이미지는 16x16 단어의 가치가 있다:
대규모 이미지 인식을 위한 Transformers
초록
Transformer 아키텍처가 자연어 처리 과제의 사실상 표준이 되었지만, 컴퓨터 비전에 대한 그 적용은 여전히 제한적이다. 비전에서 attention은 convolutional networks와 함께 적용되거나, 전체 구조를 유지한 채 convolutional networks의 특정 구성요소를 대체하는 데 사용된다. 우리는 CNN에 대한 이러한 의존이 필요하지 않으며, 이미지 패치의 시퀀스에 직접 적용된 순수 transformer가 이미지 분류 과제에서 매우 잘 수행될 수 있음을 보인다. 대량의 데이터로 pre-training되고 여러 중간 규모 또는 소규모 이미지 인식 벤치마크(ImageNet, CIFAR-100, VTAB 등)로 transfer될 때, Vision Transformer (ViT)는 훈련에 상당히 더 적은 계산 자원을 요구하면서도 state-of-the-art convolutional networks와 비교해 뛰어난 결과를 달성한다.111Fine-tuning 코드와 pre-trained 모델은 다음에서 이용 가능하다https://github.com/google-research/vision_transformer
1 서론
Self-attention 기반 아키텍처, 특히 Transformers는(Vaswani et al.,2017), 자연어 처리(NLP)에서 선택되는 모델이 되었다. 지배적인 접근법은 큰 텍스트 말뭉치에서 pre-train한 다음 더 작은 과제별 데이터셋에서 fine-tune하는 것이다(Devlin et al.,2019). Transformers의 계산 효율성과 확장성 덕분에, 100B개가 넘는 파라미터를 가진 전례 없는 크기의 모델을 훈련하는 것이 가능해졌다(Brown et al.,2020; Lepikhin et al.,2020). 모델과 데이터셋이 커짐에 따라, 성능이 포화될 조짐은 아직 없다.
그러나 컴퓨터 비전에서는 convolutional 아키텍처가 여전히 지배적이다(LeCun et al.,1989; Krizhevsky et al.,2012; He et al.,2016). NLP의 성공에 영감을 받아, 여러 연구가 CNN과 유사한 아키텍처를 self-attention과 결합하려 시도한다(Wang et al.,2018; Carion et al.,2020), 일부는 convolutions를 완전히 대체한다(Ramachandran et al.,2019; Wang et al.,2020a). 후자의 모델들은 이론적으로는 효율적이지만, 특수화된 attention 패턴의 사용 때문에 현대 하드웨어 가속기에서 아직 효과적으로 확장되지 못했다. 따라서 대규모 이미지 인식에서는 고전적인 ResNet 유사 아키텍처가 여전히 state of the art이다(Mahajan et al.,2018; Xie et al.,2020; Kolesnikov et al.,2020).
NLP에서 Transformer 확장의 성공에 영감을 받아, 우리는 가능한 한 적은 수정으로 표준 Transformer를 이미지에 직접 적용하는 실험을 한다. 이를 위해 이미지를 패치로 나누고, 이 패치들의 선형 임베딩 시퀀스를 Transformer의 입력으로 제공한다. 이미지 패치는 NLP 응용에서의 토큰(단어)과 같은 방식으로 처리된다. 우리는 지도 방식으로 이미지 분류에서 모델을 훈련한다.
강한 regularization 없이 ImageNet과 같은 중간 규모 데이터셋에서 훈련될 때, 이러한 모델들은 비슷한 크기의 ResNets보다 몇 퍼센트 포인트 낮은 보통 수준의 정확도를 낸다. 겉보기에 실망스러운 이 결과는 예상될 수 있다: Transformers는 translation equivariance와 locality 같은 CNN에 내재된 일부 inductive bias가 부족하므로, 충분하지 않은 양의 데이터로 훈련될 때 잘 일반화하지 못한다.
그러나 모델이 더 큰 데이터셋(14M-300M 이미지)에서 훈련되면 양상이 바뀐다. 우리는 대규모 훈련이 inductive bias를 압도한다는 것을 발견한다. 우리의 Vision Transformer (ViT)는 충분한 규모로 pre-trained되고 더 적은 datapoints를 가진 과제로 transfer될 때 뛰어난 결과를 달성한다. 공개 ImageNet-21k 데이터셋 또는 내부 JFT-300M 데이터셋에서 pre-trained될 때, ViT는 여러 이미지 인식 벤치마크에서 state of the art에 근접하거나 이를 능가한다. 특히, 최고의 모델은 다음의 정확도에 도달한다ImageNet에서,ImageNet-ReaL에서,CIFAR-100에서, 그리고19개 과제의 VTAB suite에서.
2 관련 연구
Transformers는 다음에 의해 제안되었다Vaswani et al. (2017)기계 번역을 위해, 그리고 이후 많은 NLP 과제에서 state of the art 방법이 되었다. 대형 Transformer 기반 모델은 종종 큰 말뭉치에서 pre-train된 뒤 당면 과제를 위해 fine-tune된다: BERT(Devlin et al.,2019)는 denoising self-supervised pre-training 과제를 사용하는 반면, GPT 계열 연구는 language modeling을 pre-training 과제로 사용한다(Radford et al.,2018; 2019; Brown et al.,2020).
self-attention을 이미지에 순진하게 적용하면 각 픽셀이 모든 다른 픽셀에 attend해야 한다. 픽셀 수에 대해 이차 비용이 들기 때문에, 이는 현실적인 입력 크기로 확장되지 않는다. 따라서 이미지 처리 맥락에서 Transformers를 적용하기 위해, 과거에 여러 근사법이 시도되었다.Parmar et al. (2018)은 각 query 픽셀에 대해 전역적으로가 아니라 국소 이웃에서만 self-attention을 적용했다. 이러한 local multi-head dot-product self attention 블록은 convolutions를 완전히 대체할 수 있다(Hu et al.,2019; Ramachandran et al.,2019; Zhao et al.,2020). 다른 연구 흐름에서, Sparse Transformers는(Child et al.,2019)이미지에 적용 가능하도록 전역 self-attention에 대한 확장 가능한 근사법을 사용한다. attention을 확장하는 대안적 방법은 다양한 크기의 블록에서 이를 적용하는 것이다(Weissenborn et al.,2019), 극단적인 경우에는 개별 축을 따라서만 적용한다(Ho et al.,2019; Wang et al.,2020a). 이러한 특수화된 attention 아키텍처 중 다수는 컴퓨터 비전 과제에서 유망한 결과를 보이지만, 하드웨어 가속기에서 효율적으로 구현되기 위해 복잡한 엔지니어링을 요구한다.
우리 것과 가장 관련이 있는 것은 다음의 모델이다Cordonnier et al. (2020), 이는 입력 이미지에서 크기의 패치를 추출하고 그 위에 full self-attention을 적용한다.이 모델은 ViT와 매우 유사하지만, 우리의 연구는 대규모 pre-training이 vanilla transformers를 state-of-the-art CNNs와 경쟁 가능하게(또는 심지어 더 낫게) 만든다는 것을 보이는 데까지 더 나아간다. 더구나,Cordonnier et al. (2020)은 다음의 작은 패치 크기를 사용한다픽셀로, 이는 모델을 작은 해상도 이미지에만 적용 가능하게 만드는 반면, 우리는 중간 해상도 이미지도 처리한다.
convolutional neural networks (CNNs)를 self-attention의 형태와 결합하는 데에도 많은 관심이 있어 왔다. 예를 들어 이미지 분류를 위해 feature maps를 증강하는 방식이다(Bello et al.,2019)또는 object detection을 위해 CNN의 출력을 self-attention으로 추가 처리하는 방식이다(Hu et al.,2018; Carion et al.,2020), video processing(Wang et al.,2018; Sun et al.,2019), image classification(Wu et al.,2020), unsupervised object discovery(Locatello et al.,2020), 또는 unified text-vision tasks(Chen et al.,2020c; Lu et al.,2019; Li et al.,2019).
또 다른 최근 관련 모델은 image GPT (iGPT)이다(Chen et al.,2020a), 이는 이미지 해상도와 색 공간을 줄인 뒤 Transformers를 이미지 픽셀에 적용한다. 이 모델은 생성 모델로서 비지도 방식으로 훈련되며, 결과 표현은 이후 분류 성능을 위해 fine-tune되거나 선형적으로 probe될 수 있고, ImageNet에서 최대 정확도 72%를 달성한다.
