적절한 출처 표시가 제공되는 경우, Google은 본 논문의 표와 그림을 저널리즘 또는 학술 저작물에서 사용하는 목적으로만 복제할 수 있는 허가를 이에 부여합니다.
Attention Is All You Need
초록
지배적인 sequence transduction 모델들은 encoder와 decoder를 포함하는 복잡한 recurrent 또는 convolutional neural networks에 기반한다. 가장 성능이 좋은 모델들은 또한 attention mechanism을 통해 encoder와 decoder를 연결한다. 우리는 오직 attention mechanisms에만 기반하며 recurrence와 convolutions를 완전히 없앤 새로운 단순한 네트워크 아키텍처인 Transformer를 제안한다. 두 기계 번역 과제에 대한 실험은 이 모델들이 더 병렬화 가능하고 훈련에 훨씬 적은 시간이 필요하면서도 품질 면에서 우수함을 보여준다. 우리의 모델은 WMT 2014 English-to-German translation task에서 28.4 BLEU를 달성하여, ensembles를 포함한 기존 최고 결과를 2 BLEU 이상 개선한다. WMT 2014 English-to-French translation task에서, 우리의 모델은 문헌상의 최고 모델들의 훈련 비용의 작은 일부인 8개 GPU에서 3.5일 동안 훈련한 후 41.8의 새로운 single-model state-of-the-art BLEU score를 수립한다. 우리는 Transformer를 대규모 및 제한된 훈련 데이터 모두에서 English constituency parsing에 성공적으로 적용함으로써 다른 과제에도 잘 일반화됨을 보인다.
1 서론
Recurrent neural networks, long short-term memory[13]및 gated recurrent[7]neural networks는 특히 language modeling과 machine translation 같은 sequence modeling 및 transduction 문제에서 state of the art 접근법으로 확고히 자리 잡았다[35, 2, 5]. 그 이후 수많은 노력들이 recurrent language models와 encoder-decoder architectures의 경계를 계속 넓혀 왔다[38, 24, 15].
Recurrent models는 일반적으로 입력 및 출력 시퀀스의 symbol positions를 따라 계산을 분해한다. 위치를 계산 시간의 step에 정렬하여, 이들은 hidden states의 시퀀스를 생성한다, 이전 hidden state의 함수로서그리고 position에 대한 input. 이러한 본질적으로 순차적인 성질은 훈련 예제 내부의 병렬화를 불가능하게 하며, 메모리 제약이 예제 간 batching을 제한하기 때문에 더 긴 시퀀스 길이에서 중요해진다. 최근 연구는 factorization tricks를 통해 계산 효율에서 상당한 개선을 달성했다[21]및 conditional computation[32], 후자의 경우 모델 성능도 개선하면서. 그러나 sequential computation의 근본적인 제약은 남아 있다.
Attention mechanisms는 다양한 과제에서 강력한 sequence modeling 및 transduction models의 필수적인 부분이 되었으며, 입력 또는 출력 시퀀스에서의 거리에 관계없이 dependencies의 모델링을 가능하게 한다[2, 19]. 몇몇 경우를 제외한 거의 모든 경우에[27], 그러나 이러한 attention mechanisms는 recurrent network와 함께 사용된다.
이 작업에서 우리는 recurrence를 피하고 대신 input과 output 사이의 global dependencies를 도출하기 위해 전적으로 attention mechanism에 의존하는 모델 아키텍처인 Transformer를 제안한다. Transformer는 훨씬 더 많은 병렬화를 가능하게 하며, 8개의 P100 GPUs에서 불과 12시간 정도 훈련된 후 번역 품질에서 새로운 state of the art에 도달할 수 있다.
2 배경
sequential computation을 줄이는 목표는 또한 Extended Neural GPU의 토대를 이룬다[16], ByteNet[18]및 ConvS2S[9], 이들 모두는 convolutional neural networks를 기본 building block으로 사용하여 모든 입력 및 출력 위치에 대해 hidden representations를 병렬로 계산한다. 이러한 모델들에서 두 임의의 입력 또는 출력 위치의 신호를 연관시키는 데 필요한 연산 수는 위치 간 거리에 따라 증가하며, ConvS2S에서는 선형적으로, ByteNet에서는 로그적으로 증가한다. 이는 먼 위치들 사이의 dependencies를 학습하는 것을 더 어렵게 만든다[12]. Transformer에서는 이것이 상수 개수의 연산으로 줄어들지만, attention-weighted positions를 평균화함으로써 effective resolution이 감소하는 비용이 있으며, 우리는 section에서 설명하는 Multi-Head Attention으로 이 효과에 대응한다3.2.
Self-attention은 때때로 intra-attention이라고 불리며, 시퀀스의 표현을 계산하기 위해 단일 시퀀스의 서로 다른 위치들을 연관시키는 attention mechanism이다. Self-attention은 reading comprehension, abstractive summarization, textual entailment 및 task-independent sentence representations 학습을 포함한 다양한 과제에서 성공적으로 사용되어 왔다[4, 27, 28, 22].
