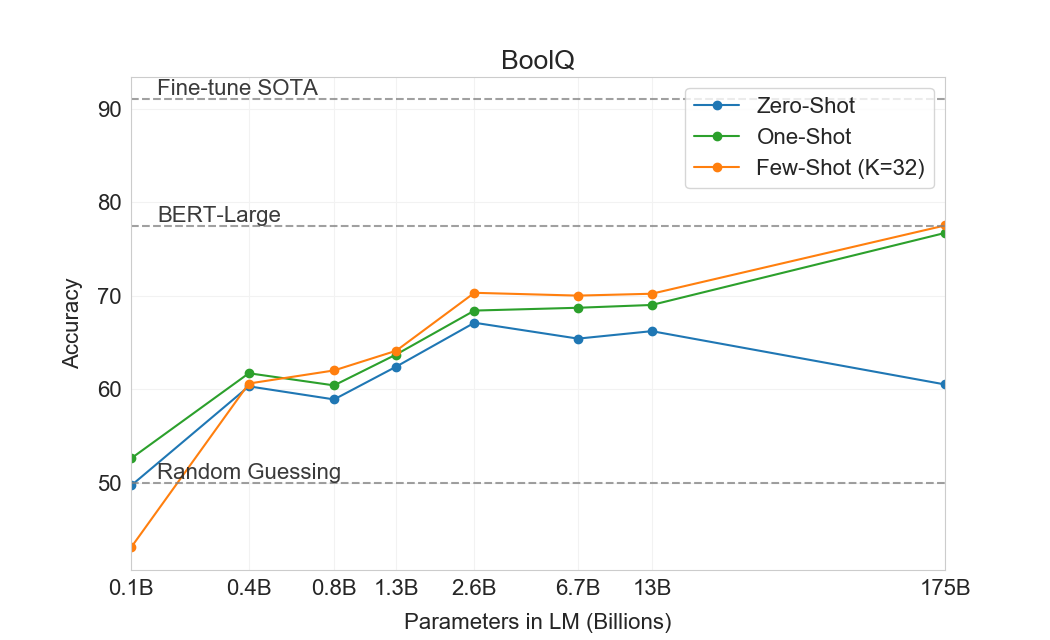 |
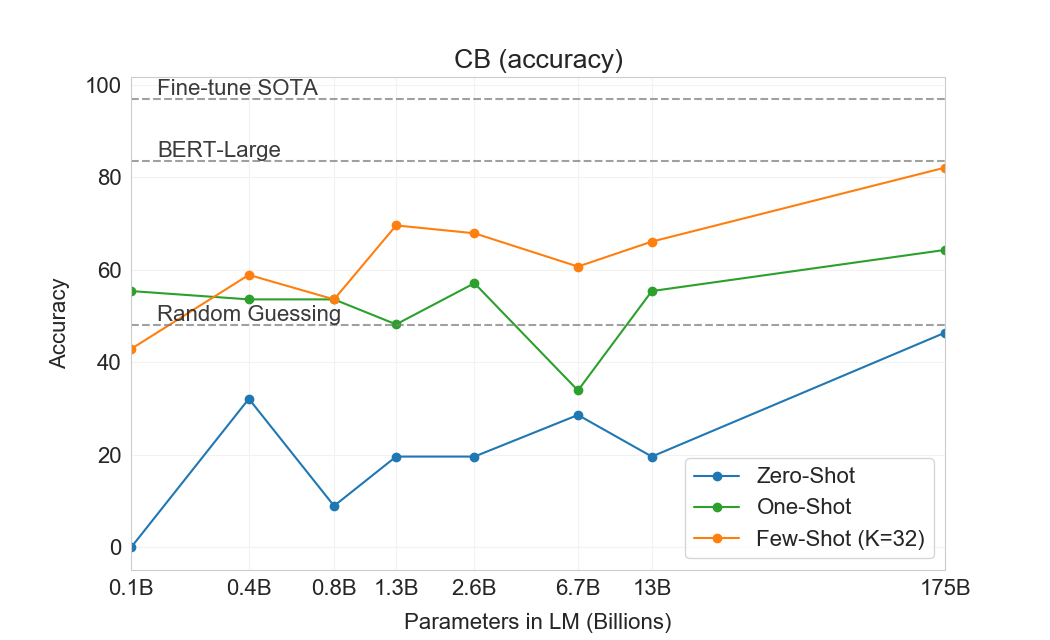 |
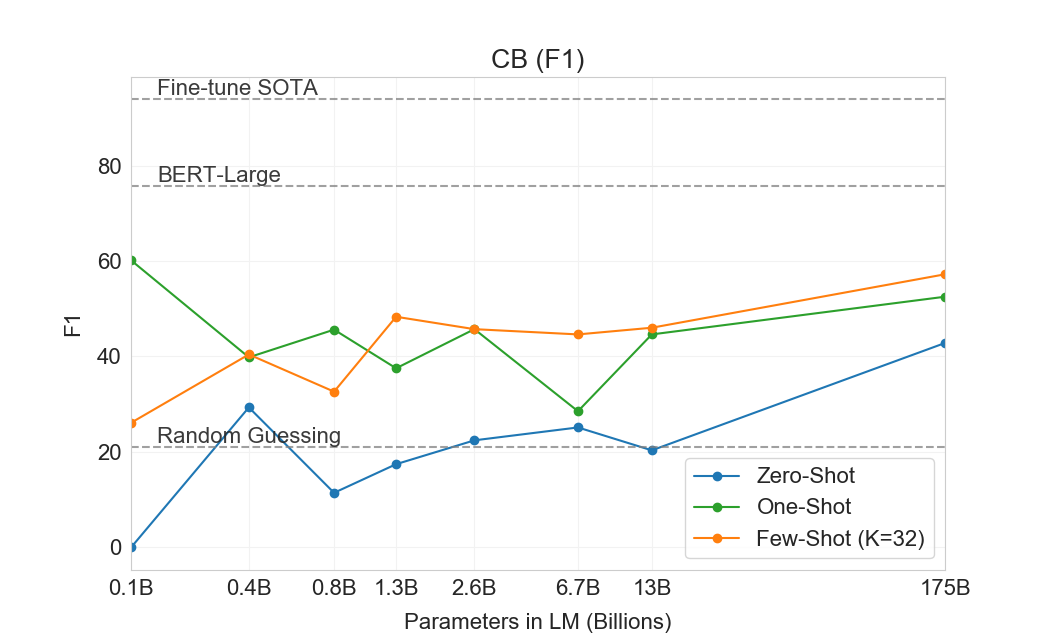 |
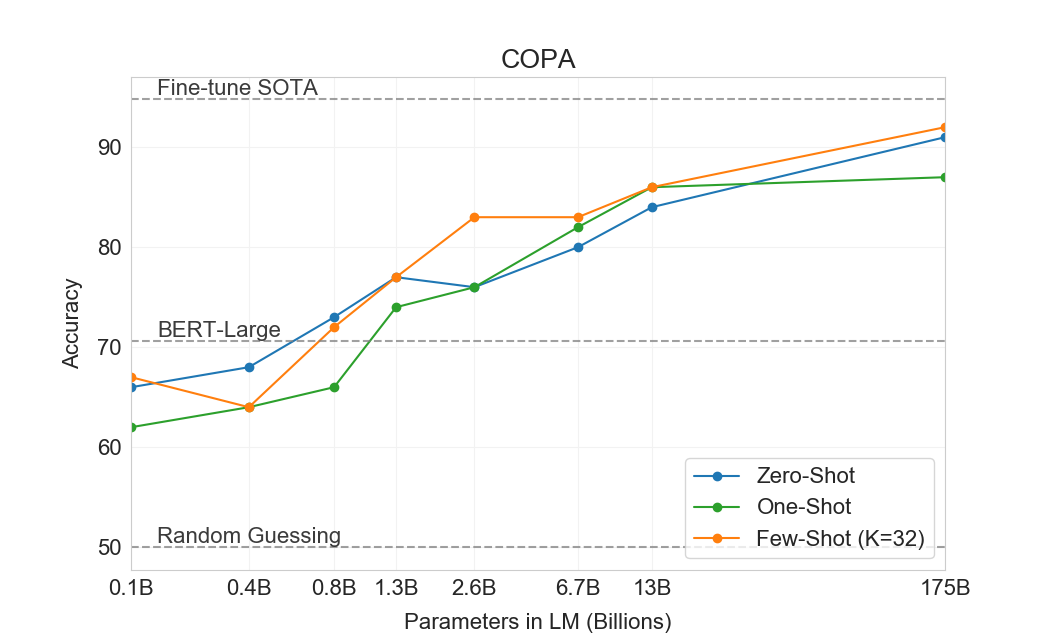 |
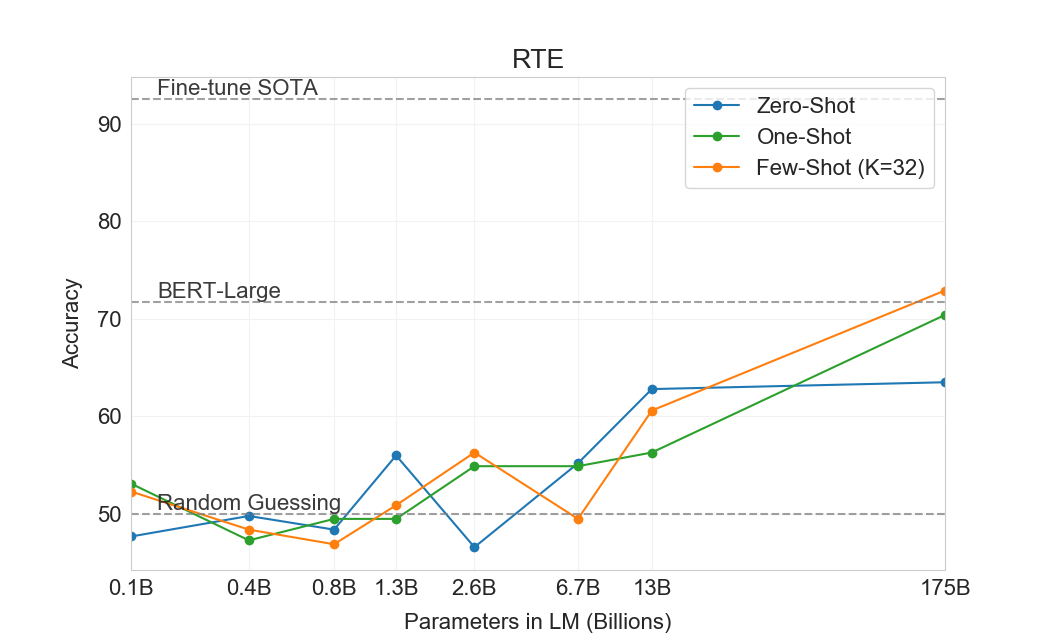 |
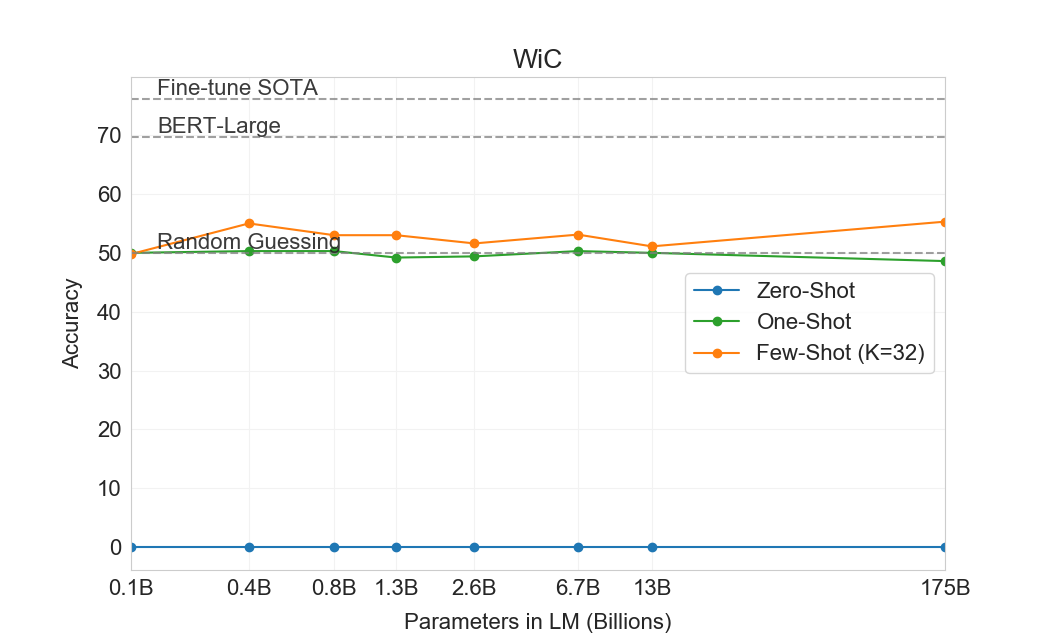 |
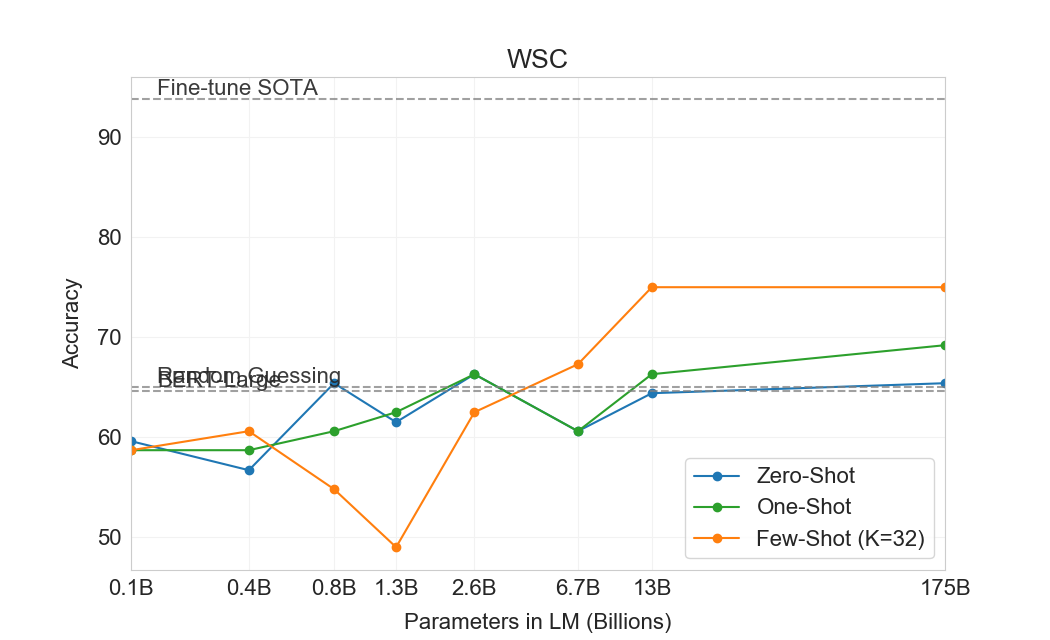 |
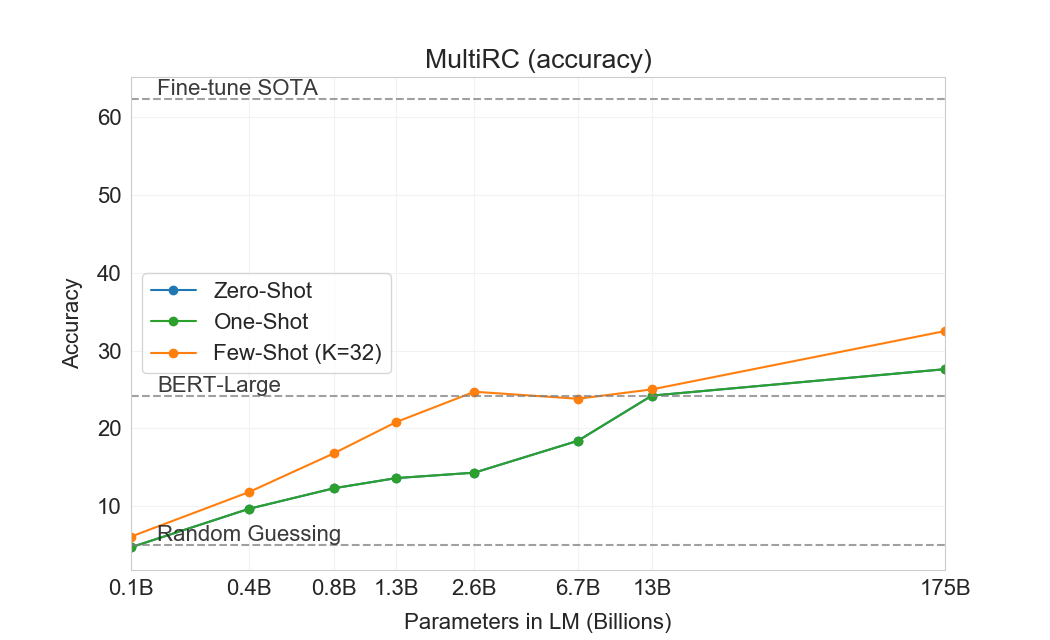 |
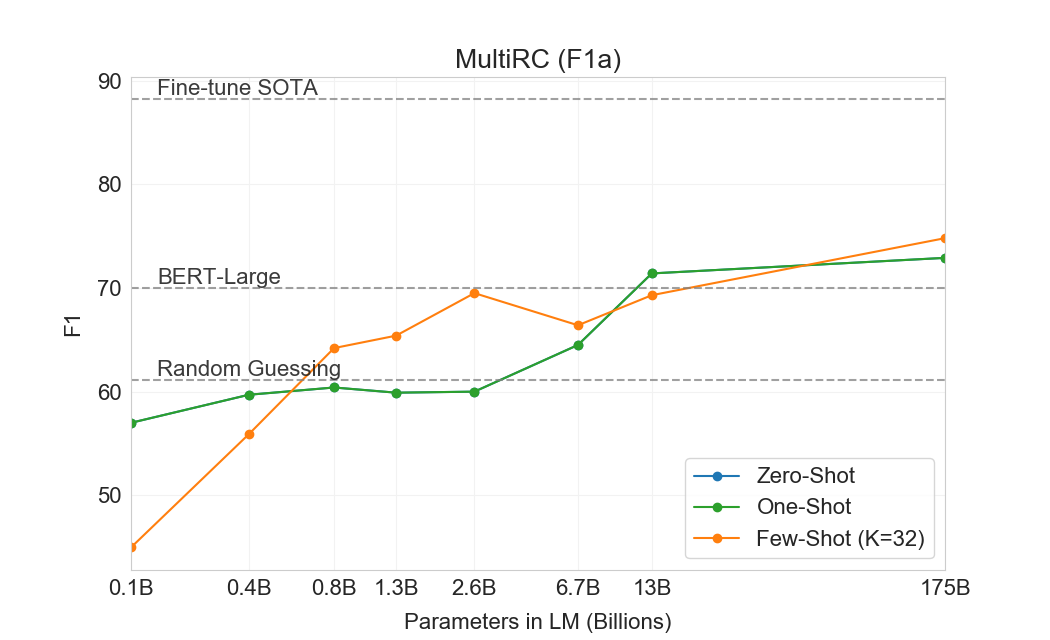 |
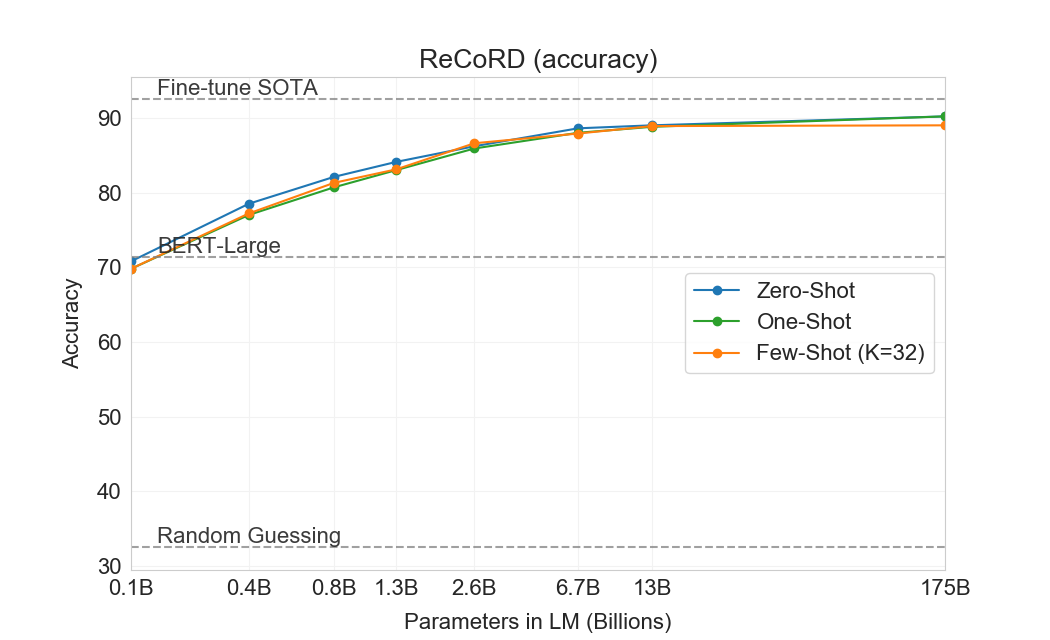 |