우리 연구는 표준 ImageNet 데이터셋보다 더 큰 규모에서 이미지 인식을 탐구하는 증가하는 논문 모음에 기여한다. 추가 데이터 소스를 사용하면 표준 벤치마크에서 state-of-the-art 결과를 달성할 수 있다(Mahajan et al.,2018; Touvron et al.,2019; Xie et al.,2020). 더구나,Sun et al. (2017)은 CNN 성능이 데이터셋 크기에 따라 어떻게 확장되는지 연구하고,Kolesnikov et al. (2020); Djolonga et al. (2020)은 ImageNet-21k와 JFT-300M 같은 대규모 데이터셋에서 CNN transfer learning에 대한 경험적 탐구를 수행한다. 우리도 이 두 후자의 데이터셋에 초점을 맞추지만, 이전 연구에서 사용된 ResNet 기반 모델 대신 Transformers를 훈련한다.
3 방법
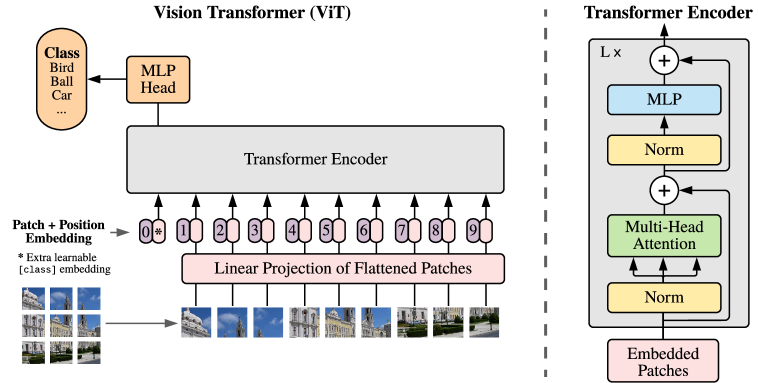 |
모델 설계에서 우리는 원래 Transformer를(Vaswani et al.,2017)가능한 한 가깝게 따른다. 의도적으로 단순한 이 설정의 장점은 확장 가능한 NLP Transformer 아키텍처와 그 효율적인 구현을 거의 그대로 사용할 수 있다는 것이다.
3.1 Vision Transformer (ViT)
모델의 개요는 Figure에 묘사되어 있다1. 표준 Transformer는 1D 토큰 임베딩 시퀀스를 입력으로 받는다. 2D 이미지를 처리하기 위해, 우리는 이미지를 재형성한다평탄화된 2D 패치의 시퀀스로, 여기서는 원본 이미지의 해상도이고,는 채널 수이며,는 각 이미지 패치의 해상도이고,는 결과 패치 수로, Transformer의 유효 입력 시퀀스 길이로도 쓰인다. Transformer는 모든 층에서 일정한 latent vector size를 사용하므로우리는 패치를 평탄화하고 다음으로 매핑한다훈련 가능한 선형 투영으로 차원(Eq.1). 우리는 이 투영의 출력을 patch embeddings라고 부른다.
BERT의[class]토큰과 유사하게, 우리는 임베드된 패치들의 시퀀스 앞에 학습 가능한 임베딩을 덧붙인다(), Transformer encoder의 출력에서 그 상태()가 이미지 표현으로 쓰인다(Eq.4). pre-training과 fine-tuning 모두에서, classification head가 다음에 부착된다. classification head는 pre-training 시에는 하나의 hidden layer를 가진 MLP로 구현되고, fine-tuning 시에는 단일 linear layer로 구현된다.
위치 정보를 유지하기 위해 patch embeddings에 position embeddings가 추가된다. 더 발전된 2D-aware position embeddings를 사용해도 유의미한 성능 향상을 관찰하지 못했기 때문에, 우리는 표준 학습 가능한 1D position embeddings를 사용한다(AppendixD.4). 결과 embedding vectors 시퀀스가 encoder의 입력으로 사용된다.
Transformer encoder는(Vaswani et al.,2017)multiheaded self-attention(MSA, Appendix 참조)의 교대 층으로 구성된다A) 및 MLP blocks (Eq.2, 3). Layernorm (LN)은 모든 block 전에 적용되고, residual connections는 모든 block 뒤에 적용된다(Wang et al.,2019; Baevski&Auli,2019). MLP는 GELU 비선형성을 가진 두 층을 포함한다.
| (1) | |||||
| (2) | |||||
| (3) | |||||
| (4) | |||||
Inductive bias.
우리는 Vision Transformer가 CNNs보다 이미지 특화 inductive bias가 훨씬 적다는 점을 언급한다. CNNs에서는 locality, 2차원 이웃 구조, translation equivariance가 전체 모델의 각 층에 내장되어 있다. ViT에서는 MLP layers만 local이고 translationally equivariant인 반면, self-attention layers는 global이다. 2차원 이웃 구조는 매우 제한적으로 사용된다: 모델의 시작에서 이미지를 패치로 자를 때와, 아래에 설명된 것처럼 fine-tuning 시 다른 해상도의 이미지에 맞게 position embeddings를 조정할 때이다. 그 외에는 초기화 시 position embeddings가 패치의 2D 위치에 대한 정보를 담지 않으며, 패치들 사이의 모든 공간적 관계는 처음부터 학습되어야 한다.
Hybrid Architecture.
원시 이미지 패치의 대안으로, 입력 시퀀스는 CNN의 feature maps로부터 형성될 수 있다(LeCun et al.,1989). 이 hybrid model에서, patch embedding projection(Eq.1)은 CNN feature map에서 추출된 패치에 적용된다. 특수한 경우로, 패치는 spatial size 1x1을 가질 수 있는데, 이는 입력 시퀀스가 feature map의 spatial dimensions를 단순히 평탄화하고 Transformer dimension으로 투영함으로써 얻어진다는 것을 의미한다. classification input embedding과 position embeddings는 위에서 설명한 대로 추가된다.
3.2 Fine-tuning 및 더 높은 해상도
일반적으로, 우리는 큰 데이터셋에서 ViT를 pre-train하고, (더 작은) downstream tasks로 fine-tune한다. 이를 위해, pre-trained prediction head를 제거하고 zero-initialized를 부착한다feedforward layer, 여기서는 downstream classes의 수이다. pre-training보다 더 높은 해상도에서 fine-tune하는 것이 종종 유익하다(Touvron et al.,2019; Kolesnikov et al.,2020). 더 높은 해상도의 이미지를 입력할 때, 우리는 patch size를 동일하게 유지하며, 이는 더 큰 유효 sequence length를 초래한다. Vision Transformer는 임의의 sequence lengths를 처리할 수 있지만(메모리 제약까지), pre-trained position embeddings는 더 이상 의미가 없을 수 있다. 따라서 우리는 원본 이미지에서의 위치에 따라 pre-trained position embeddings의 2D interpolation을 수행한다. 이 해상도 조정과 patch extraction이 이미지의 2D 구조에 관한 inductive bias가 Vision Transformer에 수동으로 주입되는 유일한 지점임에 주목하라.
4 실험
우리는 ResNet, Vision Transformer (ViT), 그리고 hybrid의 representation learning 능력을 평가한다. 각 모델의 데이터 요구 사항을 이해하기 위해, 다양한 크기의 데이터셋에서 pre-train하고 많은 benchmark tasks에서 평가한다. 모델 pre-training의 계산 비용을 고려할 때, ViT는 매우 유리하게 수행되어 더 낮은 pre-training cost로 대부분의 recognition benchmarks에서 state of the art를 달성한다. 마지막으로, self-supervision을 사용한 작은 실험을 수행하고, self-supervised ViT가 미래에 대한 가능성을 지님을 보인다.
4.1 설정
Datasets.모델 확장성을 탐구하기 위해, 우리는 1k classes와 1.3M images를 가진 ILSVRC-2012 ImageNet 데이터셋(이하 ImageNet이라고 부름), 21k classes와 14M images를 가진 그 상위 집합 ImageNet-21k를 사용한다(Deng et al.,2009), 그리고 JFT(Sun et al.,2017)18k classes와 303M high-resolution images를 가진. 우리는 다음을 따라 downstream tasks의 test sets에 대해 pre-training datasets를 de-duplicate한다Kolesnikov et al. (2020). 우리는 이러한 dataset에서 훈련된 모델을 여러 benchmark tasks로 transfer한다: 원래 validation labels와 정제된 ReaL labels의 ImageNet(Beyer et al.,2020), CIFAR-10/100(Krizhevsky,2009), Oxford-IIIT Pets(Parkhi et al.,2012), 그리고 Oxford Flowers-102(Nilsback&Zisserman,2008). 이러한 데이터셋에 대해서, pre-processing은 다음을 따른다Kolesnikov et al. (2020).
우리는 또한 19-task VTAB classification suite에서 평가한다(Zhai et al.,2019b). VTAB는 과제당 1 000 training examples를 사용하여 다양한 과제로의 low-data transfer를 평가한다. 과제들은 세 그룹으로 나뉜다:Natural– 위와 같은 과제들, Pets, CIFAR 등.Specialized– medical 및 satellite imagery, 그리고Structured– localization처럼 geometric understanding을 요구하는 과제들.