End-to-end memory networks는 sequence-aligned recurrence 대신 recurrent attention mechanism에 기반하며 simple-language question answering 및 language modeling tasks에서 잘 수행되는 것으로 나타났다[34].
3 모델 아키텍처

대부분의 경쟁력 있는 neural sequence transduction models는 encoder-decoder 구조를 가진다[5, 2, 35]. 여기서 encoder는 symbol representations의 입력 시퀀스를 매핑한다continuous representations의 시퀀스로. 주어지면, decoder는 그런 다음 출력 시퀀스를 생성한다symbols를 한 번에 한 요소씩. 각 step에서 모델은 auto-regressive이다[10], 다음 것을 생성할 때 이전에 생성된 symbols를 추가 입력으로 소비한다.
Transformer는 encoder와 decoder 모두에 대해 stacked self-attention과 point-wise, fully connected layers를 사용하여 이 전반적인 아키텍처를 따르며, Figure의 왼쪽과 오른쪽 절반에 각각 표시되어 있다1, 각각.
3.1 Encoder 및 Decoder Stacks
Encoder:
encoder는 다음의 stack으로 구성된다동일한 layers. 각 layer는 두 개의 sub-layers를 가진다. 첫 번째는 multi-head self-attention mechanism이고, 두 번째는 단순한 position-wise fully connected feed-forward network이다. 우리는 residual connection을 사용한다[11]두 sub-layers 각각의 주위에, 이어서 layer normalization[1]. 즉, 각 sub-layer의 출력은, 여기서sub-layer 자체가 구현한 함수이다. 이러한 residual connections를 용이하게 하기 위해, 모델의 모든 sub-layers와 embedding layers는 차원이 다음인 출력을 생성한다.
Decoder:
decoder도 또한 다음의 stack으로 구성된다동일한 layers. 각 encoder layer의 두 sub-layers에 더하여, decoder는 encoder stack의 출력에 대해 multi-head attention을 수행하는 세 번째 sub-layer를 삽입한다. encoder와 유사하게, 우리는 각 sub-layer 주위에 residual connections를 사용하고, 이어서 layer normalization을 수행한다. 또한 decoder stack의 self-attention sub-layer를 수정하여 positions가 후속 positions에 attend하지 못하게 한다. 이 masking은 output embeddings가 한 position만큼 offset된 사실과 결합되어 position에 대한 predictions가 보장한다다음보다 작은 positions의 알려진 outputs에만 의존할 수 있다.
3.2 Attention
attention function은 query와 key-value pairs의 집합을 output으로 매핑하는 것으로 설명될 수 있으며, 여기서 query, keys, values, output은 모두 vectors이다. output은 values의 weighted sum으로 계산되며, 각 value에 할당되는 weight는 query와 해당 key의 compatibility function에 의해 계산된다.
3.2.1 Scaled Dot-Product Attention
우리는 우리의 특정 attention을 "Scaled Dot-Product Attention"이라고 부른다 (Figure2). input은 차원이 다음인 queries와 keys로 구성된다, 그리고 차원이 다음인 values. 우리는 query와 모든 keys의 dot products를 계산하고, 각각을 다음으로 나눈다, 그리고 values에 대한 weights를 얻기 위해 softmax function을 적용한다.
실제로는, 우리는 query들의 집합에 대해 attention function을 동시에 계산하며, 이를 matrix로 함께 묶는다. keys와 values도 또한 matrices로 함께 묶인다및. 우리는 outputs의 matrix를 다음과 같이 계산한다:
| (1) |
가장 흔히 사용되는 두 attention functions는 additive attention이다[2], 그리고 dot-product (multiplicative) attention. Dot-product attention은 다음의 scaling factor를 제외하고 우리의 알고리즘과 동일하다. Additive attention은 single hidden layer를 가진 feed-forward network를 사용하여 compatibility function을 계산한다. 둘은 이론적 복잡도에서는 유사하지만, dot-product attention은 고도로 최적화된 matrix multiplication code를 사용하여 구현될 수 있으므로 실제로는 훨씬 빠르고 공간 효율적이다.
다음의 작은 값들에 대해서는두 mechanisms가 유사하게 수행되지만, 더 큰 값의 경우 additive attention은 scaling 없는 dot product attention보다 성능이 더 좋다 [3]. 우리는 다음의 큰 값들에 대해 추측한다, dot products가 크기에서 커져 softmax function을 극히 작은 gradients를 갖는 영역으로 밀어 넣는다111dot products가 왜 커지는지 설명하기 위해, 다음의 components가및평균이 다음인 독립 random variables라고 가정하자그리고 분산. 그러면 이들의 dot product,, 는 평균을 가진다그리고 분산.. 이 효과에 대응하기 위해, 우리는 dot products를 다음으로 scale한다.
3.2.2 Multi-Head Attention
Scaled Dot-Product Attention

Multi-Head Attention

단일 attention function을 수행하는 대신-dimensional keys, values 및 queries로, 우리는 queries, keys 및 values를 선형적으로 projection하는 것이 유익함을 발견했다서로 다른, 학습된 linear projections로 다음에 대해 여러 번, 및차원으로, 각각. 이러한 projected versions의 queries, keys 및 values 각각에 대해 우리는 attention function을 병렬로 수행하여 다음을 산출한다-dimensional output values. 이들은 concatenate되고 다시 한 번 projection되어 최종 values가 되며, Figure에 묘사된 바와 같다2.