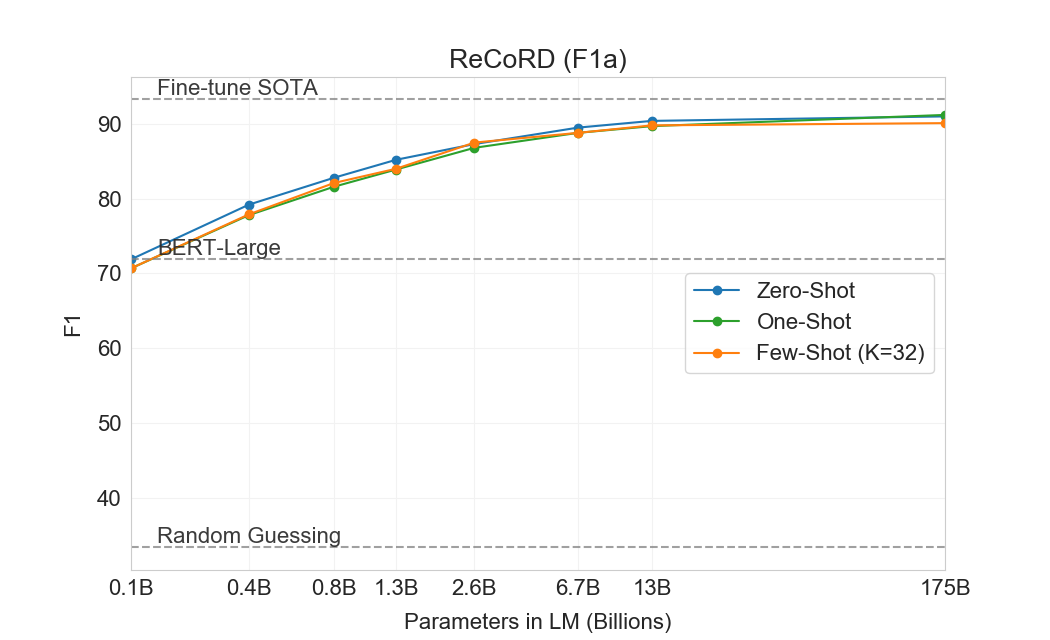 |
|
|
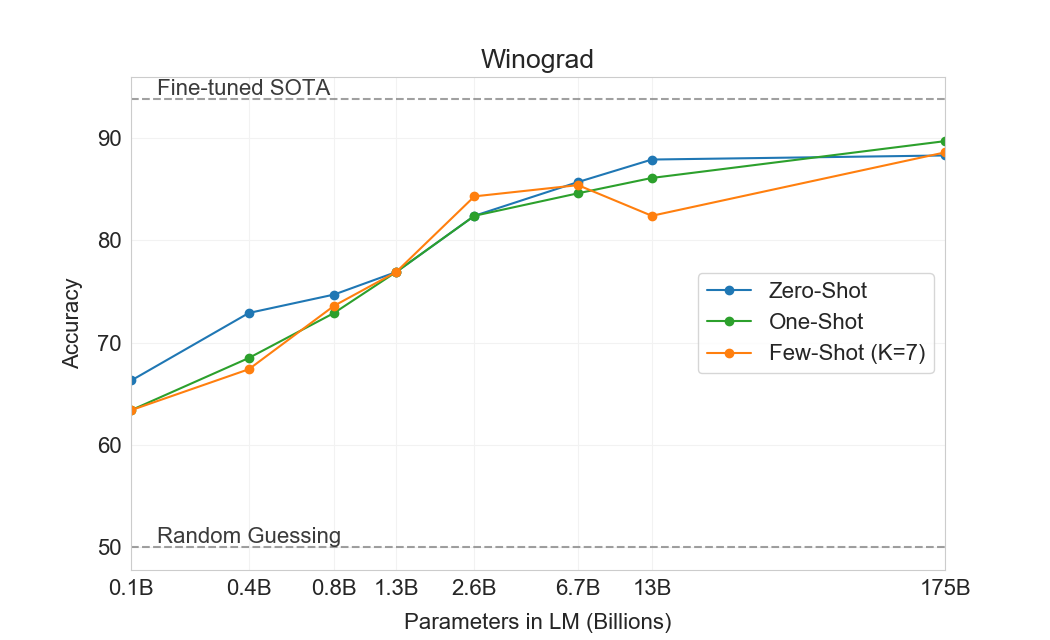 |
|
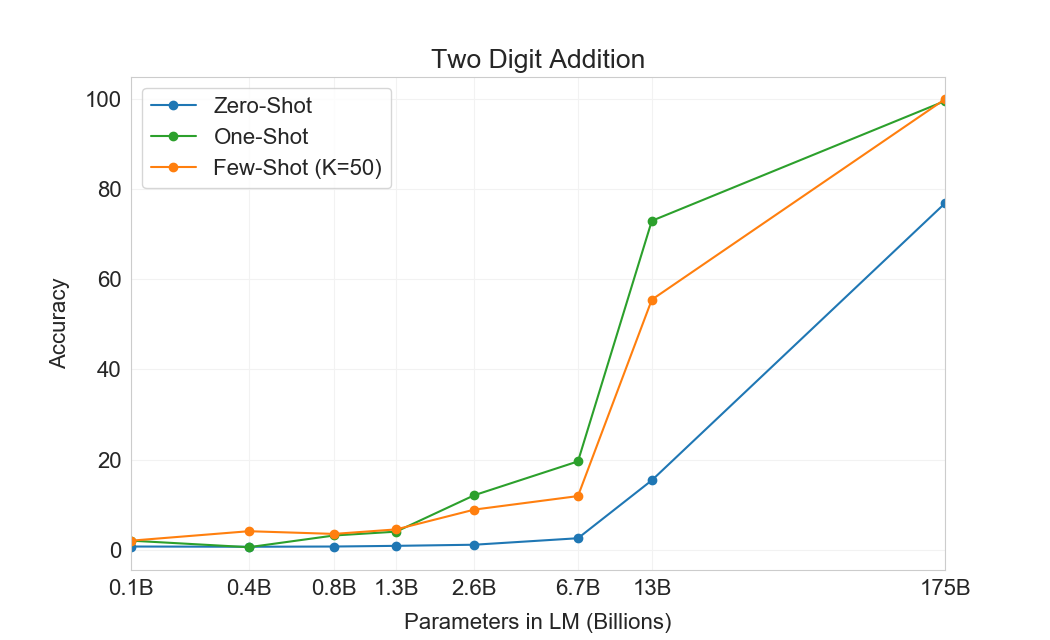 |
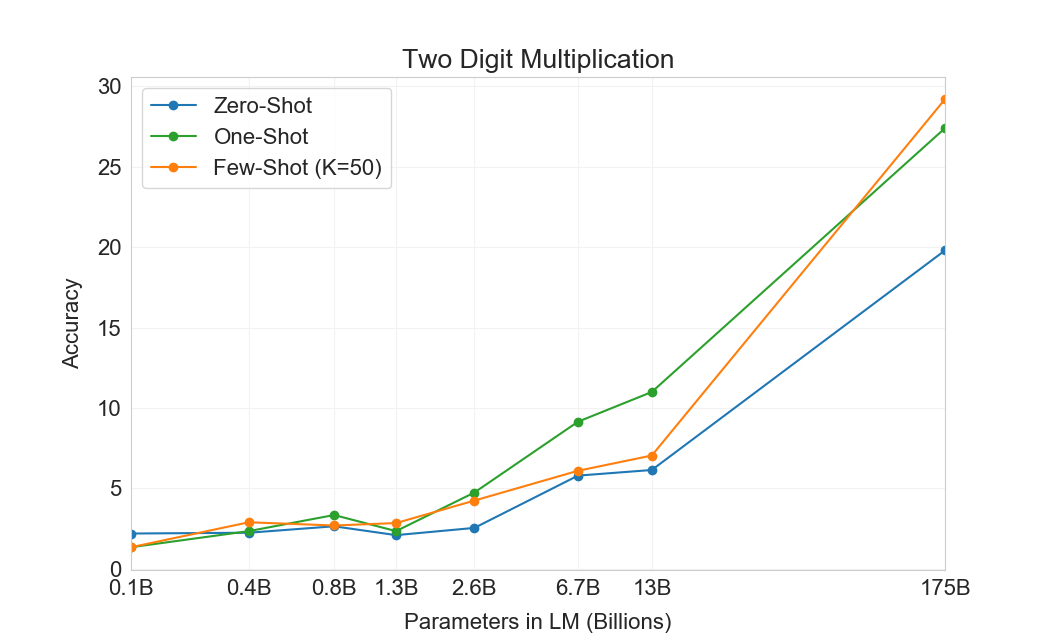 |
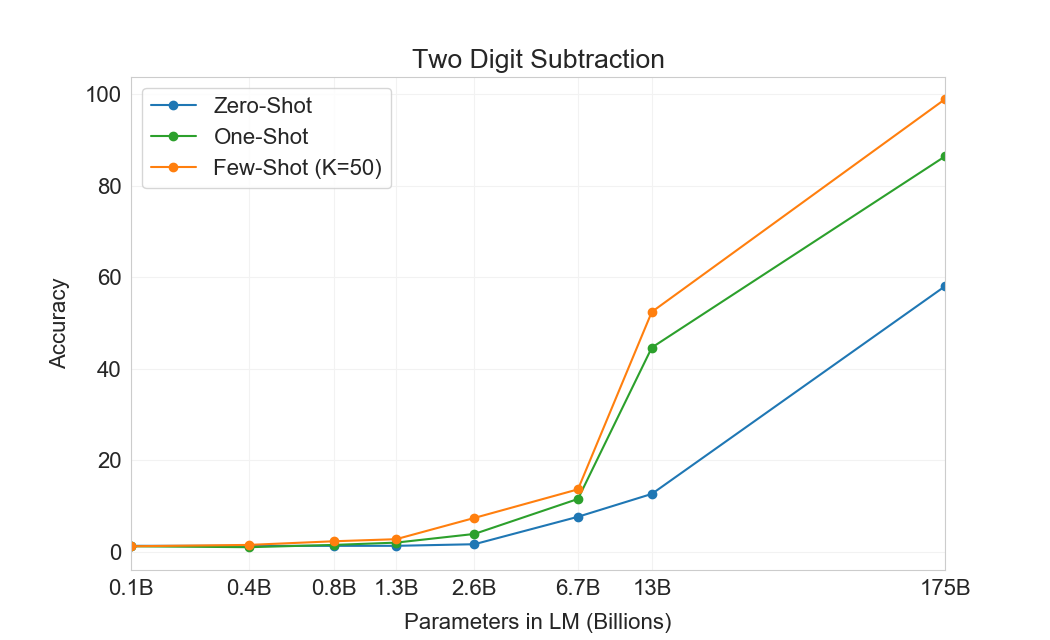 |
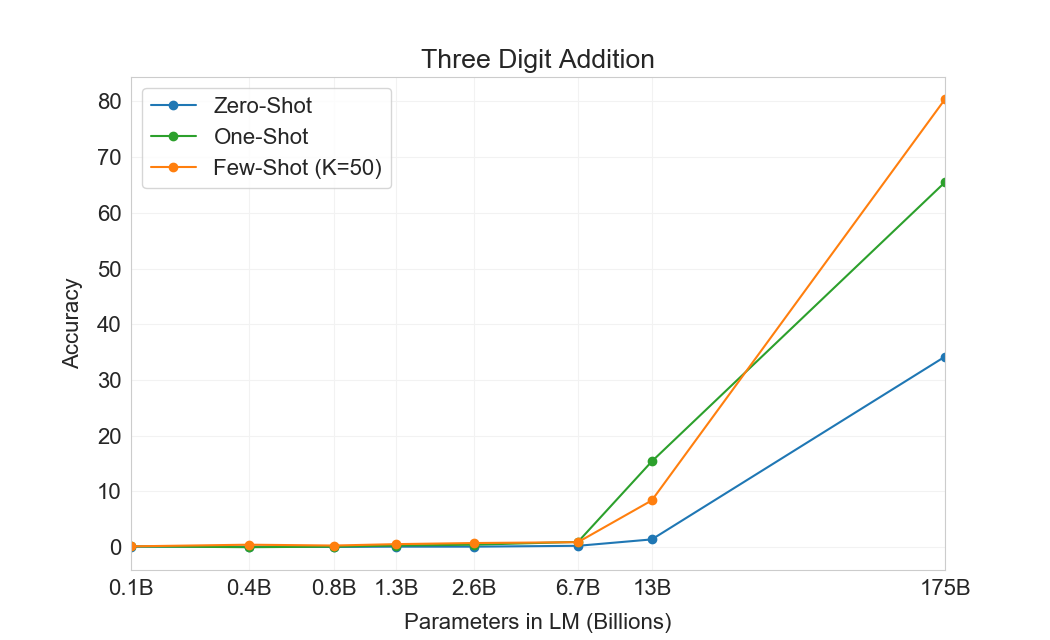 |
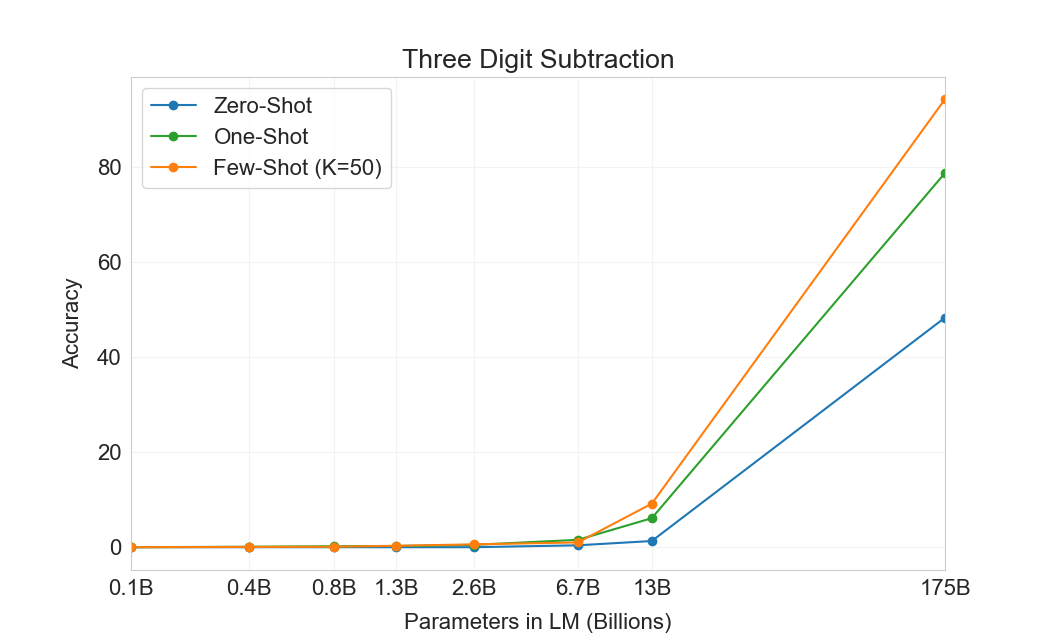 |
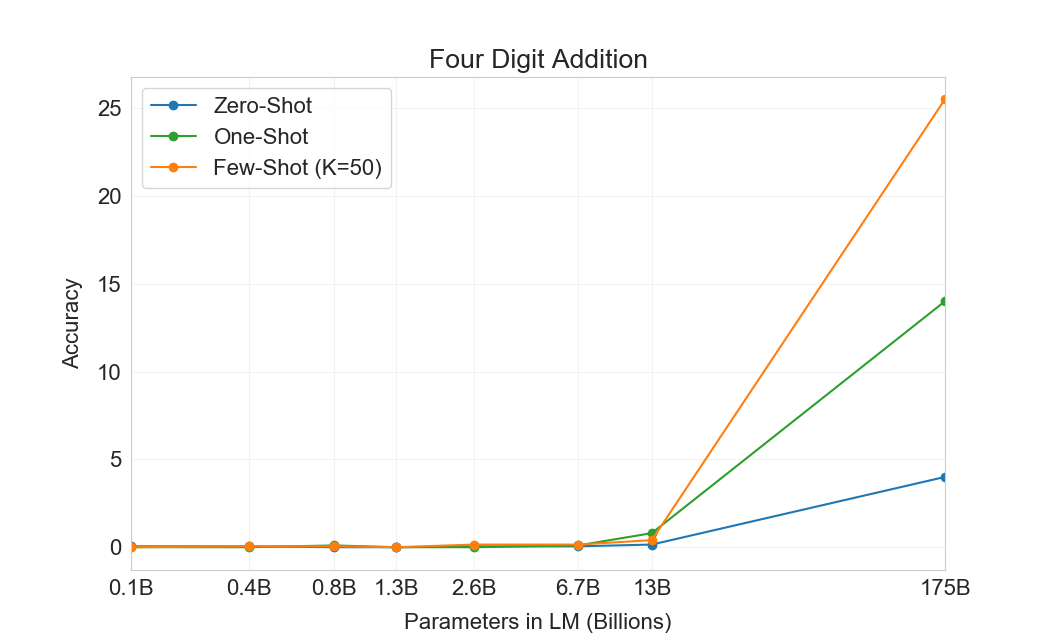 |
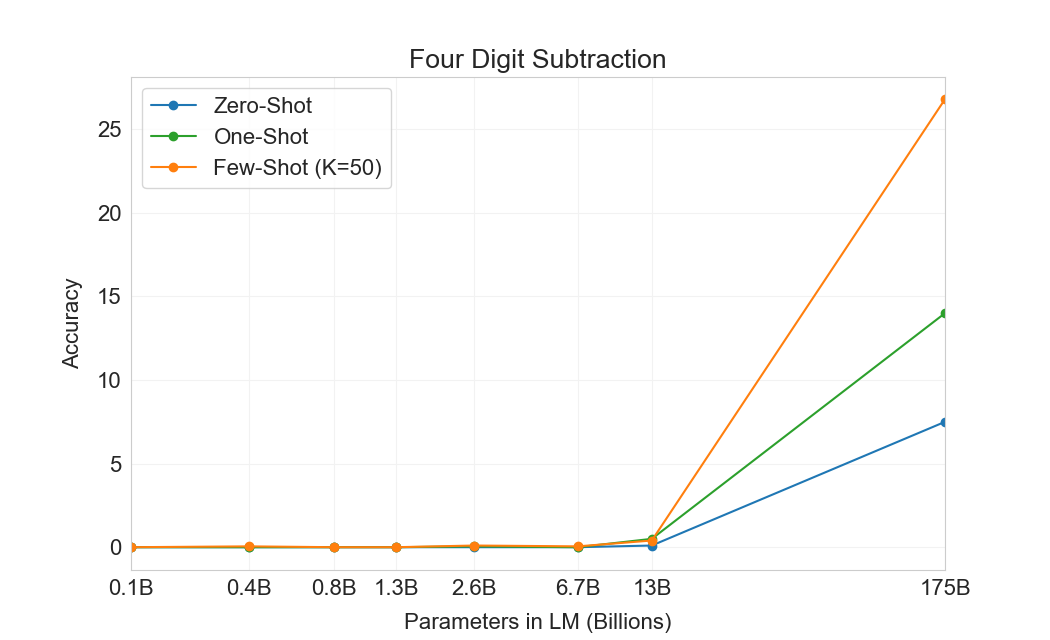 |