Model Variants.우리는 ViT configurations를 BERT에 사용된 것들에 기반한다(Devlin et al.,2019), Table에 요약된 것처럼1. “Base”와 “Large” 모델은 BERT에서 직접 채택했으며, 더 큰 “Huge” 모델을 추가한다. 이하에서는 모델 크기와 입력 patch size를 나타내기 위해 간단한 표기를 사용한다: 예를 들어, ViT-L/16은 다음을 가진 “Large” variant를 의미한다input patch size. Transformer의 sequence length는 patch size의 제곱에 반비례하므로, 더 작은 patch size를 가진 모델은 계산적으로 더 비싸다는 점에 주목하라.
baseline CNNs에 대해서는, 우리는 ResNet을 사용한다(He et al.,2016), 하지만 Batch Normalization layers를 대체한다(Ioffe&Szegedy,2015)Group Normalization과 함께(Wu&He,2018), 그리고 standardized convolutions를 사용했다(Qiao et al.,2019). 이러한 수정은 전이를 개선한다(Kolesnikov et al.,2020), 그리고 우리는 수정된 모델을 “ResNet (BiT)”라고 표기한다. 하이브리드의 경우, 중간 feature map을 하나의 “pixel” 패치 크기로 ViT에 입력한다. 서로 다른 sequence length를 실험하기 위해, 우리는 (i) 일반 ResNet50의 stage 4 출력을 취하거나 (ii) stage 4를 제거하고, 동일한 수의 layer를 stage 3에 배치하여(총 layer 수는 유지) 이 확장된 stage 3의 출력을 취한다. 옵션 (ii)는 4x 더 긴 sequence length와 더 비싼 ViT 모델을 초래한다.
| Model | Layers | Hidden size | MLP size | Heads | Params |
|---|---|---|---|---|---|
| ViT-Base | 12 | 768 | 3072 | 12 | 86M |
| ViT-Large | 24 | 1024 | 4096 | 16 | 307M |
| ViT-Huge | 32 | 1280 | 5120 | 16 | 632M |
Training&Fine-tuning.우리는 ResNets를 포함한 모든 모델을 Adam을 사용하여 훈련한다(Kingma&Ba,2015)와 함께, , batch size 4096을 사용하고 높은 weight decay를 적용한다, 이는 모든 모델의 전이에 유용하다는 것을 발견했다(AppendixD.1는 일반적인 관행과 대조적으로, 우리의 설정에서 Adam이 ResNets에 대해 SGD보다 약간 더 잘 작동함을 보여준다). 우리는 linear learning rate warmup과 decay를 사용하며, 자세한 내용은 Appendix를 보라B.1자세한 내용은. fine-tuning을 위해 우리는 모든 모델에 대해 momentum이 있는 SGD, batch size 512를 사용하며, Appendix를 보라B.1.1. Table의 ImageNet 결과에 대해서는2, 우리는 더 높은 해상도에서 fine-tuning했다:ViT-L/16에 대해 그리고ViT-H/14에 대해, 또한 사용했다Polyak&Juditsky (1992)factor를 사용한 averaging (Ramachandran et al.,2019; Wang et al.,2020b).
Metrics.우리는 downstream datasets에서의 결과를 few-shot 또는 fine-tuning accuracy를 통해 보고한다. Fine-tuning accuracies는 각 모델을 해당 dataset에서 fine-tuning한 후의 성능을 포착한다. Few-shot accuracies는 training images의 subset의 (고정된) representation을target vectors로 매핑하는 regularized least-squares regression 문제를 풀어 얻는다. 이 정식화는 우리가 closed form으로 정확한 해를 복원할 수 있게 한다. 우리는 주로 fine-tuning 성능에 초점을 맞추지만, fine-tuning이 너무 비용이 많이 드는 경우 빠른 on-the-fly 평가를 위해 때때로 linear few-shot accuracies를 사용한다.
4.2 최신 기술과의 비교
우리는 먼저 우리의 가장 큰 모델들 – ViT-H/14와 ViT-L/16 – 을 문헌의 state-of-the-art CNNs와 비교한다. 첫 번째 비교 지점은 Big Transfer (BiT)이다(Kolesnikov et al.,2020), 이는 큰 ResNets로 supervised transfer learning을 수행한다. 두 번째는 Noisy Student이다(Xie et al.,2020), 이는 labels를 제거한 ImageNet과 JFT-300M에서 semi-supervised learning을 사용하여 훈련된 큰 EfficientNet이다. 현재 Noisy Student는 ImageNet에서 state of the art이고 BiT-L은 여기서 보고된 다른 datasets에서 state of the art이다. 모든 모델은 TPUv3 하드웨어에서 훈련되었으며, 우리는 각 모델을 pre-train하는 데 걸린 TPUv3-core-days 수, 즉 훈련에 사용된 TPU v3 core 수(chip당 2개)에 days 단위의 훈련 시간을 곱한 값을 보고한다.
| Ours-JFT | Ours-JFT | Ours-I21k | BiT-L | Noisy Student | |
|---|---|---|---|---|---|
| (ViT-H/14) | (ViT-L/16) | (ViT-L/16) | (ResNet152x4) | (EfficientNet-L2) | |
| ImageNet | |||||
| ImageNet ReaL | |||||
| CIFAR-10 | |||||
| CIFAR-100 | |||||
| Oxford-IIIT Pets | |||||
| Oxford Flowers-102 | |||||
| VTAB (19 tasks) | |||||
| TPUv3-core-days | k | k | k | k | k |
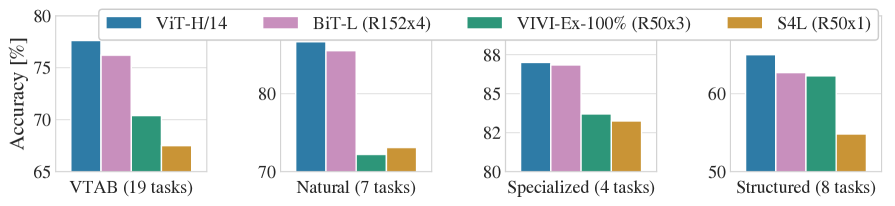
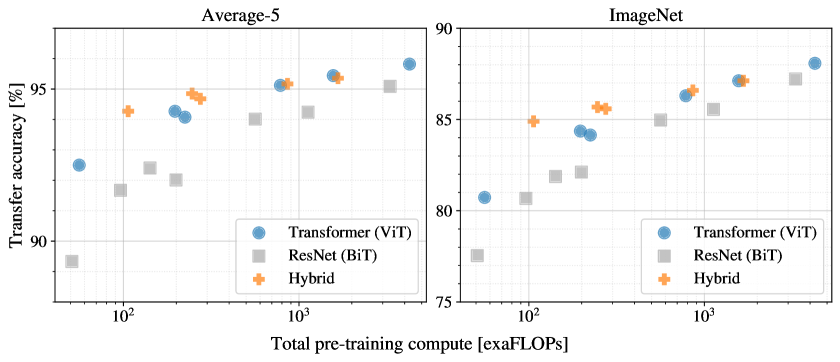
Table2은 결과를 보여준다. JFT-300M에서 pre-trained된 더 작은 ViT-L/16 모델은 모든 tasks에서 BiT-L(동일한 dataset에서 pre-trained됨)을 능가하면서도, 훈련에 상당히 적은 computational resources를 필요로 한다. 더 큰 모델인 ViT-H/14는 특히 더 어려운 datasets – ImageNet, CIFAR-100, 그리고 VTAB suite – 에서 성능을 더욱 향상시킨다. 흥미롭게도, 이 모델은 여전히 이전 state of the art보다 pre-train하는 데 상당히 적은 compute가 들었다. 그러나 우리는 pre-training efficiency가 architecture 선택뿐 아니라 training schedule, optimizer, weight decay 등과 같은 다른 parameters에도 영향을 받을 수 있음을 언급한다. 우리는 Section에서 서로 다른 architectures에 대한 performance vs. compute의 controlled study를 제공한다4.4. 마지막으로, 공개 ImageNet-21k dataset에서 pre-trained된 ViT-L/16 모델도 대부분의 datasets에서 잘 수행하면서, pre-train하는 데 더 적은 resources를 사용한다: 표준 cloud TPUv3 8 cores를 사용해 약 30 days 안에 훈련될 수 있었다.
Figure2는 VTAB tasks를 각각의 groups로 분해하고, 이 benchmark에서 이전 SOTA methods와 비교한다: BiT, VIVI – ImageNet과 Youtube에서 공동 훈련된 ResNet(Tschannen et al.,2020), 그리고 S4L – ImageNet에서 supervised plus semi-supervised learning(Zhai et al.,2019a). ViT-H/14는Natural및Structuredtasks에서 BiT-R152x4 및 다른 methods를 능가한다.Specialized에서는 상위 두 모델의 성능이 비슷하다.