Multi-head attention은 모델이 서로 다른 positions에서 서로 다른 representation subspaces의 정보에 공동으로 attend할 수 있게 한다. 단일 attention head에서는 averaging이 이를 억제한다.
여기서 projections는 parameter matrices이다, , 및.
이 작업에서 우리는 다음을 사용한다parallel attention layers, 또는 heads. 이들 각각에 대해 우리는 다음을 사용한다. 각 head의 차원이 줄어들었기 때문에, 총 계산 비용은 full dimensionality를 가진 single-head attention의 비용과 유사하다.
3.2.3 우리 모델에서 Attention의 적용
Transformer는 multi-head attention을 세 가지 서로 다른 방식으로 사용한다:
- •
-
•
encoder는 self-attention layers를 포함한다. self-attention layer에서는 모든 keys, values 및 queries가 같은 곳, 이 경우 encoder의 이전 layer의 출력에서 온다. encoder의 각 position은 encoder의 이전 layer의 모든 positions에 attend할 수 있다.
-
•
유사하게, decoder의 self-attention layers는 decoder의 각 position이 그 position까지 그리고 그 position을 포함한 decoder의 모든 positions에 attend할 수 있게 한다. 우리는 auto-regressive property를 보존하기 위해 decoder에서 leftward information flow를 방지해야 한다. 우리는 illegal connections에 해당하는 softmax의 input에 있는 모든 values를 masking out(다음으로 설정)함으로써 scaled dot-product attention 내부에서 이를 구현한다) 모든 values를 softmax의 input에서 illegal connections에 해당하는 것들. Figure를 보라2.
3.3 Position-wise Feed-Forward Networks
attention sub-layers에 더하여, 우리의 encoder와 decoder의 각 layer는 fully connected feed-forward network를 포함하며, 이는 각 position에 대해 개별적으로 그리고 동일하게 적용된다. 이는 사이에 ReLU activation이 있는 두 linear transformations로 구성된다.
| (2) |
linear transformations는 서로 다른 positions에 걸쳐 동일하지만, layer마다 서로 다른 parameters를 사용한다. 이를 설명하는 또 다른 방식은 kernel size 1을 가진 두 convolutions로 보는 것이다. input과 output의 dimensionality는, 그리고 inner-layer는 dimensionality를 가진다.
3.4 Embeddings and Softmax
다른 sequence transduction models와 유사하게, 우리는 learned embeddings를 사용하여 input tokens와 output tokens를 차원이 다음인 vectors로 변환한다. 또한 decoder output을 predicted next-token probabilities로 변환하기 위해 일반적인 learned linear transformation과 softmax function을 사용한다. 우리 모델에서는 두 embedding layers와 pre-softmax linear transformation 사이에 동일한 weight matrix를 공유하며, 다음과 유사하다[30]. embedding layers에서, 우리는 그 weights에 다음을 곱한다.
3.5 Positional Encoding
우리 모델은 recurrence도 convolution도 포함하지 않기 때문에, 모델이 sequence의 순서를 활용할 수 있도록 sequence 내 tokens의 상대적 또는 절대적 위치에 대한 어떤 정보를 주입해야 한다. 이를 위해, 우리는 encoder와 decoder stacks의 바닥에서 input embeddings에 "positional encodings"를 더한다. positional encodings는 동일한 dimension을 가진다embeddings와 같아서, 둘을 더할 수 있다. positional encodings에는 learned와 fixed를 포함하여 많은 선택지가 있다[9].
이 작업에서, 우리는 서로 다른 frequencies의 sine 및 cosine functions를 사용한다:
여기서position이고dimension이다. 즉, positional encoding의 각 dimension은 sinusoid에 해당한다. wavelengths는 다음부터 기하수열을 이룬다다음까지. 우리는 이 function을 선택했는데, 이는 임의의 고정된 offset에 대해 모델이 relative positions로 attend하는 것을 쉽게 학습할 수 있게 할 것이라고 가정했기 때문이다, 다음의 linear function으로 표현될 수 있다.
4 왜 Self-Attention인가
이 절에서 우리는 self-attention layers의 다양한 측면을, symbol representations의 variable-length sequence 하나를 매핑하는 데 흔히 사용되는 recurrent 및 convolutional layers와 비교한다동일한 길이의 또 다른 sequence로, 다음과 함께, 전형적인 sequence transduction encoder 또는 decoder의 hidden layer와 같은. 우리의 self-attention 사용에 동기를 부여하며 우리는 세 가지 desiderata를 고려한다.
하나는 layer당 총 computational complexity이다. 또 다른 하나는 병렬화될 수 있는 계산의 양으로, 필요한 sequential operations의 최소 개수로 측정된다.