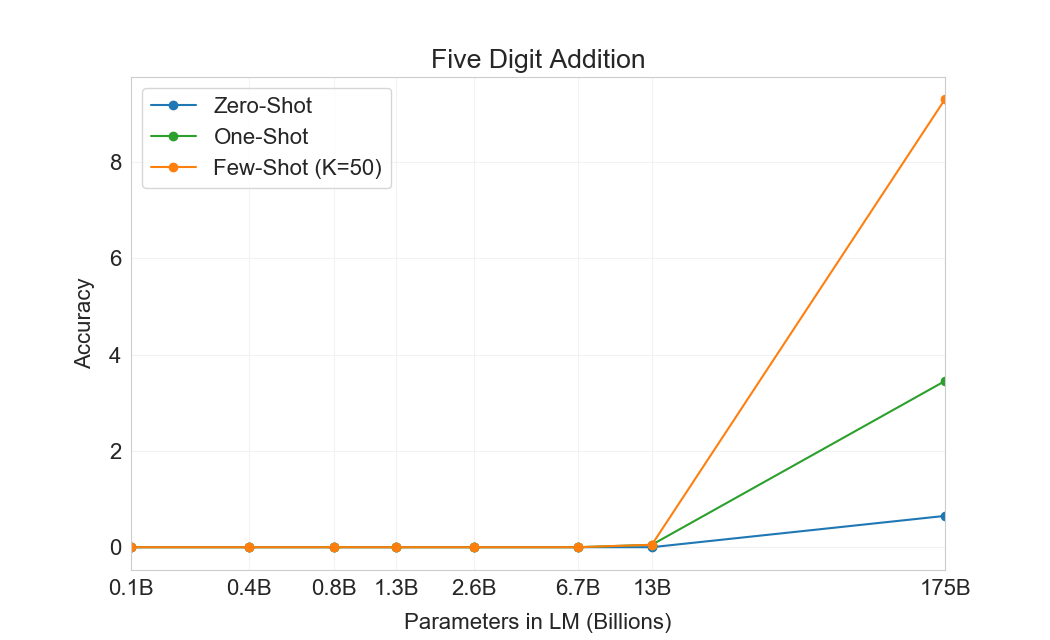 |
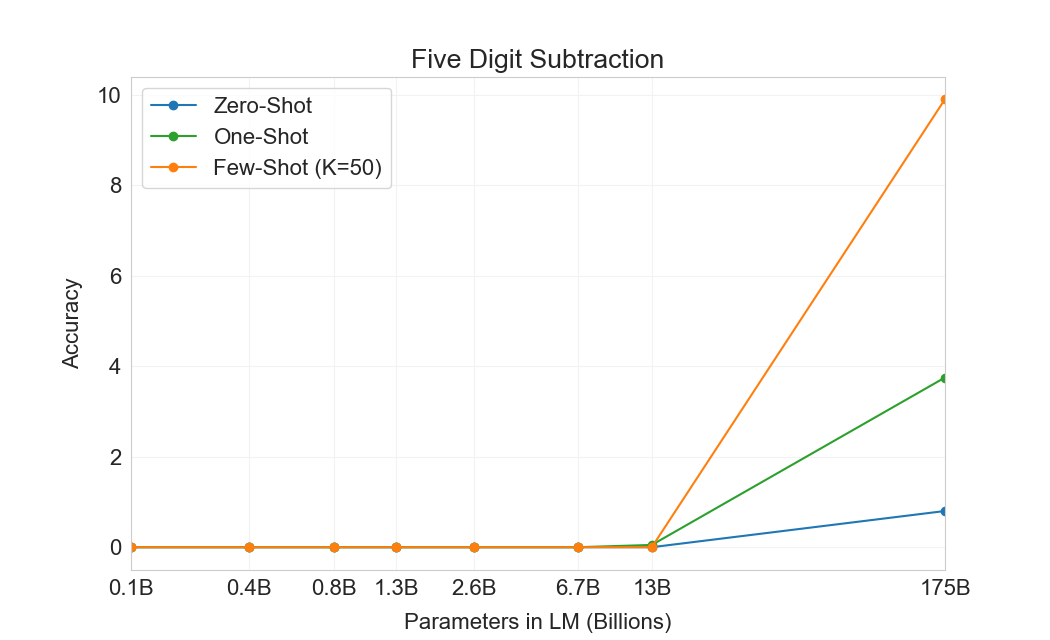 |
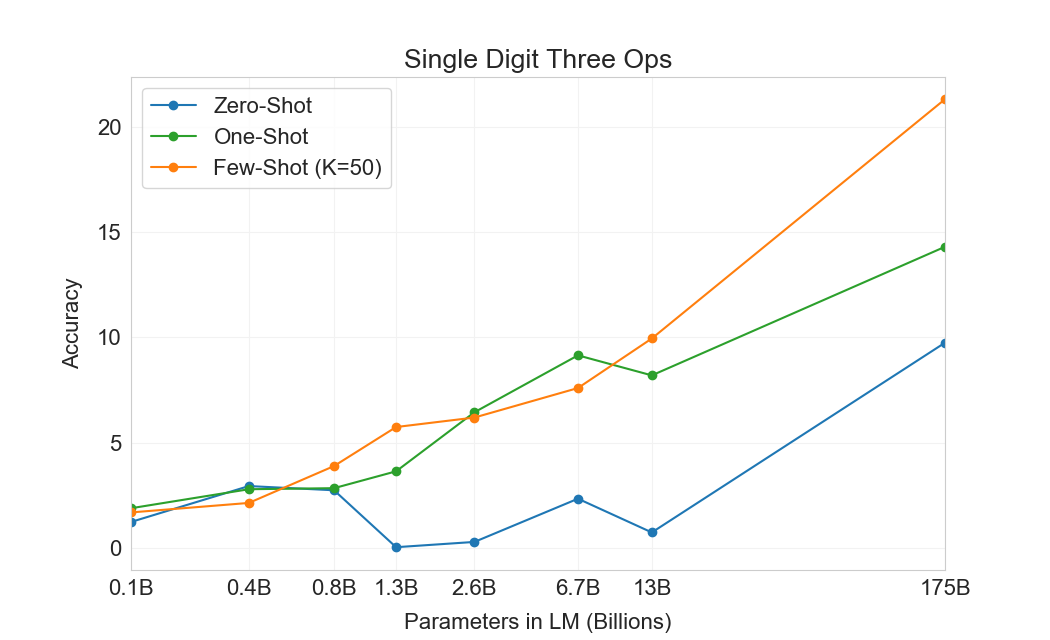 |
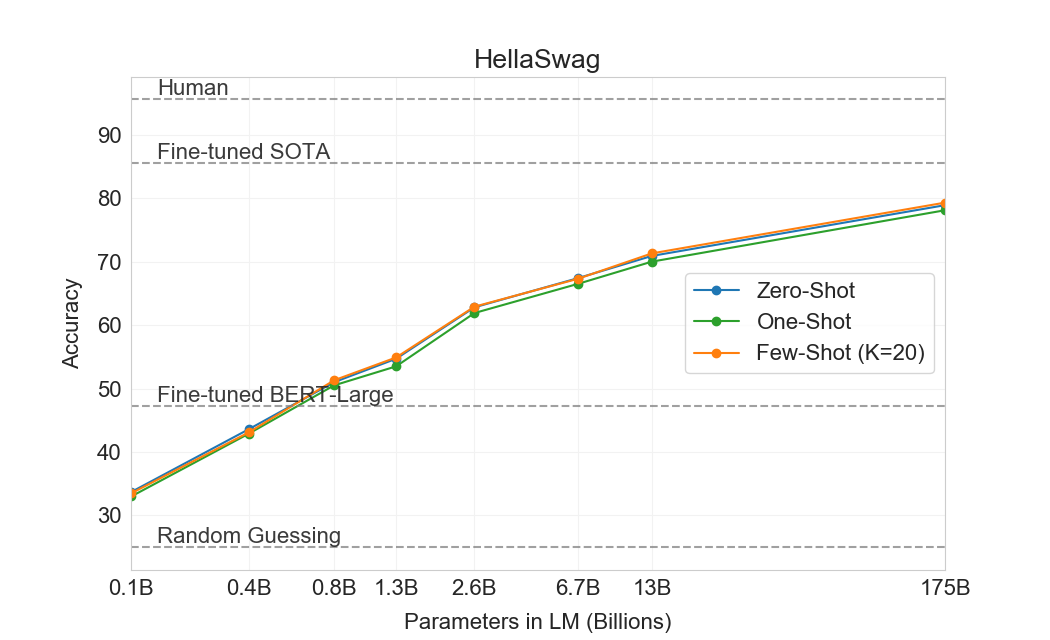 |
|
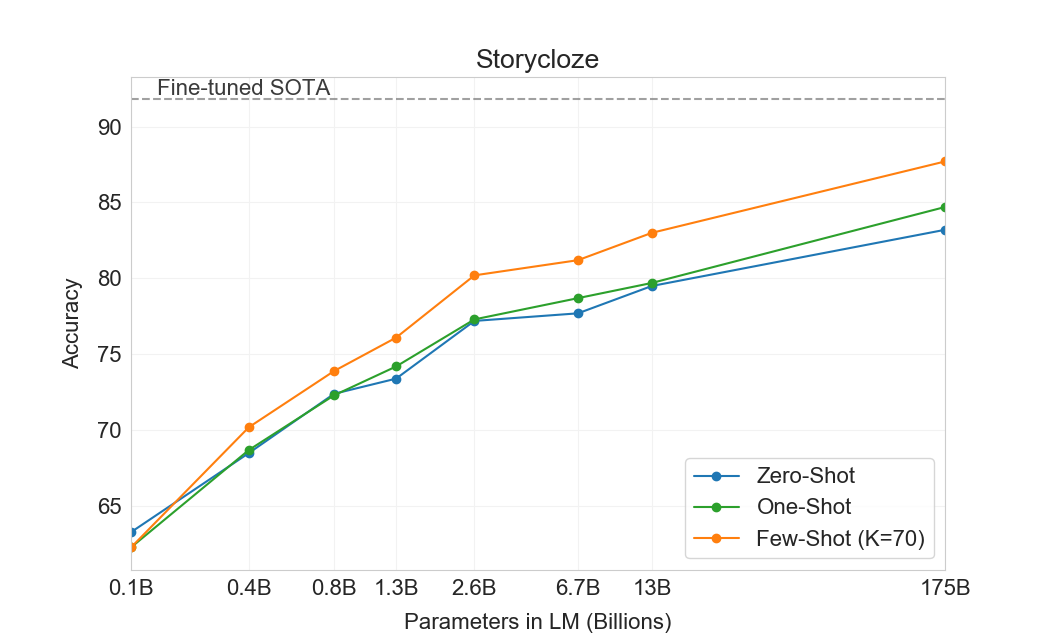 |
|
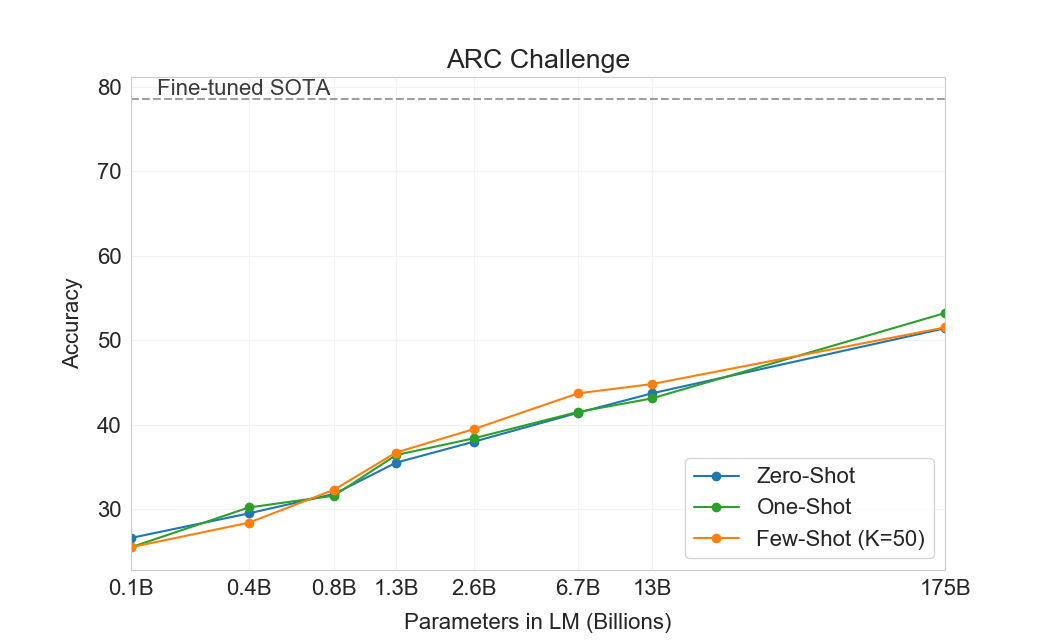 |
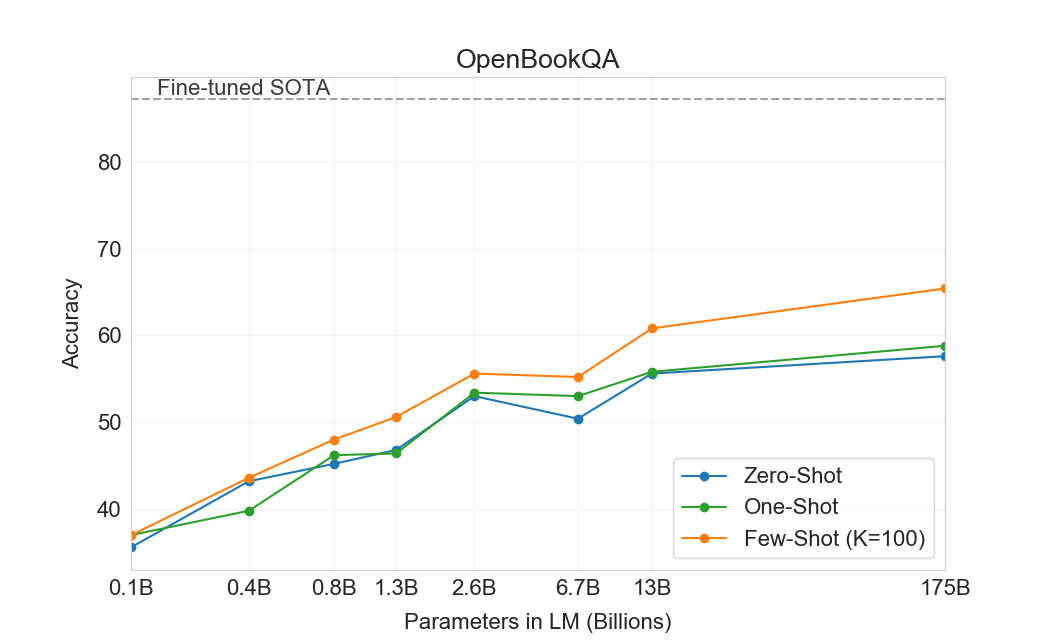 |
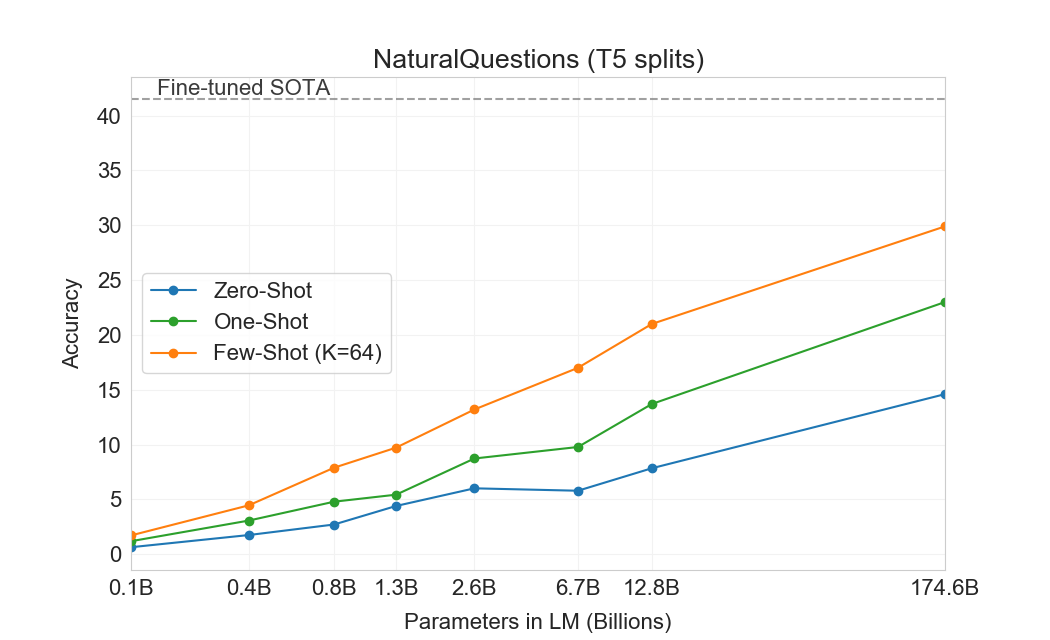 |
|
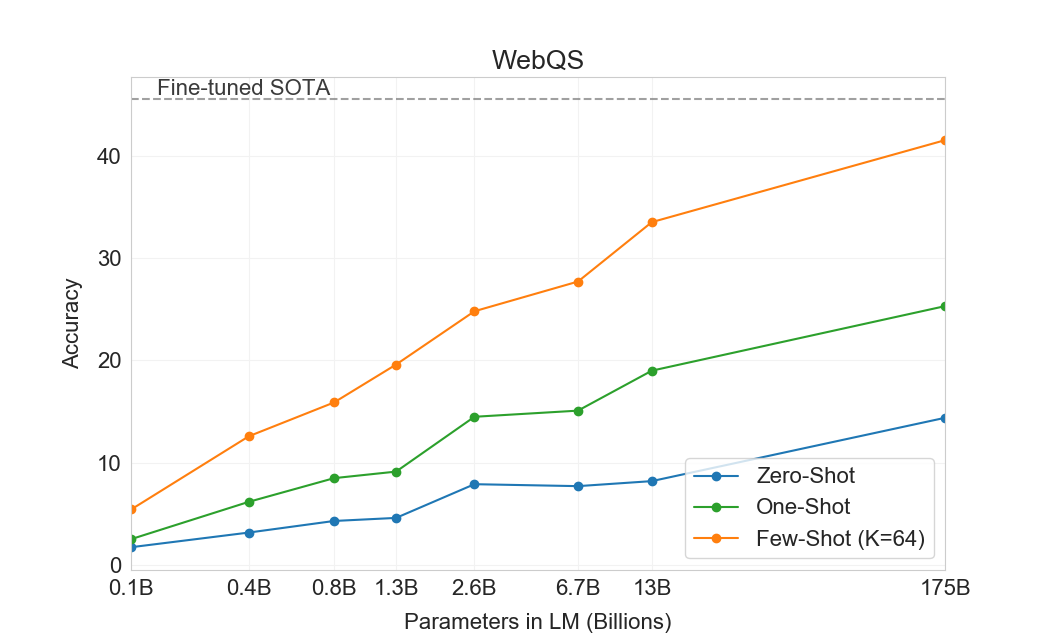 |
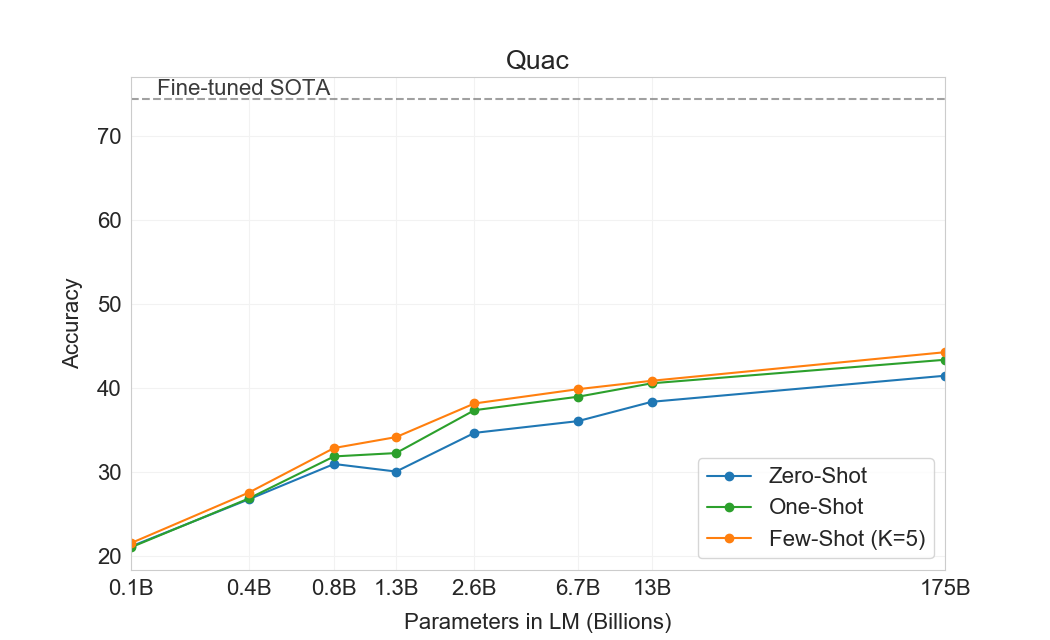 |