4.3 Pre-training Data Requirements
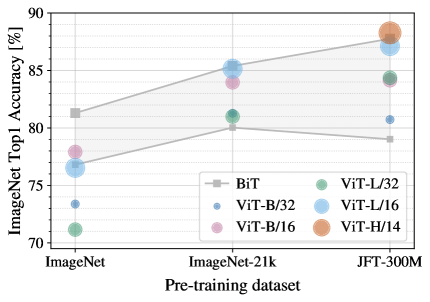
Vision Transformer는 큰 JFT-300M dataset에서 pre-trained될 때 잘 수행한다. ResNets보다 vision에 대한 inductive biases가 더 적을 때, dataset size는 얼마나 중요한가? 우리는 두 series의 experiments를 수행한다.
첫째, 우리는 ViT 모델들을 점점 커지는 datasets: ImageNet, ImageNet-21k, 그리고 JFT-300M에서 pre-train한다. 더 작은 datasets에서 성능을 높이기 위해, 우리는 세 가지 기본 regularization parameters – weight decay, dropout, 그리고 label smoothing – 를 최적화한다. Figure4는 ImageNet으로 fine-tuning한 후의 결과를 보여준다(다른 datasets에 대한 결과는 Table에 표시됨5)222ImageNet pre-trained 모델들도 fine-tuned되지만, 다시 ImageNet에서 수행된다는 점에 유의하라. 이는 fine-tuning 동안의 resolution 증가가 성능을 향상시키기 때문이다.. 가장 작은 dataset인 ImageNet에서 pre-trained될 때, ViT-Large 모델들은 (moderate) regularization에도 불구하고 ViT-Base 모델들에 비해 성능이 낮다. ImageNet-21k pre-training에서는, 이들의 성능이 비슷하다. JFT-300M에서만 우리는 더 큰 모델의 완전한 이점을 본다. Figure4는 또한 서로 다른 크기의 BiT 모델들이 포괄하는 성능 영역을 보여준다. BiT CNNs는 ImageNet에서 ViT를 능가하지만, 더 큰 datasets에서는 ViT가 추월한다.
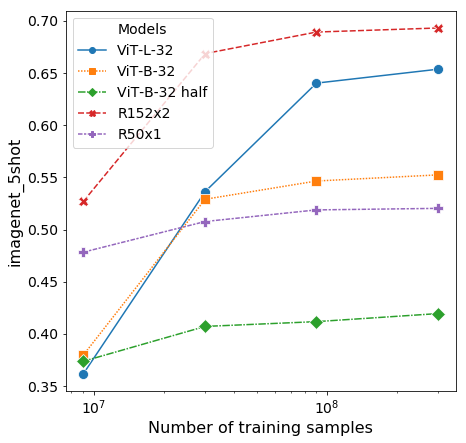
둘째, 우리는 full JFT-300M dataset뿐 아니라 9M, 30M, 90M의 random subsets에서 모델들을 훈련한다. 우리는 더 작은 subsets에 대해 추가 regularization을 수행하지 않고 모든 settings에서 동일한 hyper-parameters를 사용한다. 이런 방식으로, 우리는 regularization의 효과가 아니라 intrinsic model properties를 평가한다. 그러나 우리는 early-stopping을 사용하고, 훈련 동안 달성된 best validation accuracy를 보고한다. compute를 절약하기 위해, 우리는 full fine-tuning accuracy 대신 few-shot linear accuracy를 보고한다. Figure4는 결과를 포함한다. Vision Transformers는 더 작은 datasets에서 comparable computational cost의 ResNets보다 더 많이 overfit한다. 예를 들어, ViT-B/32는 ResNet50보다 약간 더 빠르다; 9M subset에서는 훨씬 더 나쁘게 수행하지만, 90M+ subsets에서는 더 잘 수행한다. ResNet152x2와 ViT-L/16에도 동일하게 적용된다. 이 결과는 convolutional inductive bias가 더 작은 datasets에는 유용하지만, 더 큰 datasets에서는 관련 patterns를 data에서 직접 학습하는 것이 충분하며, 심지어 유익하다는 직관을 강화한다.
전반적으로, ImageNet에서의 few-shot 결과(Figure4), 그리고 VTAB에서의 low-data 결과(Table2)는 매우 low-data transfer에 대해 유망해 보인다. ViT의 few-shot properties에 대한 추가 분석은 향후 연구의 흥미로운 방향이다.
4.4 Scaling Study
우리는 JFT-300M에서의 transfer performance를 평가함으로써 서로 다른 모델들의 controlled scaling study를 수행한다. 이 설정에서 data size는 모델들의 성능을 bottleneck하지 않으며, 우리는 각 모델의 pre-training cost 대비 performance를 평가한다. 모델 집합은 다음을 포함한다: 7 epochs 동안 pre-trained된 7 ResNets, R50x1, R50x2 R101x1, R152x1, R152x2, plus 14 epochs 동안 pre-trained된 R152x2와 R200x3; 7 epochs 동안 pre-trained된 6 Vision Transformers, ViT-B/32, B/16, L/32, L/16, plus 14 epochs 동안 pre-trained된 L/16와 H/14; 그리고 7 epochs 동안 pre-trained된 5 hybrids, R50+ViT-B/32, B/16, L/32, L/16, plus 14 epochs 동안 pre-trained된 R50+ViT-L/16 (hybrids의 경우, 모델 이름 끝의 숫자는 patch size가 아니라 ResNet backbone의 total dowsampling ratio를 의미한다).
Figure5는 total pre-training compute 대비 transfer performance를 포함한다(computational costs에 대한 자세한 내용은 Appendix를 보라D.5). 모델별 상세 결과는 Appendix의 Table에 제공된다6. 몇 가지 patterns가 관찰될 수 있다. 첫째, Vision Transformers는 performance/compute trade-off에서 ResNets를 지배한다. ViT는 동일한 성능(5 datasets에 대한 평균)을 달성하는 데 대략더 적은 compute를 사용한다. 둘째, hybrids는 작은 computational budgets에서 ViT를 약간 능가하지만, 더 큰 models에서는 차이가 사라진다. 이 결과는 다소 놀라운데, convolutional local feature processing이 어떤 size에서도 ViT를 도울 것으로 예상할 수 있기 때문이다. 셋째, Vision Transformers는 시도된 범위 내에서 saturate하지 않는 것으로 보이며, 이는 향후 scaling efforts에 동기를 부여한다.
4.5 Vision Transformer 들여다보기

Vision Transformer가 image data를 처리하는 방식을 이해하기 시작하기 위해, 우리는 그 internal representations를 분석한다. Vision Transformer의 첫 번째 layer는 flattened patches를 lower-dimensional space로 linearly projects한다(Eq.1). Figure7(왼쪽)는 learned embedding filters의 상위 principal components를 보여준다. components는 각 patch 내부의 fine structure에 대한 low-dimensional representation을 위한 그럴듯한 basis functions와 닮았다.
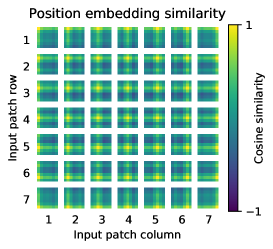
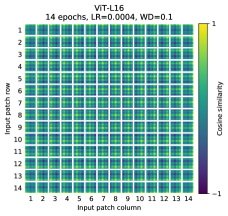
projection 이후, learned position embedding이 patch representations에 추가된다. Figure7(가운데)는 모델이 position embeddings의 similarity에서 image 내 distance를 encode하도록 학습함을 보여준다, 즉 더 가까운 patches는 더 유사한 position embeddings를 가지는 경향이 있다. 더 나아가 row-column structure가 나타난다; 같은 row/column의 patches는 유사한 embeddings를 가진다. 마지막으로, 더 큰 grids에서는 sinusoidal structure가 때때로 명백하다(AppendixD). position embeddings가 2D image topology를 represent하도록 학습한다는 점은 hand-crafted 2D-aware embedding variants가 개선을 가져오지 않는 이유를 설명한다(AppendixD.4).