세 번째는 네트워크에서 long-range dependencies 사이의 path length이다. long-range dependencies를 학습하는 것은 많은 sequence transduction tasks에서 핵심 과제이다. 그러한 dependencies를 학습하는 능력에 영향을 미치는 한 핵심 요인은 forward 및 backward signals가 네트워크에서 지나가야 하는 paths의 길이이다. input 및 output sequences의 positions의 어떤 조합 사이에서도 이러한 paths가 짧을수록, long-range dependencies를 학습하기가 더 쉽다[12]. 따라서 우리는 서로 다른 layer types로 구성된 networks에서 임의의 두 input 및 output positions 사이의 maximum path length도 비교한다.
| Layer Type | Layer당 Complexity | Sequential | Maximum Path Length |
|---|---|---|---|
| Operations | |||
| Self-Attention | |||
| Recurrent | |||
| Convolutional | |||
| Self-Attention (restricted) |
Table에서 언급한 바와 같이1, self-attention layer는 모든 positions를 상수 개수의 sequentially executed operations로 연결하는 반면, recurrent layer는 다음을 필요로 한다sequential operations. computational complexity 측면에서, sequence length가 다음일 때 self-attention layers는 recurrent layers보다 빠르다representation dimensionality보다 작다, 이는 word-piece와 같은 machine translations의 state-of-the-art models에서 사용되는 sentence representations에서 가장 자주 해당된다[38]및 byte-pair[31]representations. 매우 긴 sequences를 포함하는 tasks에서 computational performance를 개선하기 위해, self-attention은 각각의 output position을 중심으로 input sequence에서 size가 다음인 neighborhood만 고려하도록 제한될 수 있다이는 maximum path length를 다음으로 증가시킬 것이다. 우리는 향후 연구에서 이 접근법을 더 조사할 계획이다.
kernel width가 다음인 단일 convolutional layer는input 및 output positions의 모든 쌍을 연결하지 않는다. 그렇게 하려면 contiguous kernels의 경우 다음의 stack이 필요하다convolutional layers, 또는dilated convolutions의 경우[18], 이는 네트워크에서 임의의 두 positions 사이의 longest paths의 길이를 증가시킨다. Convolutional layers는 일반적으로 recurrent layers보다 다음의 factor만큼 더 비싸다. Separable convolutions[6], 그러나 complexity를 상당히 줄여 다음으로 만든다. 다음의 경우에도, 그러나 separable convolution의 complexity는 self-attention layer와 point-wise feed-forward layer의 조합, 즉 우리 모델에서 취하는 접근법과 같다.
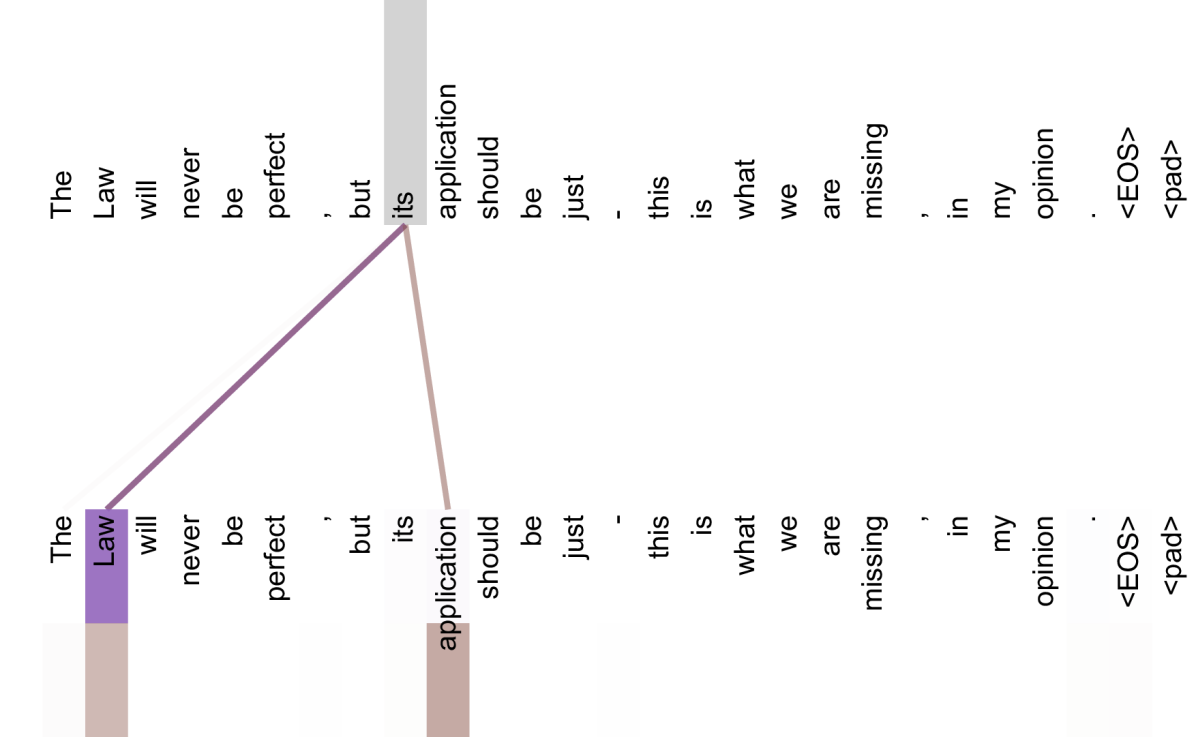
부수적인 이점으로, self-attention은 더 해석 가능한 모델을 산출할 수 있다. 우리는 우리 모델들의 attention distributions를 조사하고 appendix에서 예시를 제시하고 논의한다. 개별 attention heads가 서로 다른 tasks를 수행하는 것을 명확히 학습할 뿐만 아니라, 많은 head들이 문장의 syntactic 및 semantic structure와 관련된 behavior를 보이는 것처럼 보인다.