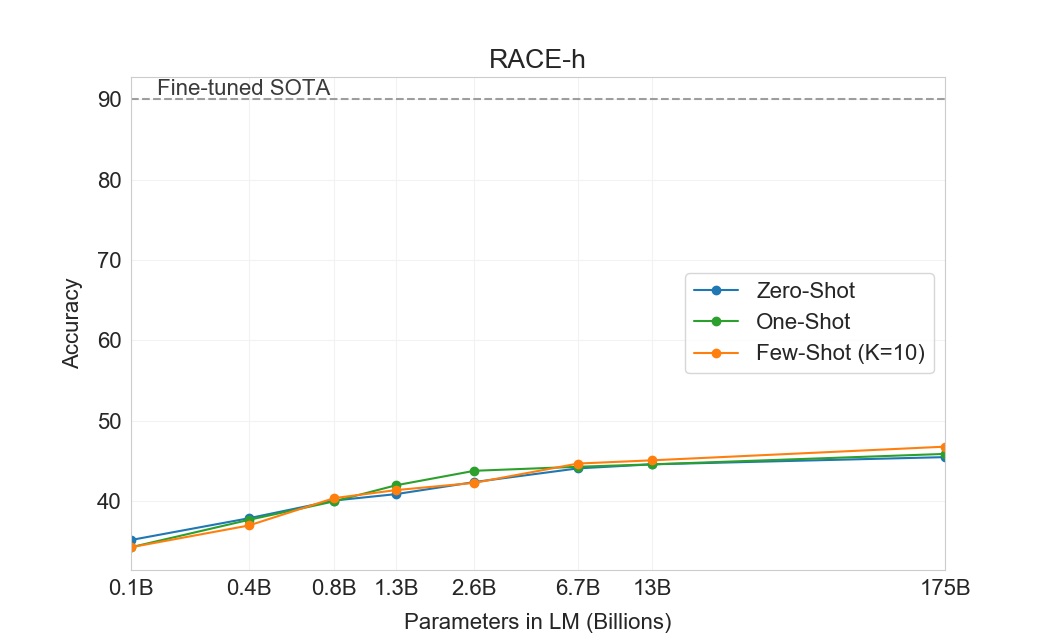 |
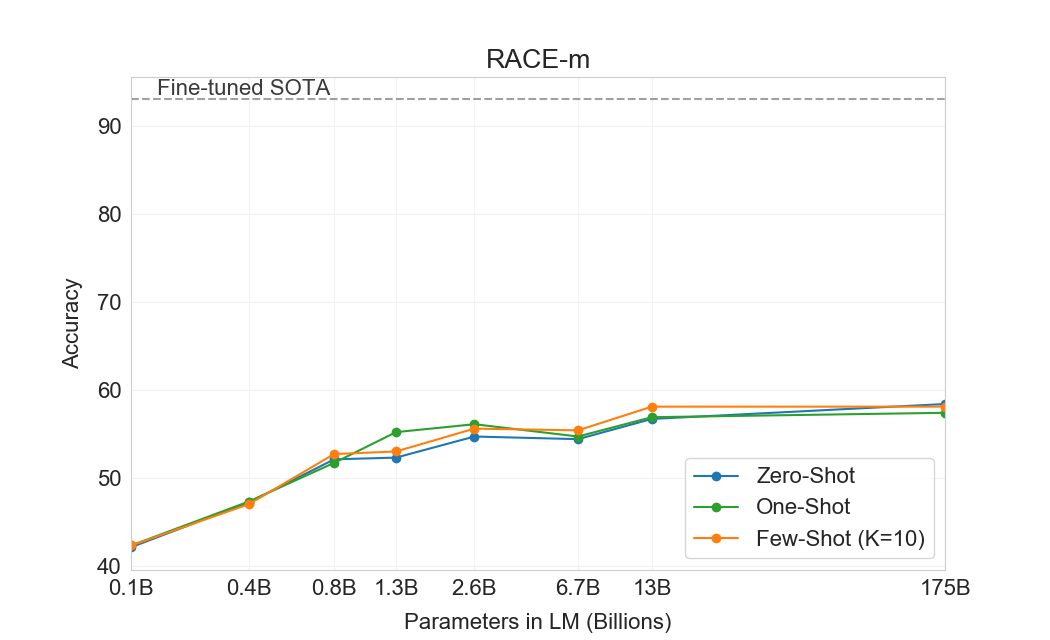 |
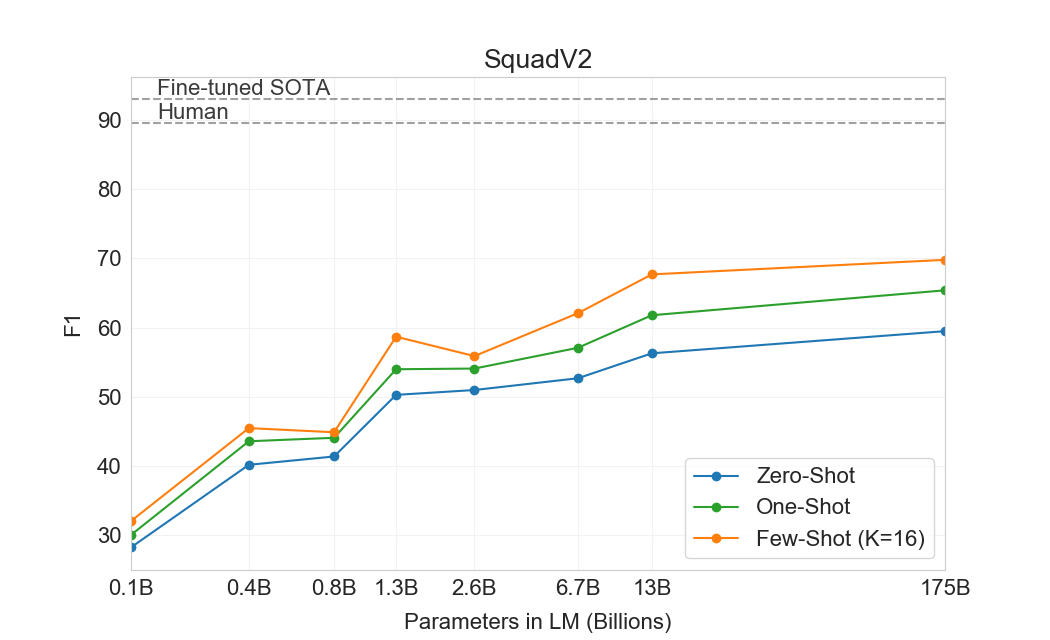 |
|
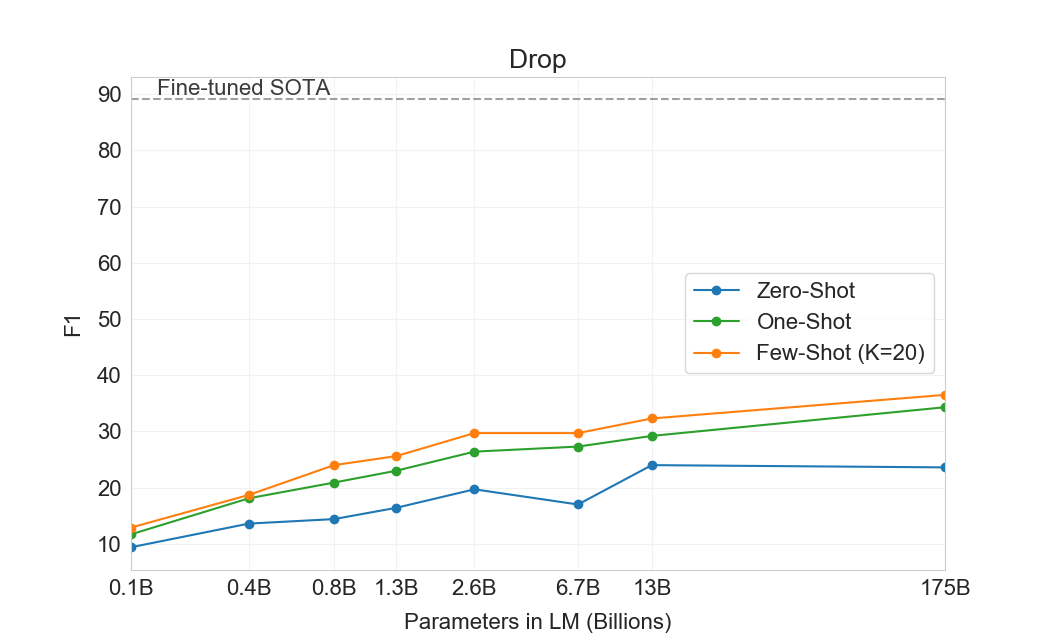 |
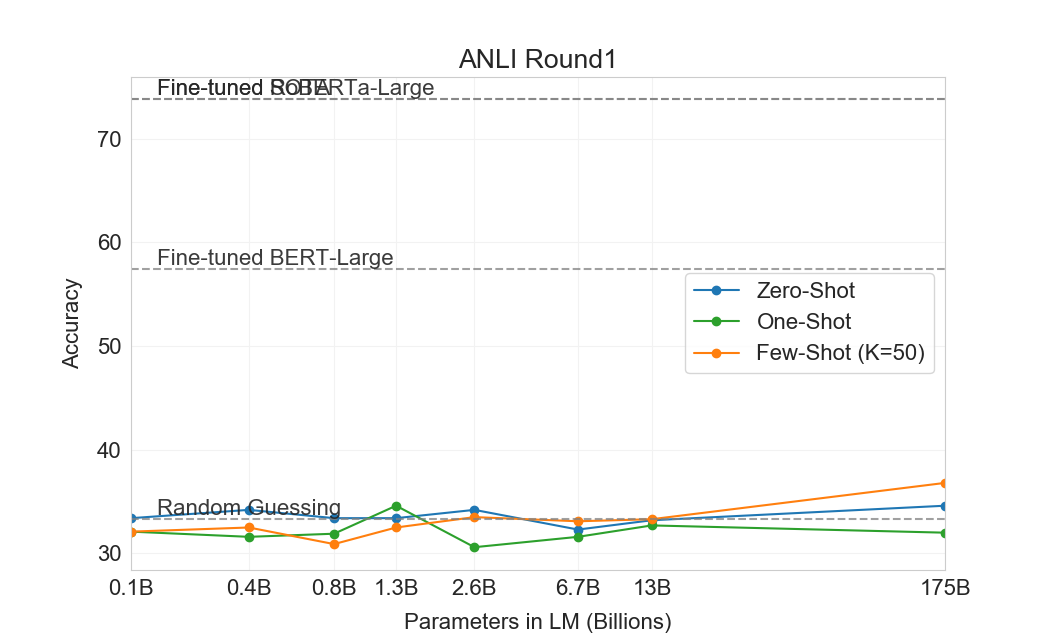 |
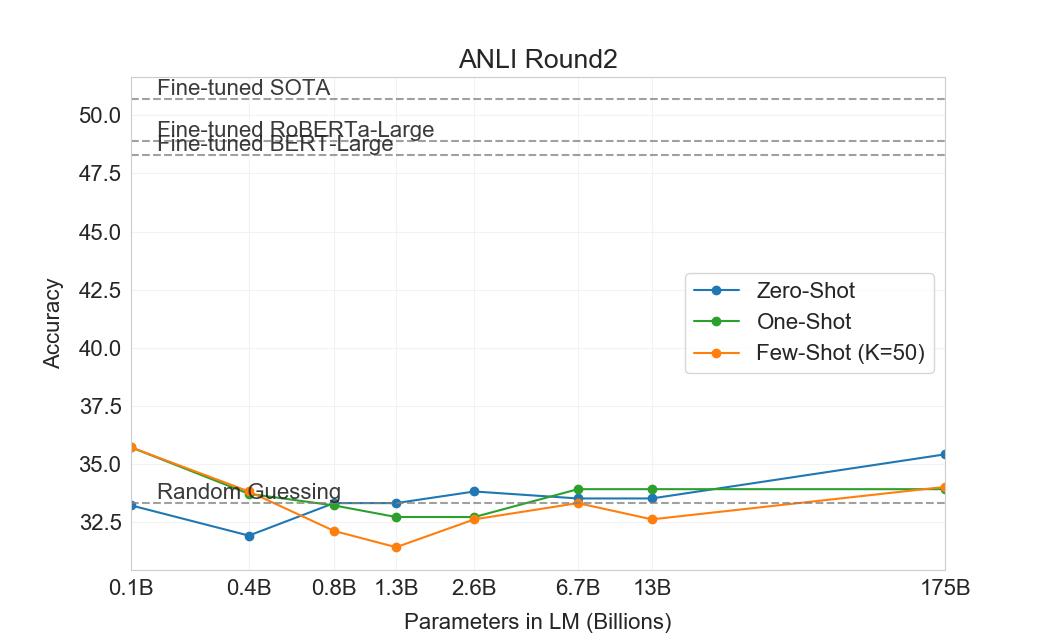 |
|
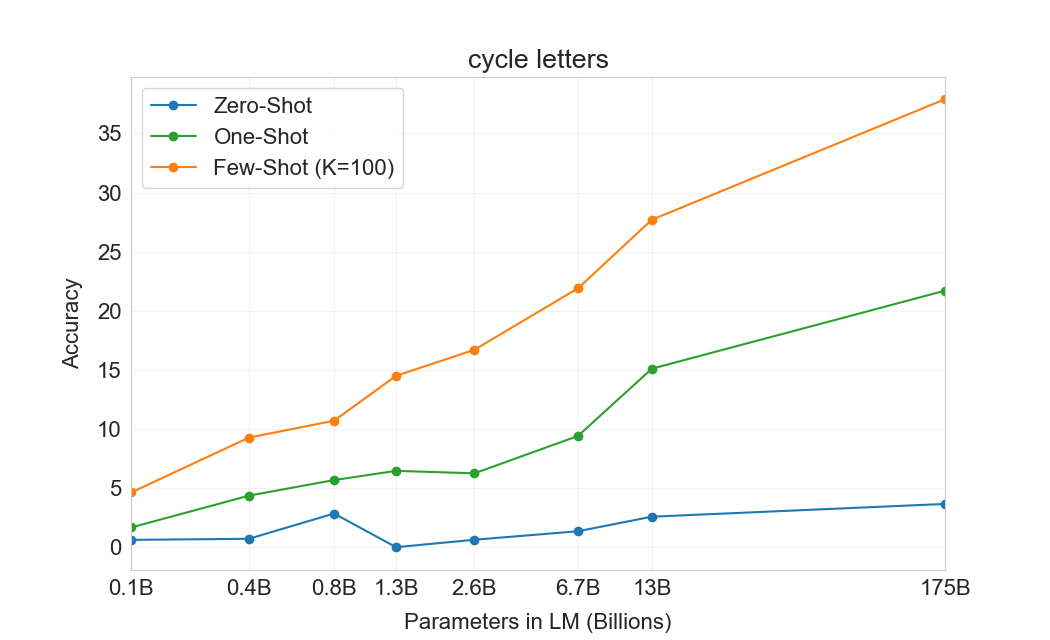 |
|
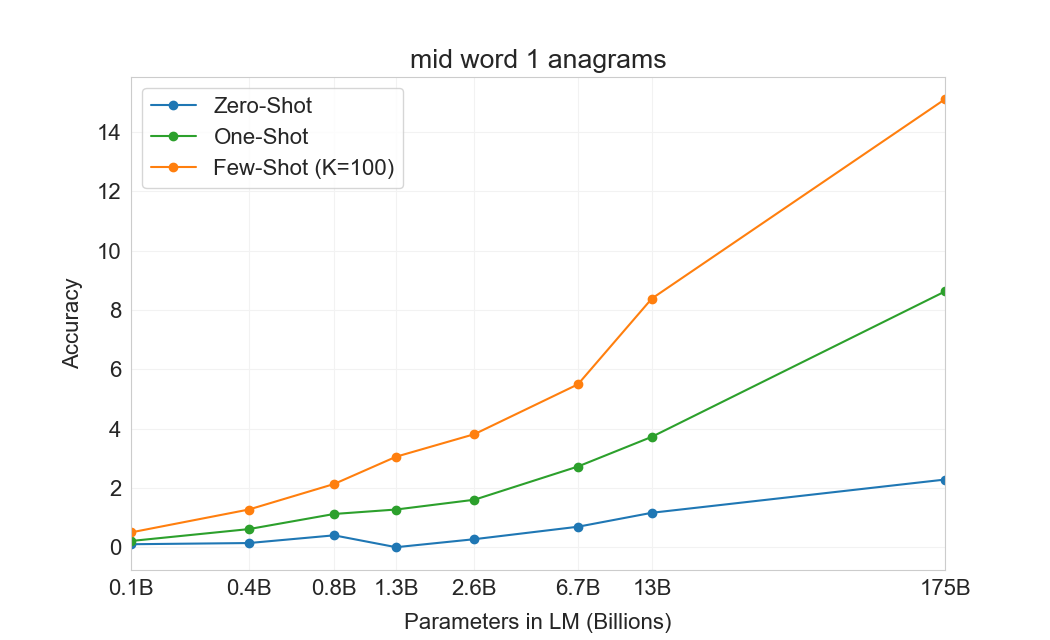 |
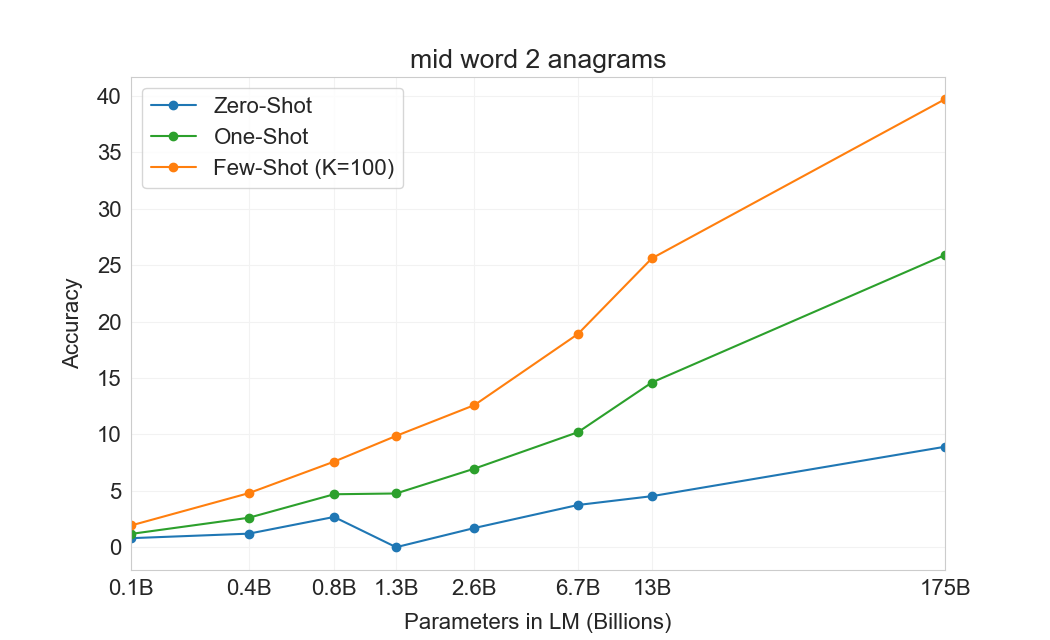 |