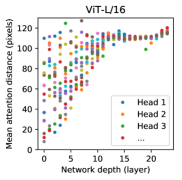
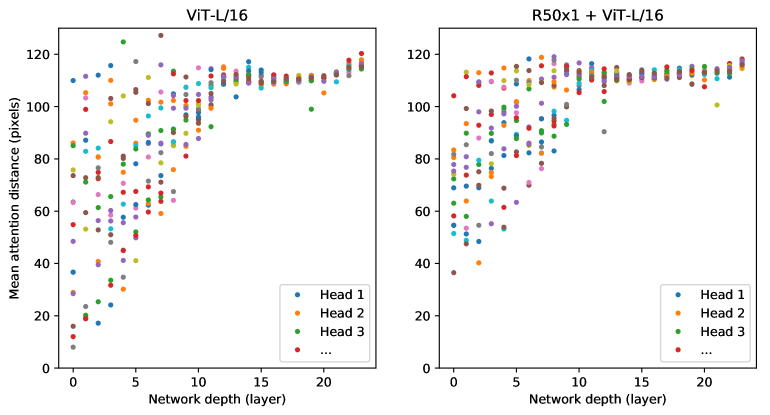
Self-attention은 ViT가 가장 낮은 layers에서도 전체 image에 걸쳐 정보를 통합할 수 있게 한다. 우리는 network가 이 능력을 어느 정도 사용하는지 조사한다. 구체적으로, 우리는 attention weights를 기반으로 정보가 통합되는 image space에서의 average distance를 계산한다(Figure7, 오른쪽). 이 “attention distance”는 CNNs의 receptive field size와 유사하다. 우리는 일부 heads가 가장 낮은 layers에서 이미 image의 대부분에 attention함을 발견했으며, 이는 정보를 전역적으로 통합하는 능력이 실제로 모델에 의해 사용됨을 보여준다. 다른 attention heads는 low layers에서 일관되게 작은 attention distances를 가진다. 이러한 매우 localized attention은 Transformer 전에 ResNet을 적용하는 hybrid models에서는 덜 두드러진다(Figure7, 오른쪽), 이는 그것이 CNNs의 early convolutional layers와 유사한 기능을 할 수 있음을 시사한다. 더 나아가, attention distance는 network depth와 함께 증가한다. 전역적으로, 우리는 모델이 classification에 의미론적으로 관련된 image regions에 attention한다는 것을 발견한다(Figure6).
4.6 Self-supervision
Transformers는 NLP tasks에서 인상적인 성능을 보인다. 그러나 그 성공의 많은 부분은 뛰어난 scalability뿐 아니라 large scale self-supervised pre-training에서도 비롯된다(Devlin et al.,2019; Radford et al.,2018). 우리는 또한 예비 탐색을 수행한다masked patch predictionself-supervision을 위해, BERT에서 사용된 masked language modeling task를 모방한다. self-supervised pre-training으로, 우리의 더 작은 ViT-B/16 모델은 ImageNet에서 79.9% accuracy를 달성하며, scratch에서 훈련하는 것보다 2%의 유의미한 개선이지만, supervised pre-training보다는 여전히 4% 뒤처진다. AppendixB.1.2는 추가 세부 사항을 포함한다. 우리는 contrastive pre-training의 탐색을 남겨둔다(Chen et al.,2020b; He et al.,2020; Bachman et al.,2019; Hénaff et al.,2020)향후 연구로.
5 결론
우리는 Transformers를 image recognition에 직접 적용하는 것을 탐구했다. computer vision에서 self-attention을 사용하는 이전 연구들과 달리, 우리는 initial patch extraction step을 제외하고 architecture에 image-specific inductive biases를 도입하지 않는다. 대신, 우리는 image를 patches의 sequence로 해석하고 NLP에서 사용되는 표준 Transformer encoder로 처리한다. 이 단순하지만 scalable한 전략은 큰 datasets에서의 pre-training과 결합될 때 놀라울 만큼 잘 작동한다. 따라서 Vision Transformer는 많은 image classification datasets에서 state of the art와 맞먹거나 이를 초과하면서도, pre-train 비용이 비교적 저렴하다.
이러한 초기 결과는 고무적이지만, 많은 과제가 남아 있다. 하나는 ViT를 detection과 segmentation 같은 다른 computer vision tasks에 적용하는 것이다. 우리의 결과는 다음의 결과들과 결합되어Carion et al. (2020), 이 접근법의 가능성을 나타낸다. 또 다른 과제는 self-supervised pre-training methods를 계속 탐구하는 것이다. 우리의 초기 experiments는 self-supervised pre-training으로부터의 개선을 보여주지만, self-supervised와 large-scale supervised pre-training 사이에는 여전히 큰 격차가 있다. 마지막으로, ViT의 추가 scaling은 성능 향상으로 이어질 가능성이 높다.
감사의 말
이 작업은 Berlin, Zürich, Amsterdam에서 수행되었다. 우리는 도움을 준 Google의 많은 동료들에게 감사하며, 특히 infrastructure와 code의 open-source release에 결정적인 도움을 준 Andreas Steiner; large-scale training infrastructure에 도움을 준 Joan Puigcerver와 Maxim Neumann; 유용한 논의를 해 준 Dmitry Lepikhin, Aravindh Mahendran, Daniel Keysers, Mario Lučić, Noam Shazeer, Ashish Vaswani, Colin Raffel에게 감사한다.
References
- Abnar&Zuidema (2020) Samira Abnar and Willem Zuidema. transformers에서 attention flow를 정량화하기. InACL, 2020.
- Bachman et al. (2019) Philip Bachman, R Devon Hjelm, and William Buchwalter. views 전반의 mutual information을 최대화하여 representations 학습하기. InNeurIPS, 2019.
- Baevski&Auli (2019) Alexei Baevski and Michael Auli. neural language modeling을 위한 adaptive input representations. InICLR, 2019.
- Bello et al. (2019) I. Bello, B. Zoph, Q. Le, A. Vaswani, and J. Shlens. Attention augmented convolutional networks. InICCV, 2019.
- Beyer et al. (2020) Lucas Beyer, Olivier J. Hénaff, Alexander Kolesnikov, Xiaohua Zhai, and Aäron van den Oord. 우리는 imagenet을 끝냈는가? arXiv, 2020.
- Brown et al. (2020) Tom B Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. arXiv, 2020.
- Carion et al. (2020) Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. transformers를 사용한 end-to-end object detection. InECCV, 2020.
- Chen et al. (2020a) Mark Chen, Alec Radford, Rewon Child, Jeff Wu, and Heewoo Jun. pixels로부터의 generative pretraining. InICML, 2020a.
- Chen et al. (2020b) Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey E. Hinton. 시각적 표현의 contrastive learning을 위한 간단한 프레임워크. 에서ICML, 2020b.
- Chen et al. (2020c) Yen-Chun Chen, Linjie Li, Licheng Yu, Ahmed El Kholy, Faisal Ahmed, Zhe Gan, Yu Cheng, and Jingjing Liu. UNITER: UNiversal Image-TExt Representation Learning. 에서ECCV, 2020c.
- Child et al. (2019) Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. sparse transformers로 긴 시퀀스 생성하기. arXiv, 2019.
- Cordonnier et al. (2020) Jean-Baptiste Cordonnier, Andreas Loukas, and Martin Jaggi. self-attention과 convolutional layers 사이의 관계에 대하여. 에서ICLR, 2020.
- Deng et al. (2009) J. Deng, W. Dong, R. Socher, L. Li, Kai Li, and Li Fei-Fei. Imagenet: 대규모 계층적 이미지 데이터베이스. 에서CVPR, 2009.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: 언어 이해를 위한 깊은 양방향 transformers의 사전 학습. 에서NAACL, 2019.
- Djolonga et al. (2020) Josip Djolonga, Jessica Yung, Michael Tschannen, Rob Romijnders, Lucas Beyer, Alexander Kolesnikov, Joan Puigcerver, Matthias Minderer, Alexander D’Amour, Dan Moldovan, Sylvan Gelly, Neil Houlsby, Xiaohua Zhai, and Mario Lucic. convolutional neural networks의 견고성과 전이 가능성에 대하여. arXiv, 2020.
- He et al. (2016) Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 이미지 인식을 위한 deep residual learning. 에서CVPR, 2016.
- He et al. (2020) Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. 비지도 시각적 표현 학습을 위한 momentum contrast. 에서CVPR, 2020.
- Ho et al. (2019) Jonathan Ho, Nal Kalchbrenner, Dirk Weissenborn, and Tim Salimans. 다차원 transformers에서의 axial attention. arXiv, 2019.
- Hu et al. (2018) Han Hu, Jiayuan Gu, Zheng Zhang, Jifeng Dai, and Yichen Wei. 객체 검출을 위한 relation networks. 에서CVPR, 2018.
- Hu et al. (2019) Han Hu, Zheng Zhang, Zhenda Xie, and Stephen Lin. 이미지 인식을 위한 local relation networks. 에서ICCV, 2019.
- Huang et al. (2020) Zilong Huang, Xinggang Wang, Yunchao Wei, Lichao Huang, Humphrey Shi, Wenyu Liu, and Thomas S. Huang. Ccnet: semantic segmentation을 위한 criss-cross attention. 에서ICCV, 2020.
- Hénaff et al. (2020) Olivier J. Hénaff, Aravind Srinivas, Jeffrey De Fauw, Ali Razavi, Carl Doersch, S. M. Ali Eslami, and Aaron van den Oord. contrastive predictive coding을 통한 데이터 효율적 이미지 인식. 에서ICML, 2020.