5 Training
이 절은 우리 모델들의 training regime을 설명한다.
5.1 Training Data and Batching
우리는 약 4.5 million개의 문장 쌍으로 구성된 표준 WMT 2014 English-German dataset에서 학습했다. 문장은 byte-pair encoding을 사용하여 인코딩되었다[3], 이는 약 37000 tokens의 공유 source-target vocabulary를 가진다. English-French의 경우, 우리는 36M sentences로 구성된 훨씬 더 큰 WMT 2014 English-French dataset을 사용했고 tokens를 32000 word-piece vocabulary로 분할했다[38]. 문장 쌍들은 대략적인 sequence length에 따라 함께 batch되었다. 각 training batch는 대략 25000 source tokens와 25000 target tokens를 포함하는 문장 쌍들의 집합을 포함했다.
5.2 하드웨어와 스케줄
우리는 8 NVIDIA P100 GPUs가 있는 한 대의 머신에서 우리의 models를 학습했다. 논문 전반에 설명된 hyperparameters를 사용하는 우리의 base models의 경우, 각 training step은 약 0.4 seconds가 걸렸다. 우리는 base models를 총 100,000 steps 또는 12 hours 동안 학습했다. 우리의 big models의 경우,(표의 맨 아래 줄에 설명됨3), step time은 1.0 seconds였다. big models는 300,000 steps (3.5 days) 동안 학습되었다.
5.3 Optimizer
우리는 Adam optimizer를 사용했다[20]와 함께, 그리고. 우리는 다음 formula에 따라 학습 과정 동안 learning rate를 변화시켰다:
| (3) |
이는 처음training steps 동안 learning rate를 선형적으로 증가시키고, 그 이후에는 step number의 inverse square root에 비례하여 감소시키는 것에 해당한다. 우리는 사용했다.
5.4 Regularization
우리는 학습 동안 세 가지 유형의 regularization을 사용한다:
Residual Dropout
우리는 dropout을 적용한다[33]각 sub-layer의 출력에, 그것이 sub-layer input에 더해지고 normalized되기 전에. 또한, 우리는 encoder와 decoder stacks 모두에서 embeddings와 positional encodings의 합에 dropout을 적용한다. base model의 경우, 우리는 rate를 사용한다.
Label Smoothing
학습 동안, 우리는 값의 label smoothing을 사용했다 [36]. 이는 model이 더 불확실해지는 것을 학습하므로 perplexity에는 해롭지만, accuracy와 BLEU score를 향상시킨다.
6 결과
6.1 기계 번역
| Model | BLEU | Training Cost (FLOPs) | |||
|---|---|---|---|---|---|
| EN-DE | EN-FR | EN-DE | EN-FR | ||
| ByteNet[18] | 23.75 | ||||
| Deep-Att + PosUnk[39] | 39.2 | ||||
| GNMT + RL[38] | 24.6 | 39.92 | |||
| ConvS2S[9] | 25.16 | 40.46 | |||
| MoE[32] | 26.03 | 40.56 | |||
| Deep-Att + PosUnk Ensemble[39] | 40.4 | ||||
| GNMT + RL Ensemble[38] | 26.30 | 41.16 | |||
| ConvS2S Ensemble[9] | 26.36 | 41.29 | |||
| Transformer (base model) | 27.3 | 38.1 | |||
| Transformer (big) | 28.4 | 41.8 | |||
WMT 2014 English-to-German translation task에서, big transformer model(Table의 Transformer (big)2)은 이전에 보고된 최고의 models(ensembles 포함)를 보다 더 많이 능가한다BLEU, 새로운 state-of-the-art BLEU score인. 이 model의 configuration은 Table의 맨 아래 줄에 나열되어 있다3. Training은 걸렸다days onP100 GPUs. 우리의 base model조차도 경쟁 models 어느 것의 training cost보다 훨씬 적은 비용으로, 이전에 발표된 모든 models와 ensembles를 능가한다.
WMT 2014 English-to-French translation task에서, 우리의 big model은 BLEU score를 달성한다, 이전에 발표된 모든 single models를 능가하며, 보다 적은이전 state-of-the-art model의 training cost로. English-to-French를 위해 학습된 Transformer (big) model은 dropout rate를 사용했다, 대신에.
base models의 경우, 우리는 10-minute intervals로 기록된 마지막 5 checkpoints를 averaging하여 얻은 single model을 사용했다. big models의 경우, 우리는 마지막 20 checkpoints를 averaged했다. 우리는 beam size의 beam search를 사용했다그리고 length penalty [38]. 이러한 hyperparameters는 development set에서의 실험 후 선택되었다. 우리는 inference 동안 maximum output length를 input length +로 설정했다, 그러나 가능할 때 조기에 종료한다[38].