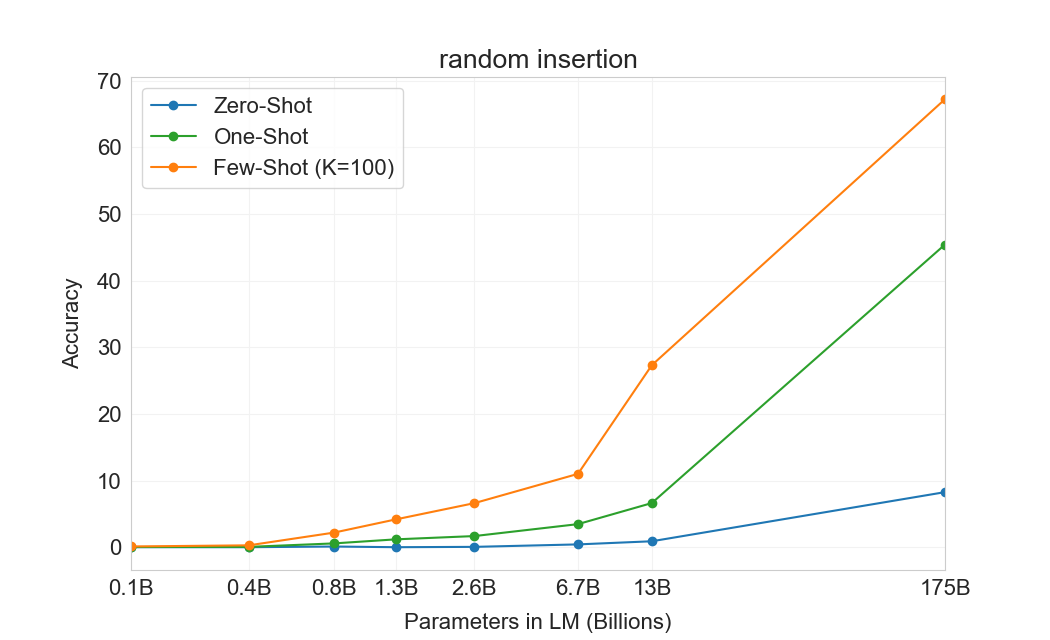 |
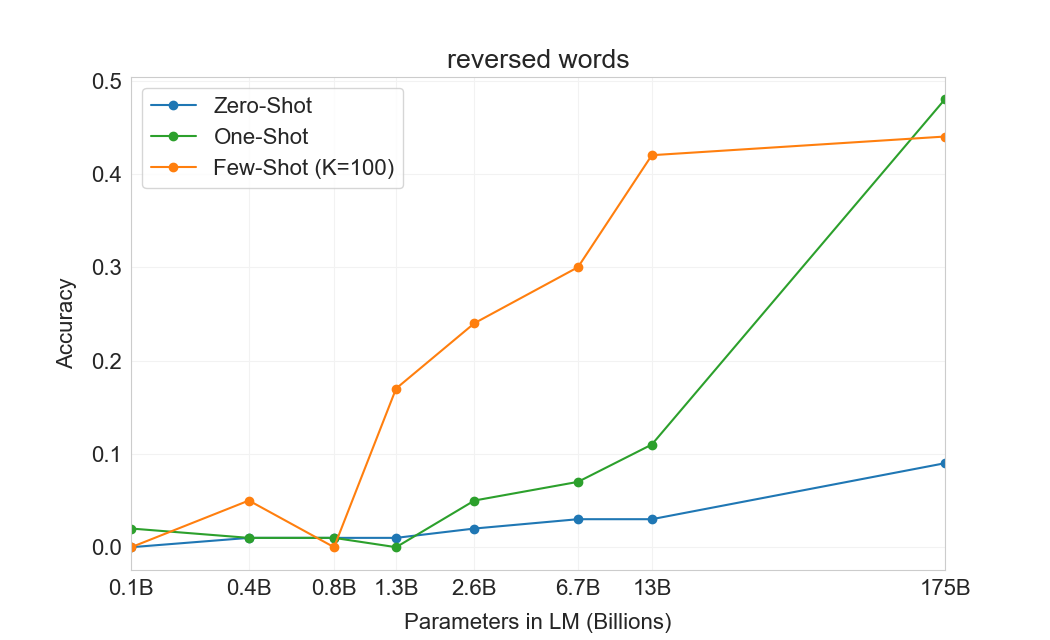 |
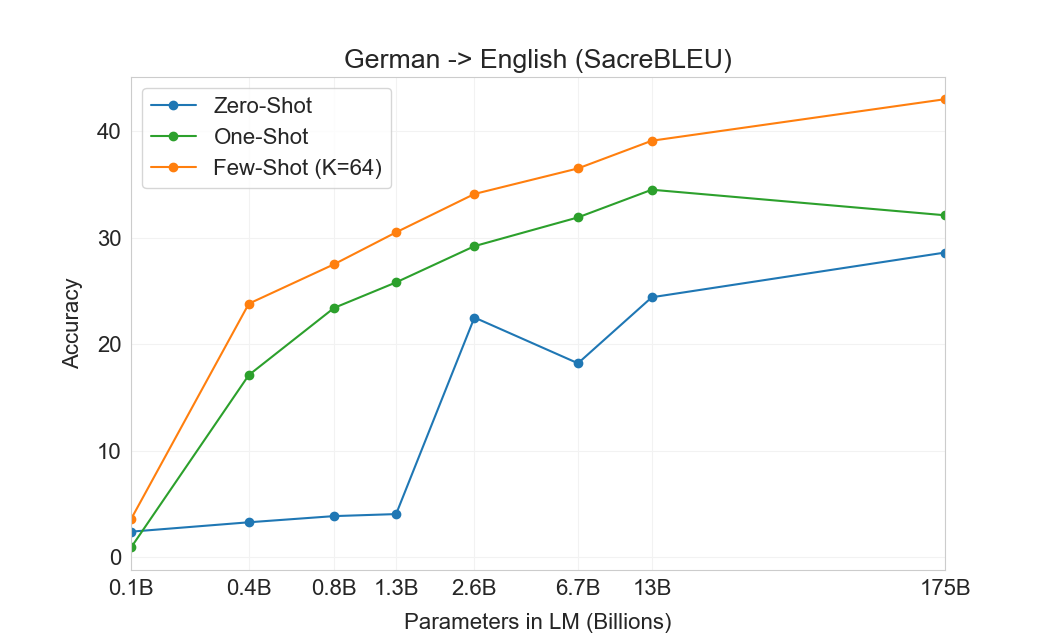 |
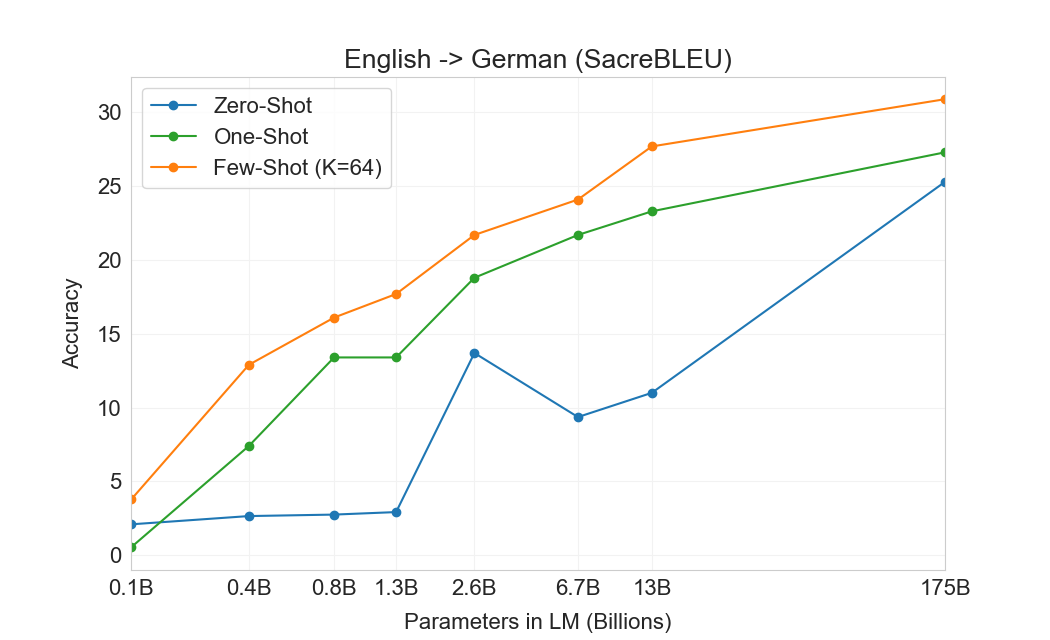 |
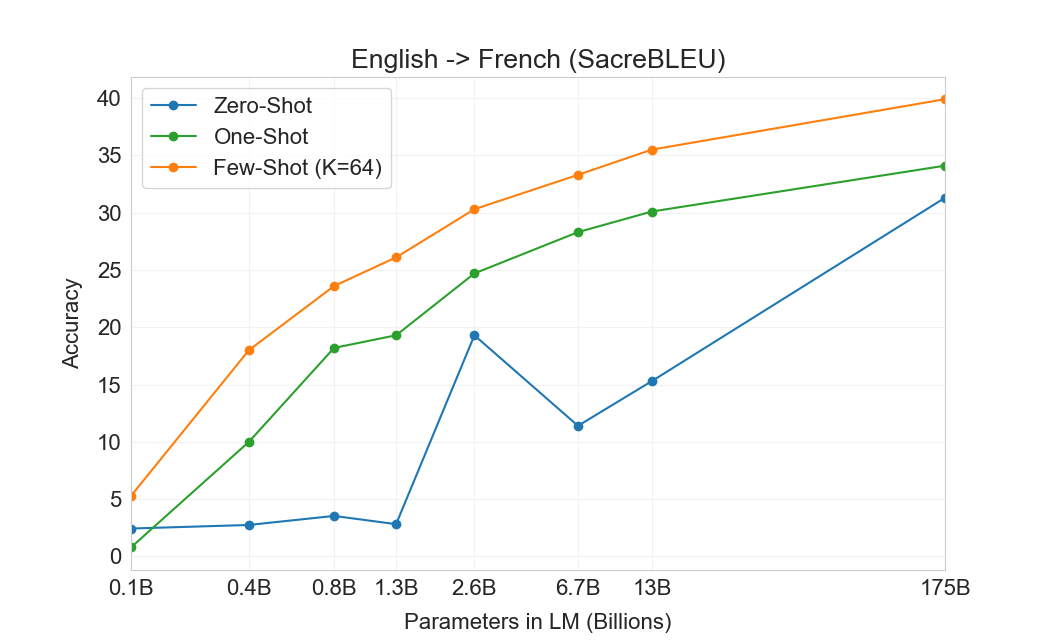 |
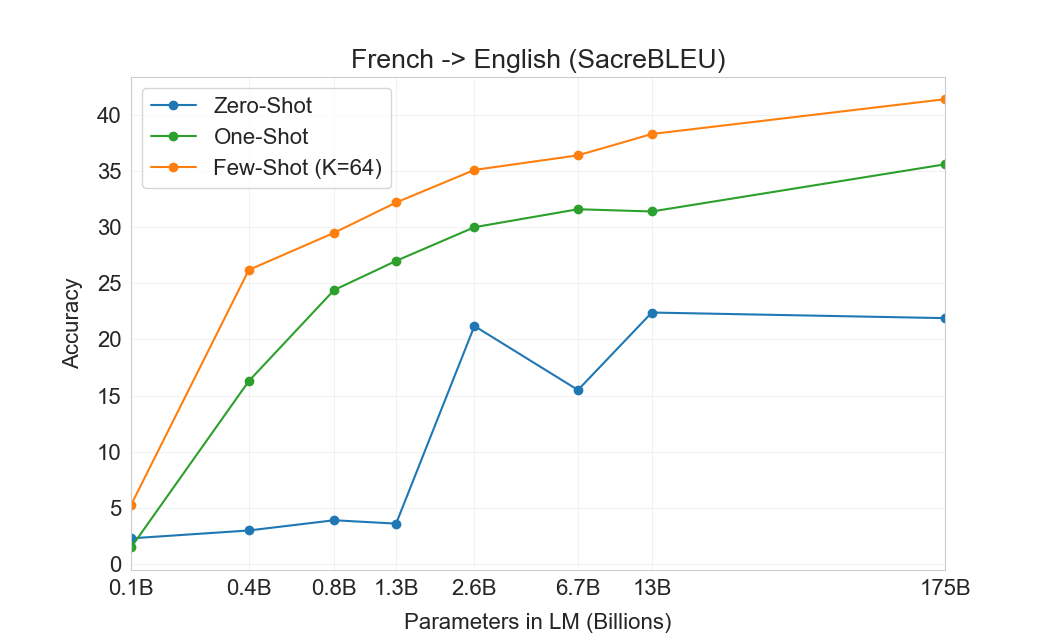 |
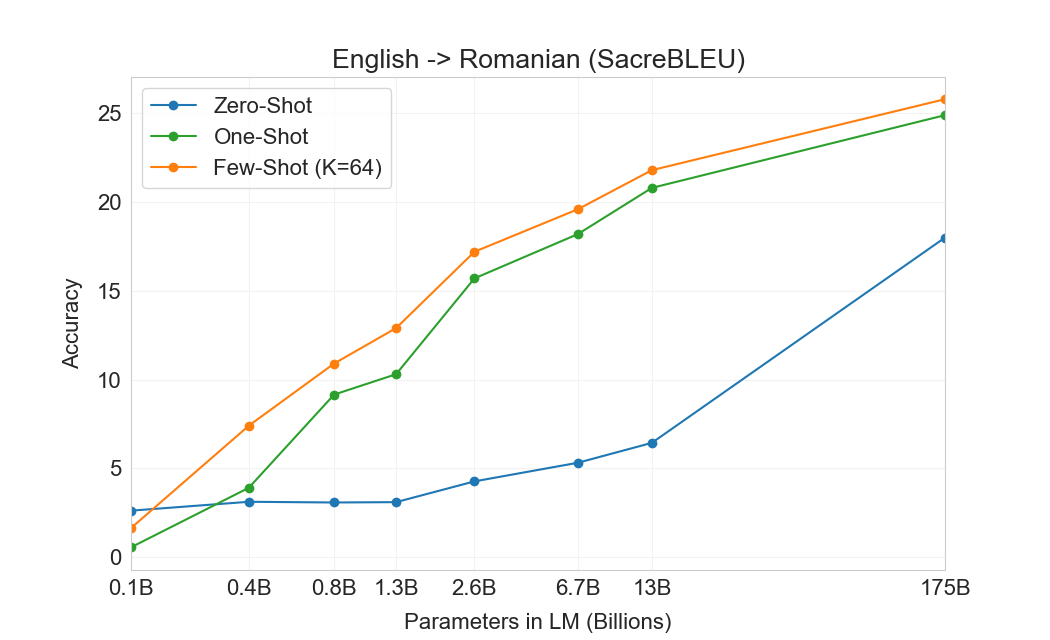 |
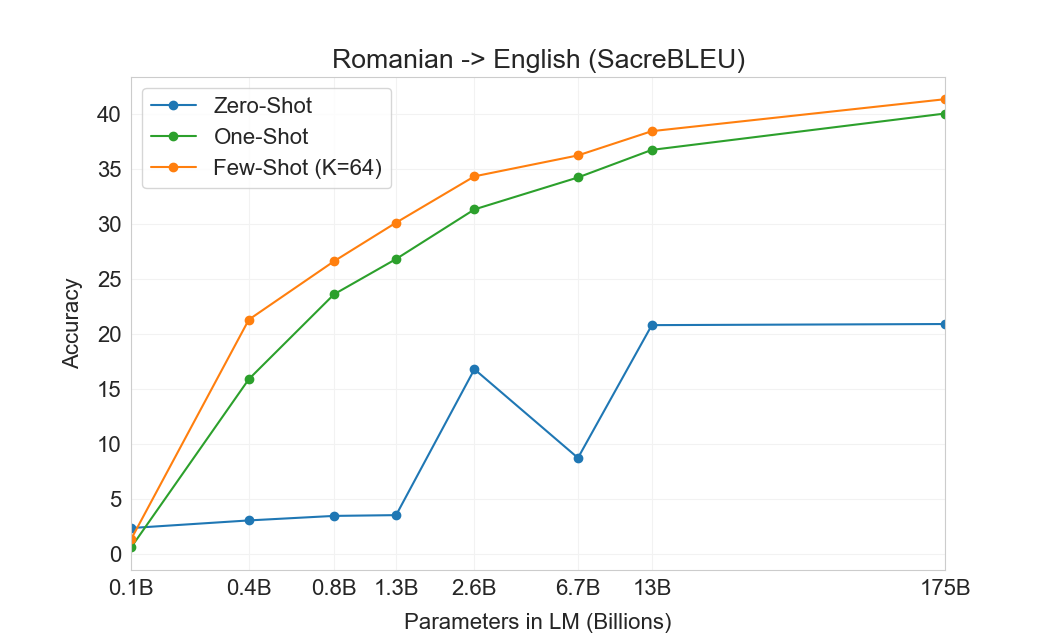 |
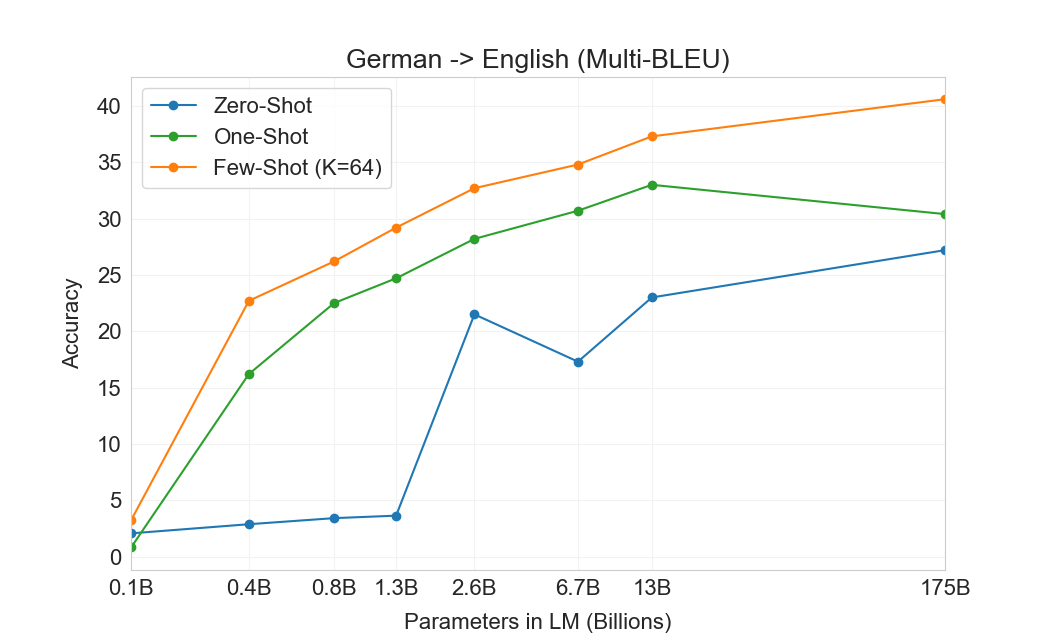 |
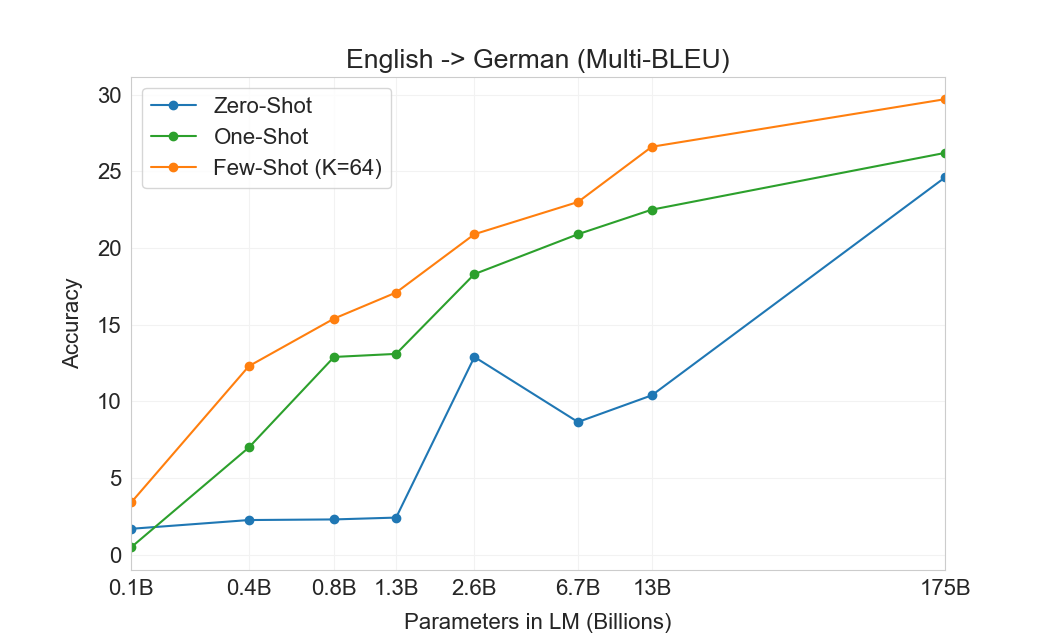 |