- Ioffe&Szegedy (2015) Sergey Ioffe and Christian Szegedy. Batch normalization: internal covariate shift를 줄여 deep network training을 가속하기. 2015.
- Kingma&Ba (2015) Diederik P. Kingma and Jimmy Ba. Adam: stochastic optimization을 위한 방법. 에서ICLR, 2015.
- Kolesnikov et al. (2020) Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, and Neil Houlsby. Big transfer (BiT): 일반적인 시각적 표현 학습. 에서ECCV, 2020.
- Krizhevsky (2009) Alex Krizhevsky. 작은 이미지들로부터 여러 층의 특징 학습하기. 기술 보고서, 2009.
- Krizhevsky et al. (2012) Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. deep convolutional neural networks를 이용한 Imagenet 분류. 에서NIPS, 2012.
- LeCun et al. (1989) Y. LeCun, B. Boser, J. Denker, D. Henderson, R. Howard, W. Hubbard, and L. Jackel. 손글씨 우편번호 인식에 적용된 backpropagation. Neural Computation, 1:541–551, 1989.
- Lepikhin et al. (2020) Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. Gshard: 조건부 계산과 자동 sharding으로 거대 모델 scaling하기. arXiv, 2020.
- Li et al. (2019) Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, and Kai-Wei Chang. VisualBERT: Vision and Language를 위한 간단하고 성능 좋은 baseline. 에서Arxiv, 2019.
- Locatello et al. (2020) Francesco Locatello, Dirk Weissenborn, Thomas Unterthiner, Aravindh Mahendran, Georg Heigold, Jakob Uszkoreit, Alexey Dosovitskiy, and Thomas Kipf. slot attention을 이용한 객체 중심 학습. arXiv, 2020.
- Lu et al. (2019) Jiasen Lu, Dhruv Batra, Devi Parikh, and Stefan Lee. ViLBERT: Vision-and-Language Tasks를 위한 task-agnostic visiolinguistic representations 사전 학습. 에서NeurIPS. 2019.
- Mahajan et al. (2018) Dhruv Mahajan, Ross Girshick, Vignesh Ramanathan, Kaiming He, Manohar Paluri, Yixuan Li, Ashwin Bharambe, and Laurens van der Maaten. 약지도 사전 학습의 한계 탐구. 에서ECCV, 2018.
- Nilsback&Zisserman (2008) M. Nilsback and A. Zisserman. 많은 수의 클래스에 대한 자동화된 꽃 분류. 에서ICVGIP, 2008.
- Parkhi et al. (2012) Omkar M. Parkhi, Andrea Vedaldi, Andrew Zisserman, and C. V. Jawahar. 고양이와 개. 에서CVPR, 2012.
- Parmar et al. (2018) Niki Parmar, Ashish Vaswani, Jakob Uszkoreit, Lukasz Kaiser, Noam Shazeer, Alexander Ku, and Dustin Tran. Image transformer. 에서ICML, 2018.
- Polyak&Juditsky (1992) B. T. Polyak and A. B. Juditsky. 평균화에 의한 stochastic approximation의 가속. SIAM Journal on Control and Optimization, 30(4):838–855, 1992. doi:10.1137/0330046. URLhttps://doi.org/10.1137/0330046.
- Qiao et al. (2019) Siyuan Qiao, Huiyu Wang, Chenxi Liu, Wei Shen, and Alan Yuille. Weight standardization. arXiv preprint arXiv:1903.10520, 2019.
- Radford et al. (2018) Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 비지도 학습으로 언어 이해 향상하기. Technical Report, 2018.
- Radford et al. (2019) Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. Technical Report, 2019.
- Ramachandran et al. (2019) Prajit Ramachandran, Niki Parmar, Ashish Vaswani, Irwan Bello, Anselm Levskaya, and Jon Shlens. vision models에서의 독립형 self-attention. 에서NeurIPS, 2019.
- Sun et al. (2017) Chen Sun, Abhinav Shrivastava, Saurabh Singh, and Abhinav Gupta. deep learning 시대에서 데이터의 비합리적 효과성을 다시 살펴보기. 에서ICCV, 2017.
- Sun et al. (2019) Chen Sun, Austin Myers, Carl Vondrick, Kevin Murphy, and Cordelia Schmid. Videobert: 비디오와 언어 표현 학습을 위한 공동 모델. 에서ICCV, 2019.
- Touvron et al. (2019) Hugo Touvron, Andrea Vedaldi, Matthijs Douze, and Herve Jegou. train-test 해상도 불일치 고치기. 에서NeurIPS. 2019.
- Touvron et al. (2020) Hugo Touvron, Andrea Vedaldi, Matthijs Douze, and Herve Jegou. train-test 해상도 불일치 고치기: Fixefficientnet. arXiv preprint arXiv:2003.08237, 2020.
- Tschannen et al. (2020) Michael Tschannen, Josip Djolonga, Marvin Ritter, Aravindh Mahendran, Neil Houlsby, Sylvain Gelly, and Mario Lucic. 비디오 유도 시각적 불변성의 self-supervised learning. 에서Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020년 6월.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. 에서NIPS, 2017.
- Wang et al. (2020a) Huiyu Wang, Yukun Zhu, Bradley Green, Hartwig Adam, Alan Yuille, and Liang-Chieh Chen. Axial-deeplab: panoptic segmentation을 위한 독립형 axial-attention. 에서ECCV, 2020a.
- Wang et al. (2020b) Huiyu Wang, Yukun Zhu, Bradley Green, Hartwig Adam, Alan Yuille, and Liang-Chieh Chen. Axial-deeplab: panoptic segmentation을 위한 독립형 axial-attention. arXiv preprint arXiv:2003.07853, 2020b.
- Wang et al. (2019) Qiang Wang, Bei Li, Tong Xiao, Jingbo Zhu, Changliang Li, Derek F. Wong, and Lidia S. Chao. 기계 번역을 위한 깊은 transformer 모델 학습. 에서ACL, 2019.
- Wang et al. (2018) Xiaolong Wang, Ross Girshick, Abhinav Gupta, and Kaiming He. Non-local neural networks. 에서CVPR, 2018.
- Weissenborn et al. (2019) Dirk Weissenborn, Oscar Täckström, and Jakob Uszkoreit. 자가회귀 비디오 모델의 스케일링. 에서ICLR, 2019.
- Wu et al. (2020) Bichen Wu, Chenfeng Xu, Xiaoliang Dai, Alvin Wan, Peizhao Zhang, Masayoshi Tomizuka, Kurt Keutzer, and Peter Vajda. Visual transformers: 컴퓨터 비전을 위한 토큰 기반 이미지 표현 및 처리. arxiv, 2020.
- Wu&He (2018) Yuxin Wu and Kaiming He. Group normalization. 에서ECCV, 2018.
- Xie et al. (2020) Qizhe Xie, Minh-Thang Luong, Eduard Hovy, and Quoc V. Le. noisy student를 사용한 self-training은 imagenet 분류를 향상시킨다. 에서CVPR, 2020.
- Zhai et al. (2019a) Xiaohua Zhai, Avital Oliver, Alexander Kolesnikov, and Lucas Beyer. S4L: Self-Supervised Semi-Supervised Learning. 에서ICCV, 2019a.
- Zhai et al. (2019b) Xiaohua Zhai, Joan Puigcerver, Alexander Kolesnikov, Pierre Ruyssen, Carlos Riquelme, Mario Lucic, Josip Djolonga, Andre Susano Pinto, Maxim Neumann, Alexey Dosovitskiy, et al. visual task adaptation benchmark를 사용한 표현 학습의 대규모 연구. arXiv preprint arXiv:1910.04867, 2019b.
- Zhao et al. (2020) Hengshuang Zhao, Jiaya Jia, and Vladlen Koltun. 이미지 인식을 위한 self-attention 탐구. 에서CVPR, 2020.