Table2은 우리의 결과를 요약하고 우리의 translation quality와 training costs를 문헌의 다른 model architectures와 비교한다. 우리는 model을 학습하는 데 사용된 floating point operations의 수를 training time, 사용된 GPUs의 수, 그리고 각 GPU의 지속 single-precision floating-point capacity 추정치를 곱하여 추정한다222우리는 K80, K40, M40 및 P100에 대해 각각 2.8, 3.7, 6.0 및 9.5 TFLOPS 값을 사용했다..
6.2 Model Variations
| train | PPL | BLEU | params | |||||||||
| steps | (dev) | (dev) | ||||||||||
| base | 6 | 512 | 2048 | 8 | 64 | 64 | 0.1 | 0.1 | 100K | 4.92 | 25.8 | 65 |
| (A) | 1 | 512 | 512 | 5.29 | 24.9 | |||||||
| 4 | 128 | 128 | 5.00 | 25.5 | ||||||||
| 16 | 32 | 32 | 4.91 | 25.8 | ||||||||
| 32 | 16 | 16 | 5.01 | 25.4 | ||||||||
| (B) | 16 | 5.16 | 25.1 | 58 | ||||||||
| 32 | 5.01 | 25.4 | 60 | |||||||||
| (C) | 2 | 6.11 | 23.7 | 36 | ||||||||
| 4 | 5.19 | 25.3 | 50 | |||||||||
| 8 | 4.88 | 25.5 | 80 | |||||||||
| 256 | 32 | 32 | 5.75 | 24.5 | 28 | |||||||
| 1024 | 128 | 128 | 4.66 | 26.0 | 168 | |||||||
| 1024 | 5.12 | 25.4 | 53 | |||||||||
| 4096 | 4.75 | 26.2 | 90 | |||||||||
| (D) | 0.0 | 5.77 | 24.6 | |||||||||
| 0.2 | 4.95 | 25.5 | ||||||||||
| 0.0 | 4.67 | 25.3 | ||||||||||
| 0.2 | 5.47 | 25.7 | ||||||||||
| (E) | sinusoids 대신 positional embedding | 4.92 | 25.7 | |||||||||
| big | 6 | 1024 | 4096 | 16 | 0.3 | 300K | 4.33 | 26.4 | 213 | |||
Transformer의 서로 다른 components의 중요성을 평가하기 위해, 우리는 base model을 다양한 방식으로 변화시키며 development set, newstest2013에서 English-to-German translation 성능의 변화를 측정했다. 우리는 이전 section에서 설명한 beam search를 사용했지만, checkpoint averaging은 사용하지 않았다. 우리는 이러한 결과를 Table에 제시한다3.
Table에서3rows (A), 우리는 Section에 설명된 대로 computation의 양을 일정하게 유지하면서 attention heads의 수와 attention key 및 value dimensions를 변화시킨다3.2.2. single-head attention은 최상의 설정보다 0.9 BLEU 나쁘지만, heads가 너무 많아도 quality가 떨어진다.
Table에서3rows (B), 우리는 attention key size를 줄이는 것이model quality를 해친다는 것을 관찰한다. 이는 compatibility를 결정하는 것이 쉽지 않으며 dot product보다 더 정교한 compatibility function이 유익할 수 있음을 시사한다. 우리는 또한 rows (C)와 (D)에서 예상대로 더 큰 models가 더 좋고, dropout이 over-fitting을 피하는 데 매우 도움이 됨을 관찰한다. row (E)에서 우리는 sinusoidal positional encoding을 learned positional embeddings로 대체한다[9], 그리고 base model과 거의 동일한 결과를 관찰한다.
6.3 English Constituency Parsing
| Parser | Training | WSJ 23 F1 |
| Vinyals&Kaiser el al. (2014)[37] | WSJ only, discriminative | 88.3 |
| Petrov et al. (2006)[29] | WSJ only, discriminative | 90.4 |
| Zhu et al. (2013)[40] | WSJ only, discriminative | 90.4 |
| Dyer et al. (2016)[8] | WSJ only, discriminative | 91.7 |
| Transformer (4 layers) | WSJ only, discriminative | 91.3 |
| Zhu et al. (2013)[40] | semi-supervised | 91.3 |
| Huang&Harper (2009)[14] | semi-supervised | 91.3 |
| McClosky et al. (2006)[26] | semi-supervised | 92.1 |
| Vinyals&Kaiser el al. (2014)[37] | semi-supervised | 92.1 |
| Transformer (4 layers) | semi-supervised | 92.7 |
| Luong et al. (2015)[23] | multi-task | 93.0 |
| Dyer et al. (2016)[8] | generative | 93.3 |
Transformer가 다른 tasks로 generalize할 수 있는지 평가하기 위해 우리는 English constituency parsing에서 실험을 수행했다. 이 task는 특정한 challenges를 제시한다: output은 강한 structural constraints의 대상이며 input보다 상당히 길다. 더욱이, RNN sequence-to-sequence models는 small-data regimes에서 state-of-the-art results를 달성하지 못했다[37].