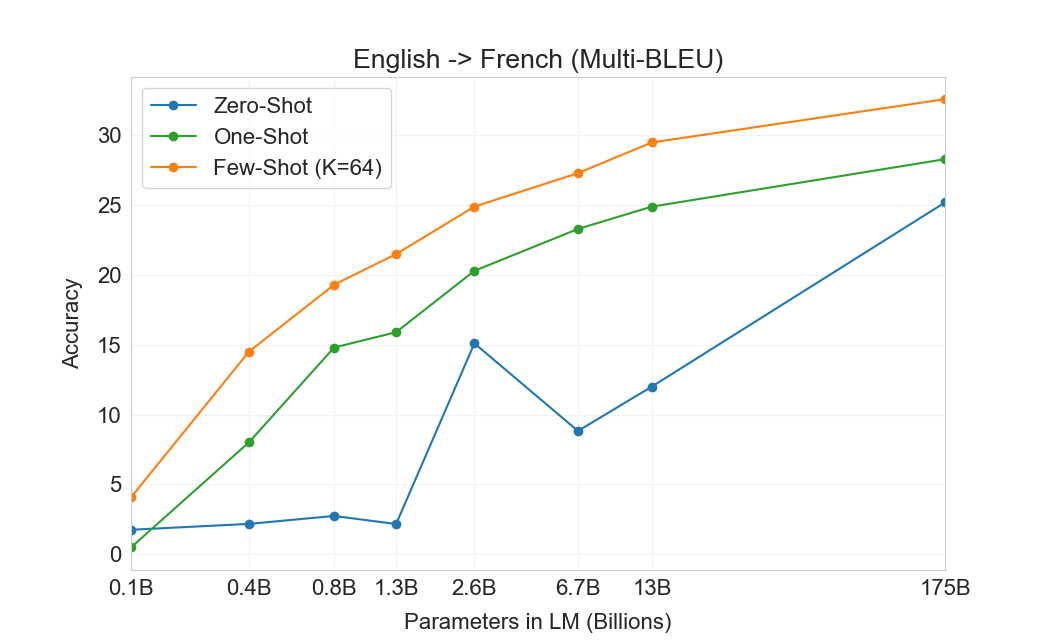 |
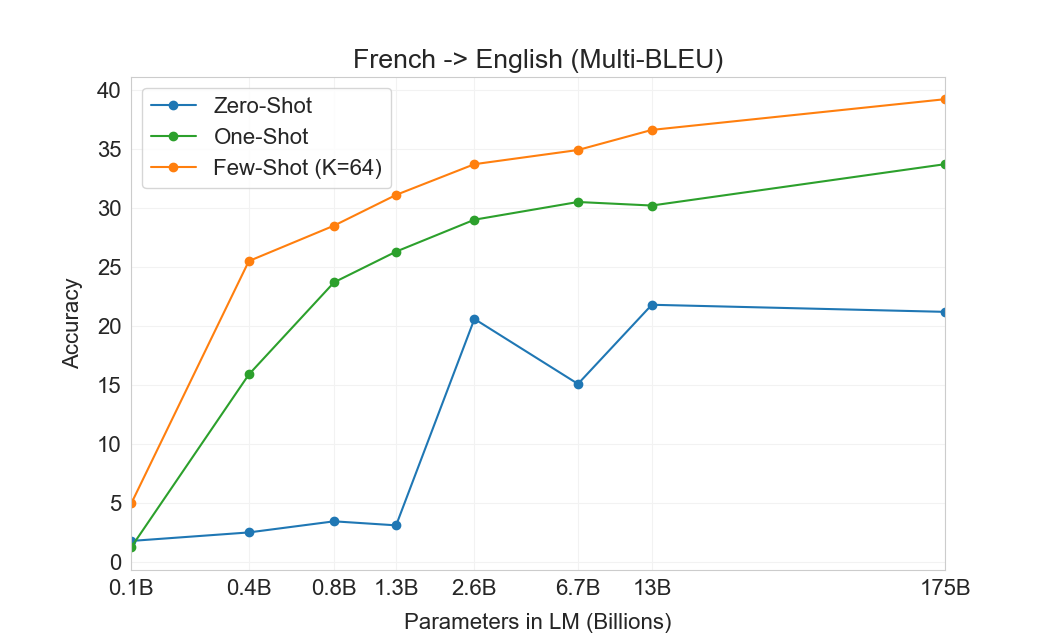 |
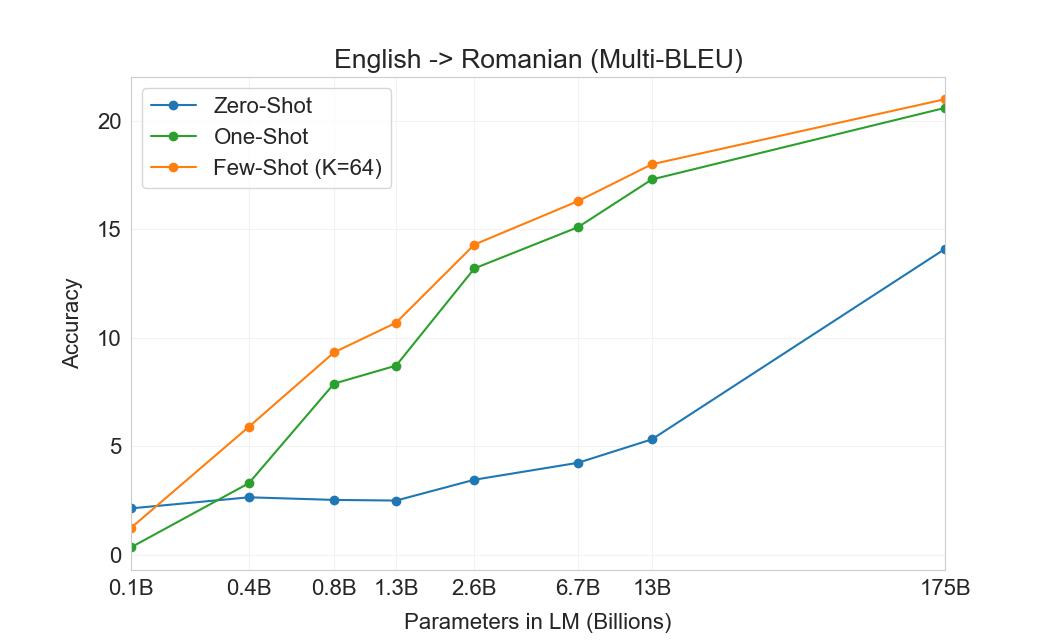 |
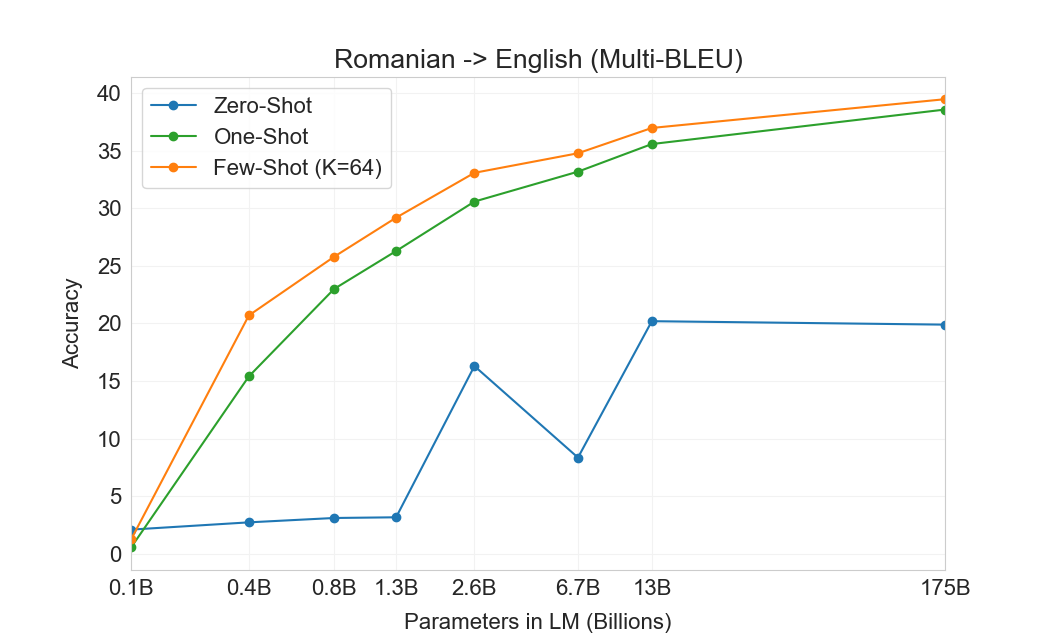 |
참고문헌
- ADG+ [16] Marcin Andrychowicz, Misha Denil, Sergio Gomez, Matthew W Hoffman, David Pfau, Tom Schaul, Brendan Shillingford, and Nando De Freitas. 경사 하강법에 의한 경사 하강법으로 학습하는 법 배우기. 에서Advances in neural information processing systems, 3981–3989쪽, 2016.