부록
부록 AMultihead Self-attention
표준self-attention (SA,Vaswani et al. (2017))은 신경망 아키텍처를 위한 인기 있는 구성 요소이다. 입력 시퀀스의 각 원소에 대해, 우리는 시퀀스의 모든 값에 대한 가중합을 계산한다시퀀스에서. attention 가중치는 시퀀스의 두 원소와 그 각각의 query 사이의 쌍별 유사도에 기반한다및 key표현.
| (5) | ||||||
| (6) | ||||||
| (7) | ||||||
Multihead self-attention (MSA)은 SA의 확장으로, 여기서 우리는“heads”라고 불리는 self-attention 연산들을 병렬로 실행하고, 그 연결된 출력들을 투영한다. 변경할 때 계산량과 파라미터 수를 일정하게 유지하기 위해, (식5)는 일반적으로 다음으로 설정된다.
| (8) |
부록 B실험 세부사항
B.1 학습
| 모델 | 데이터셋 | Epochs | Base LR | LR decay | Weight decay | Dropout |
|---|---|---|---|---|---|---|
| ViT-B/{16,32} | JFT-300M | 7 | linear | 0.1 | 0.0 | |
| ViT-L/32 | JFT-300M | 7 | linear | 0.1 | 0.0 | |
| ViT-L/16 | JFT-300M | 7/14 | linear | 0.1 | 0.0 | |
| ViT-H/14 | JFT-300M | 14 | linear | 0.1 | 0.0 | |
| R50x{1,2} | JFT-300M | 7 | linear | 0.1 | 0.0 | |
| R101x1 | JFT-300M | 7 | linear | 0.1 | 0.0 | |
| R152x{1,2} | JFT-300M | 7 | linear | 0.1 | 0.0 | |
| R50+ViT-B/{16,32} | JFT-300M | 7 | linear | 0.1 | 0.0 | |
| R50+ViT-L/32 | JFT-300M | 7 | linear | 0.1 | 0.0 | |
| R50+ViT-L/16 | JFT-300M | 7/14 | linear | 0.1 | 0.0 | |
| ViT-B/{16,32} | ImageNet-21k | 90 | linear | 0.03 | 0.1 | |
| ViT-L/{16,32} | ImageNet-21k | 30/90 | linear | 0.03 | 0.1 | |
| ViT- | ImageNet | 300 | cosine | 0.3 | 0.1 |
Table3은 우리의 서로 다른 모델들에 대한 학습 설정을 요약한다. 우리는 ImageNet에서 모델을 처음부터 학습할 때 강한 regularization이 핵심임을 발견했다. Dropout은 사용될 경우 qkv-projections를 제외한 모든 dense layer 뒤와 positional-을 patch embeddings에 더한 직후에 적용된다. Hybrid 모델들은 그들의 ViT 대응 모델과 정확히 같은 설정으로 학습된다. 마지막으로, 모든 학습은 해상도 224에서 수행된다.
B.1.1 Fine-tuning
| 데이터셋 | Steps | Base LR |
|---|---|---|
| ImageNet | 20 000 | {0.003, 0.01, 0.03, 0.06} |
| CIFAR100 | 10 000 | {0.001, 0.003, 0.01, 0.03} |
| CIFAR10 | 10 000 | {0.001, 0.003, 0.01, 0.03} |
| Oxford-IIIT Pets | 500 | {0.001, 0.003, 0.01, 0.03} |
| Oxford Flowers-102 | 500 | {0.001, 0.003, 0.01, 0.03} |
| VTAB (19 tasks) | 2 500 | 0.01 |
우리는 momentum 0.9를 갖는 SGD를 사용하여 모든 ViT 모델을 fine-tune한다. 우리는 learning rate에 대해 작은 grid search를 수행하며, Table의 learning rate 범위를 보라4. 이를 위해, 우리는 training set의 작은 sub-splits (Pets와 Flowers는 10%, CIFAR는 2%, ImageNet은 1%)를 development set으로 사용하고 나머지 데이터로 학습한다. 최종 결과를 위해 우리는 전체 training set으로 학습하고 각각의 test data에서 평가한다. ResNets와 hybrid 모델을 fine-tuning하기 위해 우리는 정확히 같은 설정을 사용하며, 유일한 예외는 ImageNet으로 여기서는 또 다른 값 하나를 추가한다learning rate sweep에. 추가적으로, ResNets의 경우 우리는 또한 다음의 설정을 실행한다Kolesnikov et al. (2020)그리고 이 실행과 우리의 sweep 전체에서 최고의 결과를 선택한다. 마지막으로, 달리 언급하지 않는 한, 모든 fine-tuning 실험은 384 해상도에서 실행된다(학습과 다른 해상도에서 fine-tuning을 실행하는 것은 일반적인 관행이다(Kolesnikov et al.,2020)).
ViT 모델을 다른 데이터셋으로 전이할 때, 우리는 전체 head(두 개의 linear layers)를 제거하고 이를 target dataset에 필요한 클래스 수를 출력하는 단일 zero-initialized linear layer로 대체한다. 우리는 이것이 단순히 맨 마지막 layer를 다시 초기화하는 것보다 조금 더 robust하다는 것을 발견했다.
VTAB의 경우 우리는 다음의 프로토콜을 따른다Kolesnikov et al. (2020), 그리고 모든 task에 대해 동일한 hyperparameter 설정을 사용한다. 우리는 learning rate를 사용한다그리고 학습한다steps (Tab.4). 우리는 두 개의 learning rates와 두 개의 schedules에 대한 작은 sweep을 실행하고, 200-example validation sets에서 가장 높은 VTAB score를 갖는 설정을 선택하여 이 설정을 골랐다. 우리는 다음에서 사용된 pre-processing을 따른다Kolesnikov et al. (2020), 단 task-specific input resolutions는 사용하지 않는다. 대신 우리는 Vision Transformer가 모든 task에 대해 높은 해상도()에서 가장 큰 이점을 얻는다는 것을 발견했다.
B.1.2 Self-supervision
우리는masked patch prediction목표를 예비 self-supervision 실험에 사용한다. 이를 위해 우리는 patch embeddings의 50%를 그 embeddings를 학습 가능한 것으로 대체함으로써 손상시킨다[mask]embedding (80%), 임의의 다른 patch embedding (10%) 또는 단순히 그대로 유지(10%)한다. 이 설정은 언어에 대해 사용된 것과 매우 유사하다Devlin et al. (2019). 마지막으로, 우리는 각각의 patch representations를 사용하여 모든 손상된 patch의 3-bit, mean color (즉, 총 512 colors)를 예측한다.
우리는 JFT에서 batch size 4096으로 1M steps (약 14 epochs) 동안 self-supervised model을 학습했다. 우리는 Adam을 사용하며, base learning rate는, warmup 10k steps 및 cosine learning rate decay를 사용한다. pretraining의 prediction targets로 우리는 다음 설정들을 시도했다: 1) mean, 3bit color만 예측(즉, 512 colors의 1개 예측), 2) 다음의 downsized version을 예측downsized version of thepatch를 3bit colors로 병렬 예측(즉, 512 colors의 16개 예측), 3) L2를 사용하여 전체 patch에 대한 regression(즉, 3 RGB channels에 대한 256 regressions). 놀랍게도, 우리는 모두 꽤 잘 작동했지만 L2가 약간 더 나빴다는 것을 발견했다. 우리는 option 1)이 최고의 few-shot performance를 보였기 때문에 최종 결과는 option 1)에 대해서만 보고한다. 우리는 또한 다음에서 사용된 15% corruption rate로 실험했다Devlin et al. (2019)하지만 결과는 우리의 few-shot metrics에서도 약간 더 나빴다.
마지막으로, 우리는 우리의 masked patch prediction 인스턴스화가 ImageNet classification에서 유사한 성능 향상을 이끌어내기 위해 그러한 엄청난 양의 pretraining이나 JFT와 같은 큰 dataset을 필요로 하지 않는다는 점을 언급하고 싶다. 즉, 우리는 100k pretraining steps 이후 downstream performance에서 diminishing returns를 관찰했으며, ImageNet에서 pretraining할 때도 유사한 gains를 본다.
부록 C추가 결과
우리는 논문에 제시된 figures에 해당하는 상세 결과를 보고한다. Table5은 Figure에 해당한다4논문에서, 그리고 증가하는 크기의 datasets: ImageNet, ImageNet-21k, 및 JFT-300M에서 pre-trained된 서로 다른 ViT 모델들의 transfer performance를 보여준다. Table6은 Figure에 해당한다5논문에서, 그리고 다양한 크기의 ViT, ResNet, 및 hybrid 모델들의 transfer performance와 그 pre-training의 추정 computational cost를 보여준다.