우리는 4-layer transformer를 학습했다Penn Treebank의 Wall Street Journal (WSJ) 부분에서[25], 약 40K training sentences. 우리는 또한 약 17M sentences가 있는 더 큰 high-confidence와 BerkleyParser corpora를 사용하여 semi-supervised setting에서 그것을 학습했다[37]. 우리는 WSJ only setting에는 16K tokens의 vocabulary를, semi-supervised setting에는 32K tokens의 vocabulary를 사용했다.
우리는 dropout, attention과 residual 모두(section5.4), learning rates와 beam size를 Section 22 development set에서 선택하기 위해 소수의 실험만 수행했으며, 다른 모든 parameters는 English-to-German base translation model에서 변경되지 않은 채 유지되었다. inference 동안, 우리는 maximum output length를 input length +로 증가시켰다. 우리는 beam size를 사용했다그리고WSJ only와 semi-supervised setting 모두에 대해.
7 결론
이 작업에서, 우리는 Transformer를 제시했다. 이는 encoder-decoder architectures에서 가장 흔히 사용되는 recurrent layers를 multi-headed self-attention으로 대체한, 전적으로 attention에 기반한 최초의 sequence transduction model이다.
translation tasks의 경우, Transformer는 recurrent 또는 convolutional layers에 기반한 architectures보다 훨씬 더 빠르게 학습될 수 있다. WMT 2014 English-to-German 및 WMT 2014 English-to-French translation tasks 모두에서, 우리는 새로운 state of the art를 달성한다. 전자의 task에서 우리의 최고 model은 이전에 보고된 모든 ensembles조차 능가한다.
우리는 attention-based models의 미래에 대해 기대하고 있으며 그것들을 다른 tasks에 적용할 계획이다. 우리는 Transformer를 text 이외의 input 및 output modalities를 포함하는 문제로 확장하고, images, audio 및 video와 같은 큰 inputs와 outputs를 효율적으로 처리하기 위한 local, restricted attention mechanisms를 조사할 계획이다. generation을 덜 sequential하게 만드는 것은 우리의 또 다른 research goals이다.
우리 models를 학습하고 평가하는 데 사용한 code는 다음에서 이용 가능하다https://github.com/tensorflow/tensor2tensor.
감사의 말
우리는 유익한 comments, corrections 및 inspiration을 준 Nal Kalchbrenner와 Stephan Gouws에게 감사한다.
References
- [1] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization. arXiv preprint arXiv:1607.06450, 2016.
- [2] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. 정렬과 번역을 공동으로 학습하는 neural machine translation. CoRR, abs/1409.0473, 2014.
- [3] Denny Britz, Anna Goldie, Minh-Thang Luong, and Quoc V. Le. neural machine translation architectures의 대규모 탐색. CoRR, abs/1703.03906, 2017.
- [4] Jianpeng Cheng, Li Dong, and Mirella Lapata. machine reading을 위한 long short-term memory-networks. arXiv preprint arXiv:1601.06733, 2016.
- [5] Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. statistical machine translation을 위해 rnn encoder-decoder를 사용한 phrase representations 학습. CoRR, abs/1406.1078, 2014.
- [6] Francois Chollet. Xception: depthwise separable convolutions를 이용한 deep learning. arXiv preprint arXiv:1610.02357, 2016.
- [7] Junyoung Chung, Çaglar Gülçehre, Kyunghyun Cho, and Yoshua Bengio. sequence modeling에서 gated recurrent neural networks의 empirical evaluation. CoRR, abs/1412.3555, 2014.
- [8] Chris Dyer, Adhiguna Kuncoro, Miguel Ballesteros, and Noah A. Smith. Recurrent neural network grammars. InProc. of NAACL, 2016.
- [9] Jonas Gehring, Michael Auli, David Grangier, Denis Yarats, and Yann N. Dauphin. Convolutional sequence to sequence learning. arXiv preprint arXiv:1705.03122v2, 2017.
- [10] Alex Graves. recurrent neural networks로 sequences 생성하기. arXiv preprint arXiv:1308.0850, 2013.
- [11] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. image recognition을 위한 deep residual learning. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016.
- [12] Sepp Hochreiter, Yoshua Bengio, Paolo Frasconi, and Jürgen Schmidhuber. recurrent nets에서의 gradient flow: long-term dependencies 학습의 어려움, 2001.
- [13] Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural computation, 9(8):1735–1780, 1997.
- [14] Zhongqiang Huang and Mary Harper. 언어 간 latent annotations를 사용한 self-training PCFG grammars. InProceedings of the 2009 Conference on Empirical Methods in Natural Language Processing, pages 832–841. ACL, August 2009.
- [15] Rafal Jozefowicz, Oriol Vinyals, Mike Schuster, Noam Shazeer, and Yonghui Wu. language modeling의 한계 탐구. arXiv preprint arXiv:1602.02410, 2016.
- [16] Łukasz Kaiser and Samy Bengio. active memory가 attention을 대체할 수 있는가? InAdvances in Neural Information Processing Systems, (NIPS), 2016.