- AI [19] WeChat AI. Tr-mt (ensemble), 2019년 12월.
- AJF [19] Roee Aharoni, Melvin Johnson, and Orhan Firat. 대규모 다언어 신경 기계 번역. 에서Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 2019.
- BBDIW [20] Su Lin Blodgett, Solon Barocas, Hal Daumé III, and Hanna Wallach. 언어(기술)는 권력이다: nlp에서의 “편향”에 대한 비판적 조사. arXiv preprint arXiv:2005.14050, 2020.
- BCFL [13] Jonathan Berant, Andrew Chou, Roy Frostig, and Percy Liang. 질문-답변 쌍으로부터 freebase에 대한 의미 파싱. 에서Proceedings of the 2013 conference on empirical methods in natural language processing, 1533–1544쪽, 2013.
- BDD+ [09] Luisa Bentivogli, Ido Dagan, Hoa Trang Dang, Danilo Giampiccolo, and Bernardo Magnini. 제5회 PASCAL 텍스트 함의 인식 챌린지. 2009.
- BES [10] Stefano Baccianella, Andrea Esuli, and Fabrizio Sebastiani. Sentiwordnet 3.0: 감정 분석 및 의견 마이닝을 위한 향상된 어휘 자원. 에서Lrec, 10권, 2200–2204쪽, 2010.
- BHDD+ [06] Roy Bar Haim, Ido Dagan, Bill Dolan, Lisa Ferro, Danilo Giampiccolo, Bernardo Magnini, and Idan Szpektor. 두 번째 PASCAL 텍스트 함의 인식 챌린지. 2006.
- BHT+ [20] Yonatan Bisk, Ari Holtzman, Jesse Thomason, Jacob Andreas, Yoshua Bengio, Joyce Chai, Mirella Lapata, Angeliki Lazaridou, Jonathan May, Aleksandr Nisnevich, et al. 경험은 언어를 토대 짓는다. arXiv preprint arXiv:2004.10151, 2020.
- BLC [13] Yoshua Bengio, Nicholas Léonard, and Aaron C. Courville. 조건부 계산을 위한 확률적 뉴런을 통해 그래디언트를 추정하거나 전파하기. Arxiv, 2013.
- BZB+ [19] Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. Piqa: 자연어에서 물리적 상식에 대해 추론하기. arXiv preprint arXiv:1911.11641, 2019.
- Car [97] Rich Caruana. 멀티태스크 학습. Machine learning, 28(1), 1997.
- CB [78] Susan Carey and Elsa Bartlett. 하나의 새로운 단어 습득하기. Proceedings of the Stanford Child Language Conference, 1978.
- CCE+ [18] Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. 질문 응답을 해결했다고 생각하는가? arc, ai2 추론 챌린지를 시도해 보라. ArXiv, abs/1803.05457, 2018.
- CGRS [19] Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. 희소 transformers로 긴 시퀀스 생성하기, 2019.
- CHI+ [18] Eunsol Choi, He He, Mohit Iyyer, Mark Yatskar, Wen-tau Yih, Yejin Choi, Percy Liang, and Luke Zettlemoyer. Quac : 맥락 속 질문 응답. Arxiv, 2018.
- CLC+ [19] Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. BoolQ: 자연스러운 예/아니오 질문의 놀라운 어려움 탐구. arXiv preprint arXiv:1905.10044, 2019.
- CLY+ [19] Yen-Chun Chen, Linjie Li, Licheng Yu, Ahmed El Kholy, Faisal Ahmed, Zhe Gan, Yu Cheng, and Jingjing Liu. Uniter: 보편적 이미지-텍스트 표현 학습. arXiv preprint arXiv:1909.11740, 2019.
- Cra [17] Kate Crawford. 편향의 문제. NIPS 2017 Keynote, 2017.
- DCLT [18] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: 언어 이해를 위한 깊은 양방향 transformers의 사전 학습. arXiv preprint arXiv:1810.04805, 2018.
- DGM [06] Ido Dagan, Oren Glickman, and Bernardo Magnini. PASCAL 텍스트 함의 인식 챌린지. InMachine learning challenges. evaluating predictive uncertainty, visual object classification, and recognising textual entailment, pages 177–190. Springer, 2006.
- DGV+ [18] Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Lukasz Kaiser. Universal transformers. Arxiv, 2018.
- DHKH [14] Nadir Durrani, Barry Haddow, Philipp Koehn, and Kenneth Heafield. wmt-14를 위한 Edinburgh의 구문 기반 기계 번역 시스템. InProceedings of the Ninth Workshop on Statistical Machine Translation, pages 97–104, 2014.
- DL [15] Andrew M. Dai and Quoc V. Le. 준지도 시퀀스 학습. InAdvances in neural information processing systems, 2015.
- DMST [19] Marie-Catherine De Marneffe, Mandy Simons, and Judith Tonhauser. The CommitmentBank: 자연적으로 발생하는 담화에서 투사를 조사하기. 2019. Sinn und Bedeutung 23의 proceedings에 게재 예정. 데이터는 https://github.com/mcdm/CommitmentBank/ 에서 찾을 수 있다.
- DSC+ [16] Yan Duan, John Schulman, Xi Chen, Peter L. Bartlett, Ilya Sutskever, and Pieter Abbeel. Rl2: 느린 강화 학습을 통한 빠른 강화 학습. ArXiv, abs/1611.02779, 2016.
- DWD+ [19] Dheeru Dua, Yizhong Wang, Pradeep Dasigi, Gabriel Stanovsky, Sameer Singh, and Matt Gardner. Drop: 단락에 대한 이산 추론을 요구하는 독해 벤치마크. arXiv preprint arXiv:1903.00161, 2019.
- DYY+ [19] Zihang Dai, Zhilin Yang, Yiming Yang, Jaime G. Carbonell, Quoc V. Le, and Ruslan Salakhutdinov. Transformer-xl: 고정 길이 맥락을 넘어서는 attentive 언어 모델. Arxiv, 2019.
- EOAG [18] Sergey Edunov, Myle Ott, Michael Auli, and David Grangier. 대규모에서 back-translation 이해하기. arXiv preprint arXiv:1808.09381, 2018.
- FAL [17] Chelsea Finn, Pieter Abbeel, and Sergey Levine. 심층 네트워크의 빠른 적응을 위한 모델-불가지론적 메타 학습. ArXiv, abs/1703.03400, 2017.
- Fyo [00] Yaroslav Fyodorov. 자연 논리 추론 시스템, 2000.
- GG [19] Hila Gonen and Yoav Goldberg. 돼지에게 립스틱 바르기: 디바이어싱 방법은 단어 임베딩의 체계적 성별 편향을 가리지만 제거하지는 않는다. arXiv preprint arXiv:1903.03862, 2019.
- GLT+ [20] Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Ming-Wei Chang. Realm: 검색 증강 언어 모델 사전 학습. arXiv preprint arXiv:2002.08909, 2020.
- GMDD [07] Danilo Giampiccolo, Bernardo Magnini, Ido Dagan, and Bill Dolan. 세 번째 PASCAL 텍스트 함의 인식 챌린지. InProceedings of the ACL-PASCAL workshop on textual entailment and paraphrasing, pages 1–9. Association for Computational Linguistics, 2007.
- Gra [16] Alex Graves. 순환 신경망을 위한 적응형 계산 시간. Arxiv, 2016.
- GSL+ [18] Suchin Gururangan, Swabha Swayamdipta, Omer Levy, Roy Schwartz, Samuel R Bowman, and Noah A Smith. 자연어 추론 데이터의 주석 산물. arXiv preprint arXiv:1803.02324, 2018.
- GSR [19] Sebastian Gehrmann, Hendrik Strobelt, and Alexander M. Rush. Gltr: 생성된 텍스트의 통계적 탐지와 시각화. arXiv preprint arXiv: 1906.04043, 2019.
- GWC+ [18] Jiatao Gu, Yong Wang, Yun Chen, Kyunghyun Cho, and Victor OK Li. 저자원 신경 기계 번역을 위한 메타 학습. arXiv preprint arXiv:1808.08437, 2018.
- HB [20] Daniel Hernandez and Tom Brown. AI와 효율성, May 2020.
- HBFC [19] Ari Holtzman, Jan Buys, Maxwell Forbes, and Yejin Choi. 신경 텍스트 퇴화의 기묘한 사례. CoRR, abs/1904.09751, 2019.
- HLW+ [20] Dan Hendrycks, Xiaoyuan Liu, Eric Wallace, Adam Dziedzic, Rishabh Krishnan, and Dawn Song. 사전학습된 transformers는 out of distribution 강건성을 향상시킨다. arXiv preprint arXiv:2004.06100, 2020.
- HNA+ [17] Joel Hestness, Sharan Narang, Newsha Ardalani, Gregory Diamos, Heewoo Jun, Hassan Kianinejad, Md. Mostofa Ali Patwary, Yang Yang, and Yanqi Zhou. 딥러닝 스케일링은 경험적으로 예측 가능하다. arXiv preprint arXiv:1712.00409, 2017.
- HR [18] Jeremy Howard and Sebastian Ruder. 텍스트 분류를 위한 보편적 언어 모델 미세 조정. arXiv preprint arXiv:1801.06146, 2018.
- HVD [15] Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. 신경망의 지식을 증류하기. arXiv preprint arXiv:1503.02531, 2015.
- HYC [01] Sepp Hochreiter, A Steven Younger, and Peter R Conwell. Gradient Descent를 사용하여 학습하는 법 배우기. InInternational Conference on Artificial Neural Networks, pages 87–94. Springer, 2001.
- HZJ+ [19] Po-Sen Huang, Huan Zhang, Ray Jiang, Robert Stanforth, Johannes Welbl, Jack Rae, Vishal Maini, Dani Yogatama, and Pushmeet Kohli. 반사실적 평가를 통해 언어 모델의 감정 편향 줄이기. arXiv preprint arXiv:1911.03064, 2019.
- IBGC+ [14] Mohit Iyyer, Jordan Boyd-Graber, Leonardo Claudino, Richard Socher, and Hal Daumé III. 단락에 대한 factoid 질문 응답을 위한 신경망. InEmpirical Methods in Natural Language Processing, 2014.
- IDCBE [19] Daphne Ippolito, Daniel Duckworth, Chris Callison-Burch, and Douglas Eck. 생성된 텍스트의 자동 탐지는 인간이 속을 때 가장 쉽다. arXiv preprint arXiv:1911.00650, 2019.
- JCWZ [17] Mandar Joshi, Eunsol Choi, Daniel S. Weld, and Luke Zettlemoyer. TriviaQA: 독해를 위한 대규모 원격 지도 챌린지 데이터셋. arXiv preprint arXiv:1705.03551, 2017.
- JN [20] Zheng Junyuan and Gamma Lab NYC. Numeric transformer - albert, March 2020.
- JVS+ [16] Rafal Jozefowicz, Oriol Vinyals, Mike Schuster, Noam Shazeer, and Yonghui Wu. 언어 모델링의 한계 탐구. arXiv preprint arXiv:1602.02410, 2016.
- JYS+ [19] Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, and Qun Liu. TinyBERT: 자연어 이해를 위한 BERT 증류. arXiv preprint arXiv:1909.10351, 2019.
- JZC+ [19] Ying Ju, Fubang Zhao, Shijie Chen, Bowen Zheng, Xuefeng Yang, and Yunfeng Liu. 대화형 질문 응답에 관한 기술 보고서. arXiv preprint arXiv:1909.10772, 2019.
- KCR+ [18] Daniel Khashabi, Snigdha Chaturvedi, Michael Roth, Shyam Upadhyay, and Dan Roth. 표면 너머 보기: 여러 문장에 걸친 독해를 위한 챌린지 세트. InProceedings of North American Chapter of the Association for Computational Linguistics (NAACL), 2018.
- KKS+ [20] Daniel Khashabi, Tushar Khot, Ashish Sabharwal, Oyvind Tafjord, Peter Clark, and Hannaneh Hajishirzi. Unifiedqa: 단일 qa 시스템으로 형식 경계를 넘기. arXiv preprint arXiv:2005.00700, 2020.
- KMB [20] Sarah E. Kreps, Miles McCain, and Miles Brundage. 조작하기에 적합한 모든 뉴스: 미디어 허위정보의 도구로서의 AI 생성 텍스트, 2020.
- KMH+ [20] Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 신경 언어 모델을 위한 scaling laws, 2020.
- KPR+ [19] Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Matthew Kelcey, Jacob Devlin, Kenton Lee, Kristina N. Toutanova, Llion Jones, Ming-Wei Chang, Andrew Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. Natural questions: 질문 응답 연구를 위한 벤치마크. Transactions of the Association of Computational Linguistics, 2019.