- [17] Łukasz Kaiser and Ilya Sutskever. Neural GPUs learn algorithms. InInternational Conference on Learning Representations (ICLR), 2016.
- [18] Nal Kalchbrenner, Lasse Espeholt, Karen Simonyan, Aaron van den Oord, Alex Graves, and Koray Kavukcuoglu. 선형 시간의 신경 기계 번역. arXiv preprint arXiv:1610.10099v2, 2017.
- [19] Yoon Kim, Carl Denton, Luong Hoang, and Alexander M. Rush. 구조화된 attention networks. InInternational Conference on Learning Representations, 2017.
- [20] Diederik Kingma and Jimmy Ba. Adam: 확률적 최적화를 위한 방법. InICLR, 2015.
- [21] Oleksii Kuchaiev and Boris Ginsburg. LSTM networks를 위한 factorization tricks. arXiv preprint arXiv:1703.10722, 2017.
- [22] Zhouhan Lin, Minwei Feng, Cicero Nogueira dos Santos, Mo Yu, Bing Xiang, Bowen Zhou, and Yoshua Bengio. 구조화된 self-attentive sentence embedding. arXiv preprint arXiv:1703.03130, 2017.
- [23] Minh-Thang Luong, Quoc V. Le, Ilya Sutskever, Oriol Vinyals, and Lukasz Kaiser. Multi-task sequence to sequence learning. arXiv preprint arXiv:1511.06114, 2015.
- [24] Minh-Thang Luong, Hieu Pham, and Christopher D Manning. attention-based neural machine translation에 대한 효과적인 접근법. arXiv preprint arXiv:1508.04025, 2015.
- [25] Mitchell P Marcus, Mary Ann Marcinkiewicz, and Beatrice Santorini. 영어의 대규모 주석 말뭉치 구축: The penn treebank. Computational linguistics, 19(2):313–330, 1993.
- [26] David McClosky, Eugene Charniak, and Mark Johnson. 파싱을 위한 효과적인 self-training. InProceedings of the Human Language Technology Conference of the NAACL, Main Conference, pages 152–159. ACL, June 2006.
- [27] Ankur Parikh, Oscar Täckström, Dipanjan Das, and Jakob Uszkoreit. 분해 가능한 attention model. InEmpirical Methods in Natural Language Processing, 2016.
- [28] Romain Paulus, Caiming Xiong, and Richard Socher. 추상적 요약을 위한 deep reinforced model. arXiv preprint arXiv:1705.04304, 2017.
- [29] Slav Petrov, Leon Barrett, Romain Thibaux, and Dan Klein. 정확하고, compact하며, 해석 가능한 tree annotation 학습. InProceedings of the 21st International Conference on Computational Linguistics and 44th Annual Meeting of the ACL, pages 433–440. ACL, July 2006.
- [30] Ofir Press and Lior Wolf. language models를 개선하기 위해 output embedding 사용. arXiv preprint arXiv:1608.05859, 2016.
- [31] Rico Sennrich, Barry Haddow, and Alexandra Birch. subword units를 사용한 희귀 단어의 neural machine translation. arXiv preprint arXiv:1508.07909, 2015.
- [32] Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. 터무니없이 큰 neural networks: sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538, 2017.
- [33] Nitish Srivastava, Geoffrey E Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: neural networks가 overfitting되는 것을 방지하는 간단한 방법. Journal of Machine Learning Research, 15(1):1929–1958, 2014.
- [34] Sainbayar Sukhbaatar, Arthur Szlam, Jason Weston, and Rob Fergus. End-to-end memory networks. In C. Cortes, N. D. Lawrence, D. D. Lee, M. Sugiyama, and R. Garnett, editors,Advances in Neural Information Processing Systems 28, pages 2440–2448. Curran Associates, Inc., 2015.
- [35] Ilya Sutskever, Oriol Vinyals, and Quoc VV Le. neural networks를 사용한 sequence to sequence learning. InAdvances in Neural Information Processing Systems, pages 3104–3112, 2014.
- [36] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, and Zbigniew Wojna. computer vision을 위한 inception architecture 재고. CoRR, abs/1512.00567, 2015.
- [37] Vinyals&Kaiser, Koo, Petrov, Sutskever, and Hinton. 외국어로서의 문법. InAdvances in Neural Information Processing Systems, 2015.
- [38] Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc V Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, et al. Google의 neural machine translation system: 인간 번역과 기계 번역 사이의 격차 메우기. arXiv preprint arXiv:1609.08144, 2016.
- [39] Jie Zhou, Ying Cao, Xuguang Wang, Peng Li, and Wei Xu. neural machine translation을 위한 fast-forward connections를 가진 deep recurrent models. CoRR, abs/1606.04199, 2016.
- [40] Muhua Zhu, Yue Zhang, Wenliang Chen, Min Zhang, and Jingbo Zhu. 빠르고 정확한 shift-reduce constituent parsing. InProceedings of the 51st Annual Meeting of the ACL (Volume 1: Long Papers), pages 434–443. ACL, August 2013.
Attention 시각화