- KR [16] Yoon Kim and Alexander M. Rush. 시퀀스 수준 knowledge distillation. Arxiv, 2016.
- LB [02] Edward Loper and Steven Bird. Nltk: The natural language toolkit, 2002.
- LC [19] Guillaume Lample and Alexis Conneau. 교차 언어 language model pretraining. arXiv preprint arXiv:1901.07291, 2019.
- LCG+ [19] Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. ALBERT: 언어 표현의 self-supervised learning을 위한 lite BERT. arXiv preprint arXiv:1909.11942, 2019.
- LCH+ [20] Xiaodong Liu, Hao Cheng, Pengcheng He, Weizhu Chen, Yu Wang, Hoifung Poon, and Jianfeng Gao. 대형 신경 언어 모델을 위한 adversarial training. arXiv preprint arXiv:2004.08994, 2020.
- LDL [19] Zhongyang Li, Xiao Ding, and Ting Liu. 전이 가능한 bert에 의한 이야기 결말 예측. arXiv preprint arXiv:1905.07504, 2019.
- LDM [12] Hector Levesque, Ernest Davis, and Leora Morgenstern. Winograd schema challenge. 에서Thirteenth International Conference on the Principles of Knowledge Representation and Reasoning, 2012.
- LGG+ [20] Yinhan Liu, Jiatao Gu, Naman Goyal, Xian Li, Sergey Edunov, Marjan Ghazvininejad, Mike Lewis, and Luke Zettlemoyer. 신경 기계 번역을 위한 multilingual denoising pre-training. arXiv preprint arXiv:2001.08210, 2020.
- LGH+ [15] Xiaodong Liu, Jianfeng Gao, Xiaodong He, Li Deng, Kevin Duh, and Ye-Yi Wang. 의미 분류와 정보 검색을 위한 multi-task deep neural networks를 사용한 representation learning. 에서Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2015.
- LH [17] Ilya Loshchilov and Frank Hutter. 분리된 weight decay regularization. arXiv preprint arXiv:1711.05101, 2017.
- [69] Xiaodong Liu, Pengcheng He, Weizhu Chen, and Jianfeng Gao. 자연어 이해를 위한 knowledge distillation을 통한 multi-task deep neural networks 개선. arXiv preprint arXiv:1904.09482, 2019.
- [70] Xiaodong Liu, Pengcheng He, Weizhu Chen, and Jianfeng Gao. 자연어 이해를 위한 multi-task deep neural networks. arXiv preprint arXiv:1901.11504, 2019.
- Lin [20] Tal Linzen. 인간과 같은 언어적 일반화를 향한 진전을 어떻게 가속할 수 있는가? arXiv preprint arXiv:2005.00955, 2020.
- LLG+ [19] Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, and Luke Zettlemoyer. Bart: 자연어 생성, 번역, 이해를 위한 Denoising sequence-to-sequence pre-training. arXiv preprint arXiv:1910.13461, 2019.
- LM [17] Ke Li and Jitendra Malik. 신경망 최적화 학습. arXiv preprint arXiv:1703.00441, 2017.
- LOG+ [19] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. RoBERTa: 견고하게 최적화된 BERT pretraining 접근법. arXiv preprint arXiv:1907.11692, 2019.
- LPP+ [20] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Kiela Douwe. 지식 집약적 nlp 작업을 위한 retrieval-augmented generation. arXiv preprint arXiv:2005.11401, 2020.
- LSP+ [18] Peter J. Liu, Mohammad Saleh, Etienne Pot, Ben Goodrich, Ryan Sepassi, Lukasz Kaiser, and Noam Shazeer. 긴 시퀀스를 요약하여 Wikipedia 생성하기. arXiv preprint arXiv:1801.10198, 2018.
- LWS+ [20] Zhuohan Li, Eric Wallace, Sheng Shen, Kevin Lin, Kurt Keutzer, Dan Klein, and Joseph E. Gonzalez. 크게 훈련한 다음 압축하라: transformers의 효율적 훈련과 추론을 위한 모델 크기 재고, 2020.
- LXL+ [17] Guokun Lai, Qizhe Xie, Hanxiao Liu, Yiming Yang, and Eduard Hovy. Race: 시험에서 나온 대규모 독해 데이터셋. arXiv preprint arXiv:1704.04683, 2017.
- LYN+ [20] Sheng-Chieh Lin, Jheng-Hong Yang, Rodrigo Nogueira, Ming-Feng Tsai, Chuan-Ju Wang, and Jimmy Lin. Tttttackling winogrande schemas. arXiv preprint arXiv:2003.08380, 2020.
- Mac [92] David. MacKay. 능동적 데이터 선택을 위한 정보 기반 목적 함수. Neural Computation, 1992.
- MBXS [17] Bryan McCann, James Bradbury, Caiming Xiong, and Richard Socher. 번역에서 학습됨: 맥락화된 단어 벡터. 에서Advances in Neural Information Processing Systems, pages 6294–6305, 2017.
- MCCD [13] Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. 벡터 공간에서 단어 표현의 효율적 추정. arXiv preprint arXiv:1301.3781, 2013.
- MCH+ [16] Nasrin Mostafazadeh, Nathanael Chambers, Xiaodong He, Devi Parikh, Dhruv Batra, Lucy Vanderwende, Pushmeet Kohli, and James Allen. 상식 이야기의 더 깊은 이해를 위한 코퍼스와 평가 프레임워크. arXiv preprint arXiv:1604.01696, 2016.
- MCKS [18] Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. 갑옷 한 벌이 전기를 전도할 수 있는가? open book question answering을 위한 새로운 데이터셋. ArXiv, abs/1809.02789, 2018.
- MKAT [18] Sam McCandlish, Jared Kaplan, Dario Amodei, and OpenAI Dota Team. 대규모 배치 훈련의 경험적 모델, 2018.
- MKM+ [94] Mitchell Marcus, Grace Kim, Mary Ann Marcinkiewicz, Robert MacIntyre, Ann Bies, Mark Ferguson, Karen Katz, and Britta Schasberger. The penn treebank: predicate argument structure 주석 달기. 에서Proceedings of the workshop on Human Language Technology, pages 114–119. Association for Computational Linguistics, 1994.
- MKXS [18] Bryan McCann, Nitish Shirish Keskar, Caiming Xiong, and Richard Socher. The natural language decathlon: 질문 응답으로서의 multitask learning. arXiv preprint arXiv:1806.08730, 2018.
- MPL [19] R Thomas McCoy, Ellie Pavlick, and Tal Linzen. 잘못된 이유로 맞음: 자연어 추론에서 syntactic heuristics 진단. arXiv preprint arXiv:1902.01007, 2019.
- MWZ+ [18] Margaret Mitchell, Simone Wu, Andrew Zaldivar, Parker Barnes, Lucy Vasserman, Ben Hutchinson, Elena Spitzer, Inioluwa Deborah Raji, and Timnit Gebru. 모델 보고를 위한 model cards, 2018.
- NBR [20] Moin Nadeem, Anna Bethke, and Siva Reddy. Stereoset: 사전훈련된 언어 모델에서 고정관념적 편향 측정. arXiv preprint arXiv:2004.09456, 2020.
- NK [19] Timothy Niven and Hung-Yu Kao. 자연어 논증에 대한 신경망 이해 탐색. arXiv preprint arXiv:1907.07355, 2019.
- Nor [09] Peter Norvig. 자연어 코퍼스 데이터, 2009.
- NvNvdG [19] Malvina Nissim, Rik van Noord, and Rob van der Goot. 공정한 것이 선정적인 것보다 낫다: 남자가 doctor인 것처럼 여자는 doctor이다. arXiv preprint arXiv:1905.09866, 2019.
- NWD+ [19] Yixin Nie, Adina Williams, Emily Dinan, Mohit Bansal, Jason Weston, and Douwe Kiela. Adversarial nli: 자연어 이해를 위한 새로운 벤치마크. arXiv preprint arXiv:1910.14599, 2019.
- oR [16] University of Regensburg. Fascha, 2016.
- PCC [18] Mohammad Taher Pilehvar and Jose Camacho-Collados. WIC: 맥락 민감 표현을 평가하기 위한 10,000개의 예시 쌍. arXiv preprint arXiv:1808.09121, 2018.
- PFB [18] Jason Phang, Thibault Févry, and Samuel R. Bowman. STILTs 위의 sentence encoders: 중간 라벨 데이터 작업에 대한 보충 훈련. arXiv preprint arXiv:1811.01088, 2018.
- PHR+ [18] Adam Poliak, Aparajita Haldar, Rachel Rudinger, J. Edward Hu, Ellie Pavlick, Aaron Steven White, and Benjamin Van Durme. 문장 표현 평가를 위한 다양한 자연어 추론 문제 수집. 에서Proceedings of EMNLP, 2018.
- PKL+ [16] Denis Paperno, Germán Kruszewski, Angeliki Lazaridou, Quan Ngoc Pham, Raffaella Bernardi, Sandro Pezzelle, Marco Baroni, Gemma Boleda, and Raquel Fernández. The lambada dataset: 넓은 담화 맥락을 필요로 하는 단어 예측. arXiv preprint arXiv:1606.06031, 2016.
- PNZtY [18] Matthew E. Peters, Mark Neumann, Luke Zettlemoyer, and Wen tau Yih. 맥락적 단어 임베딩 해부: 아키텍처와 표현, 2018.
- Pos [18] Matt Post. BLEU 점수 보고에서 명확성을 요구하는 제안. arXiv preprint arXiv:1804.08771, 2018.
- PSM [14] Jeffrey Pennington, Richard Socher, and Christopher Manning. GloVe: 단어 표현을 위한 전역 벡터. 에서Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), 2014.
- QIA [20] QIANXIN. albert 위의 Sa-net (ensemble), April 2020.
- QMZH [19] Yusu Qian, Urwa Muaz, Ben Zhang, and Jae Won Hyun. gender-equalizing loss function을 사용하여 단어 수준 언어 모델에서 성별 편향 줄이기. arXiv preprint arXiv:1905.12801, 2019.
- RBG [11] Melissa Roemmele, Cosmin Adrian Bejan, and Andrew S Gordon. Choice of plausible alternatives: 상식적 인과 추론의 평가. 에서2011 AAAI Spring Symposium Series, 2011.
- RCM [19] Siva Reddy, Danqi Chen, and Christopher D Manning. Coqa: 대화형 질문 답변 과제. Transactions of the Association for Computational Linguistics, 7:249–266, 2019.
- RCP+ [17] Scott Reed, Yutian Chen, Thomas Paine, Aäron van den Oord, SM Eslami, Danilo Rezende, Oriol Vinyals, and Nando de Freitas. Few-shot 자기회귀 밀도 추정: 분포를 학습하는 법을 학습하는 것을 향하여. arXiv preprint arXiv:1710.10304, 2017.
- RJL [18] Pranav Rajpurkar, Robin Jia, and Percy Liang. 당신이 모르는 것을 알라: squad를 위한 답변 불가능한 질문. arXiv preprint arXiv:1806.03822, 2018.
- RL [16] Sachin Ravi and Hugo Larochelle. few-shot learning을 위한 모델로서의 최적화. ICLR 2017 (oral), 2016.
- RLL+ [19] Qiu Ran, Yankai Lin, Peng Li, Jie Zhou, and Zhiyuan Liu. NumNet: 수치 추론을 갖춘 기계 독해. 에서Proceedings of EMNLP, 2019.
- RNLVD [18] Rachel Rudinger, Jason Naradowsky, Brian Leonard, and Benjamin Van Durme. 상호참조 해결에서의 성별 편향. arXiv preprint arXiv:1804.09301, 2018.
- RNSS [18] Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 생성적 사전 훈련으로 언어 이해 개선, 2018.
- Ros [12] R.S. Ross. 위험 평가 수행을 위한 안내서. NIST Special Publication, 2012.
- RRBS [19] Jonathan S. Rosenfeld, Amir Rosenfeld, Yonatan Belinkov, and Nir Shavit. 스케일 전반의 일반화 오차에 대한 구성적 예측, 2019.
- RRS [20] Adam Roberts, Colin Raffel, and Noam Shazeer. 언어 모델의 매개변수 안에 얼마나 많은 지식을 담을 수 있는가? arXiv preprint arXiv:2002.08910, 2020.
- RSR+ [19] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 통합된 text-to-text transformer로 전이 학습의 한계를 탐구하기, 2019.
- RWC+ [19] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 언어 모델은 비지도 multitask 학습자이다, 2019.
- SBBC [19] Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: 대규모 adversarial winograd schema 과제, 2019.
- SBC+ [19] Irene Solaiman, Miles Brundage, Jack Clark, Amanda Askell, Ariel Herbert-Voss, Jeff Wu, Alec Radford, Gretchen Krueger, Jong Wook Kim, Sarah Kreps, Miles McCain, Alex Newhouse, Jason Blazakis, Kris McGuffie, and Jasmine Wang. 언어 모델의 공개 전략과 사회적 영향, 2019.
- SCNP [19] Emily Sheng, Kai-Wei Chang, Premkumar Natarajan, and Nanyun Peng. 그 여성은 babysitter로 일했다: 언어 생성에서의 편향에 관하여. arXiv preprint arXiv:1909.01326, 2019.
- SDCW [19] Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. DistilBERT, BERT의 distill된 버전: 더 작고, 더 빠르고, 더 저렴하고 더 가볍다. arXiv preprint arXiv:1910.01108, 2019.
- SDSE [19] Roy Schwartz, Jesse Dodge, Noah A. Smith, and Oren Etzioni. Green AI. CoRR, abs/1907.10597, 2019.
- SHB [15] Rico Sennrich, Barry Haddow, and Alexandra Birch. 단일언어 데이터로 신경망 기계 번역 모델 개선. arXiv preprint arXiv:1511.06709, 2015.
- SMM+ [17] Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. 터무니없이 큰 신경망: sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538, 2017.
- SPP+ [19] Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-lm: model parallelism을 사용한 수십억 매개변수 언어 모델 훈련, 2019.
- SS [20] Timo Schick and Hinrich Schütze. few-shot 텍스트 분류와 자연어 추론을 위해 cloze questions 활용. arXiv preprint arXiv:2001.07676, 2020.
- STQ+ [19] Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, and Tie-Yan Liu. MASS: 언어 생성을 위한 masked sequence to sequence pre-training. arXiv preprint arXiv:1905.02450, 2019.
- TFR+ [17] Josh Tobin, Rachel Fong, Alex Ray, Jonas Schneider, Wojciech Zaremba, and Pieter Abbeel. 시뮬레이션에서 현실 세계로 심층 신경망을 전이하기 위한 domain randomization. 에서2017 IEEE/RSJ international conference on intelligent robots and systems (IROS), pages 23–30. IEEE, 2017.
- TL [05] Peter D. Turney and Michael L. Littman. 말뭉치 기반의 유추와 의미 관계 학습. CoRR, abs/cs/0508103, 2005.
- TL [18] Trieu H. Trinh and Quoc V. Le. 상식 추론을 위한 간단한 방법. arXiv preprint arXiv:1806.02847, 2018.
- TLBS [03] Peter D. Turney, Michael L. Littman, Jeffrey Bigham, and Victor Shnayder. 객관식 동의어와 유추 문제를 해결하기 위해 독립적인 모듈 결합. CoRR, cs.CL/0309035, 2003.
- Tur [20] Project Turing. Microsoft research blog, Feb 2020.
- VBL+ [16] Oriol Vinyals, Charles Blundell, Timothy Lillicrap, Daan Wierstra, et al. One Shot Learning을 위한 Matching Networks. 에서Advances in neural information processing systems, pages 3630–3638, 2016.
- VSP+ [17] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. 에서Advances in neural information processing systems, 2017.
- WPN+ [19] Alex Wang, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. Superglue: 범용 언어 이해 시스템을 위한 더 까다로운 벤치마크. 에서Advances in Neural Information Processing Systems, pages 3261–3275, 2019.
- WXH+ [18] Yiren Wang, Yingce Xia, Tianyu He, Fei Tian, Tao Qin, ChengXiang Zhai, and Tie-Yan Liu. Multi-agent dual learning. ICLR 2019, 2018.
- XDH+ [19] Qizhe Xie, Zihang Dai, Eduard Hovy, Minh-Thang Luong, and Quoc V. Le. 일관성 훈련을 위한 비지도 데이터 증강, 2019.
- YdC+ [19] Dani Yogatama, Cyprien de Masson d’Autume, Jerome Connor, Tomas Kocisky, Mike Chrzanowski, Lingpeng Kong, Angeliki Lazaridou, Wang Ling, Lei Yu, Chris Dyer, et al. 일반 언어 지능의 학습과 평가. arXiv preprint arXiv:1901.11373, 2019.
- YDY+ [19] Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, and Quoc V. Le. XLNet: 언어 이해를 위한 generalized autoregressive pretraining. arXiv preprint arXiv:1906.08237, 2019.
- ZHB+ [19] Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: 기계가 정말로 당신의 문장을 끝낼 수 있는가? arXiv preprint arXiv:1905.07830, 2019.
- ZHR+ [19] Rowan Zellers, Ari Holtzman, Hannah Rashkin, Yonatan Bisk, Ali Farhadi, Franziska Roesner, and Yejin Choi. 신경망 가짜 뉴스에 대한 방어. arXiv preprint arXiv:1905.12616, 2019.
- ZLL+ [18] Sheng Zhang, Xiaodong Liu, Jingjing Liu, Jianfeng Gao, Kevin Duh, and Benjamin Van Durme. ReCoRD: 인간과 기계의 상식 독해 사이의 격차를 잇기. arXiv preprint arXiv:1810.12885, 2018.
- [143] Daniel M. Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B. Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. 인간 선호로부터 언어 모델 fine-tuning, 2019.
- [144] Daniel M. Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B. Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. 인간 선호로부터 언어 모델 fine-tuning. ArXiv, abs/1909.08593, 2019.