| ViT-B/16 | ViT-B/32 | ViT-L/16 | ViT-L/32 | ViT-H/14 | ||
|---|---|---|---|---|---|---|
| ImageNet | CIFAR-10 | 98.13 | 97.77 | 97.86 | 97.94 | - |
| CIFAR-100 | 87.13 | 86.31 | 86.35 | 87.07 | - | |
| ImageNet | 77.91 | 73.38 | 76.53 | 71.16 | - | |
| ImageNet ReaL | 83.57 | 79.56 | 82.19 | 77.83 | - | |
| Oxford Flowers-102 | 89.49 | 85.43 | 89.66 | 86.36 | - | |
| Oxford-IIIT-Pets | 93.81 | 92.04 | 93.64 | 91.35 | - | |
| ImageNet-21k | CIFAR-10 | 98.95 | 98.79 | 99.16 | 99.13 | 99.27 |
| CIFAR-100 | 91.67 | 91.97 | 93.44 | 93.04 | 93.82 | |
| ImageNet | 83.97 | 81.28 | 85.15 | 80.99 | 85.13 | |
| ImageNet ReaL | 88.35 | 86.63 | 88.40 | 85.65 | 88.70 | |
| Oxford Flowers-102 | 99.38 | 99.11 | 99.61 | 99.19 | 99.51 | |
| Oxford-IIIT-Pets | 94.43 | 93.02 | 94.73 | 93.09 | 94.82 | |
| JFT-300M | CIFAR-10 | 99.00 | 98.61 | 99.38 | 99.19 | 99.50 |
| CIFAR-100 | 91.87 | 90.49 | 94.04 | 92.52 | 94.55 | |
| ImageNet | 84.15 | 80.73 | 87.12 | 84.37 | 88.04 | |
| ImageNet ReaL | 88.85 | 86.27 | 89.99 | 88.28 | 90.33 | |
| Oxford Flowers-102 | 99.56 | 99.27 | 99.56 | 99.45 | 99.68 | |
| Oxford-IIIT-Pets | 95.80 | 93.40 | 97.11 | 95.83 | 97.56 |
| Epochs | ImageNet | ImageNet ReaL | CIFAR-10 | CIFAR-100 | Pets | Flowers | exaFLOPs | |
| name | ||||||||
| ViT-B/32 | 7 | 80.73 | 86.27 | 98.61 | 90.49 | 93.40 | 99.27 | 55 |
| ViT-B/16 | 7 | 84.15 | 88.85 | 99.00 | 91.87 | 95.80 | 99.56 | 224 |
| ViT-L/32 | 7 | 84.37 | 88.28 | 99.19 | 92.52 | 95.83 | 99.45 | 196 |
| ViT-L/16 | 7 | 86.30 | 89.43 | 99.38 | 93.46 | 96.81 | 99.66 | 783 |
| ViT-L/16 | 14 | 87.12 | 89.99 | 99.38 | 94.04 | 97.11 | 99.56 | 1567 |
| ViT-H/14 | 14 | 88.08 | 90.36 | 99.50 | 94.71 | 97.11 | 99.71 | 4262 |
| ResNet50x1 | 7 | 77.54 | 84.56 | 97.67 | 86.07 | 91.11 | 94.26 | 50 |
| ResNet50x2 | 7 | 82.12 | 87.94 | 98.29 | 89.20 | 93.43 | 97.02 | 199 |
| ResNet101x1 | 7 | 80.67 | 87.07 | 98.48 | 89.17 | 94.08 | 95.95 | 96 |
| ResNet152x1 | 7 | 81.88 | 87.96 | 98.82 | 90.22 | 94.17 | 96.94 | 141 |
| ResNet152x2 | 7 | 84.97 | 89.69 | 99.06 | 92.05 | 95.37 | 98.62 | 563 |
| ResNet152x2 | 14 | 85.56 | 89.89 | 99.24 | 91.92 | 95.75 | 98.75 | 1126 |
| ResNet200x3 | 14 | 87.22 | 90.15 | 99.34 | 93.53 | 96.32 | 99.04 | 3306 |
| R50x1+ViT-B/32 | 7 | 84.90 | 89.15 | 99.01 | 92.24 | 95.75 | 99.46 | 106 |
| R50x1+ViT-B/16 | 7 | 85.58 | 89.65 | 99.14 | 92.63 | 96.65 | 99.40 | 274 |
| R50x1+ViT-L/32 | 7 | 85.68 | 89.04 | 99.24 | 92.93 | 96.97 | 99.43 | 246 |
| R50x1+ViT-L/16 | 7 | 86.60 | 89.72 | 99.18 | 93.64 | 97.03 | 99.40 | 859 |
| R50x1+ViT-L/16 | 14 | 87.12 | 89.76 | 99.31 | 93.89 | 97.36 | 99.11 | 1668 |
부록 D추가 분석
D.1 ResNets에 대한 SGD 대 Adam
ResNets는 일반적으로 SGD로 학습되며, 우리가 Adam을 optimizer로 사용하는 것은 꽤 비전통적이다. 여기서 우리는 이 선택의 동기가 된 실험들을 보여준다. 즉, 우리는 JFT에서 SGD와 Adam으로 사전 학습된 두 ResNets – 50x1 및 152x2 – 의 fine-tuning 성능을 비교한다. SGD의 경우, 우리는 다음이 권장한 hyperparameters를 사용한다Kolesnikov et al. (2020). 결과는 Table7에 제시되어 있다. Adam 사전 학습은 대부분의 데이터셋과 평균에서 SGD 사전 학습보다 성능이 좋다. 이는 JFT에서 ResNets를 사전 학습하는 데 사용된 optimizer로 Adam을 선택한 것을 정당화한다. 절대 수치는 다음이 보고한 것보다 낮다는 점에 유의하라Kolesnikov et al. (2020), 왜냐하면 우리는 단지epochs 동안만 사전 학습하고, 그렇지 않기 때문이다.
| ResNet50 | ResNet152x2 | |||
|---|---|---|---|---|
| 데이터셋 | Adam | SGD | Adam | SGD |
| ImageNet | ||||
| CIFAR10 | ||||
| CIFAR100 | ||||
| Oxford-IIIT Pets | ||||
| Oxford Flowers-102 | ||||
| 평균 | ||||
D.2 Transformer 형태
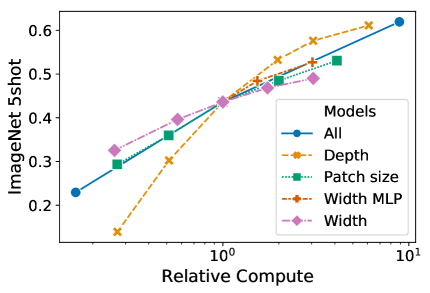
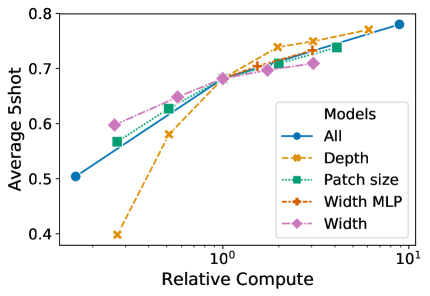
우리는 매우 큰 모델로의 스케일링에 가장 적합한 것이 무엇인지 알아내기 위해 Transformer 아키텍처의 서로 다른 차원들을 스케일링하는 ablations를 수행했다. Figure8는 서로 다른 configurations에 대한 ImageNet에서의 5-shot 성능을 보여준다. 모든 configurations는layers,, 및 patch size, 즉 모든 선들의 교차점을 가진 ViT 모델에 기반한다. 우리는 depth를 스케일링하는 것이 가장 큰 개선을 가져오며, 이는 64 layers까지 명확히 보인다는 것을 알 수 있다. 그러나 diminishing returns는 이미 16 layers 이후에 보인다. 흥미롭게도, 네트워크의 width를 스케일링하는 것은 가장 작은 변화를 가져오는 것처럼 보인다. patch size를 줄이고 따라서 effective sequence length를 늘리는 것은 parameters를 도입하지 않고도 놀랄 만큼 robust한 개선을 보인다. 이러한 발견은 compute가 parameters 수보다 성능의 더 나은 예측자일 수 있으며, 스케일링은 가능하다면 width보다 depth를 강조해야 함을 시사한다. 전반적으로, 우리는 모든 차원을 비례적으로 스케일링하는 것이 robust한 개선을 가져온다는 것을 발견했다.
D.3 Head Type 및classtoken
원래 Transformer 모델에 가능한 한 가깝게 유지하기 위해, 우리는 추가적인[class]token을 사용했으며, 이는 image representation으로 취해진다. 이 token의 출력은 그런 다음을 단일 hidden layer의 non-linearity로 갖는 작은 multi-layer perceptron (MLP)을 통해 class prediction으로 변환된다.
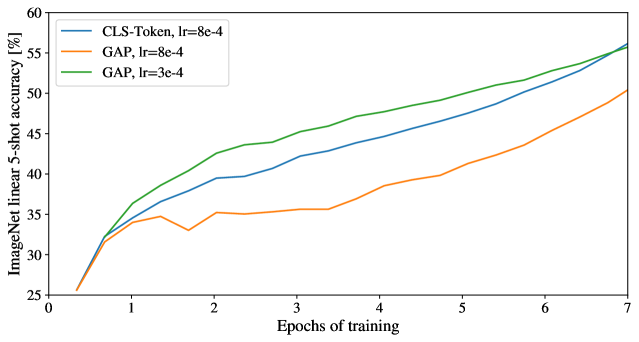
이 설계는 text용 Transformer 모델에서 물려받은 것이며, 우리는 본 논문 전반에서 이를 사용한다. image-patch embeddings만 사용하고, 그것들을 globally average-pooling (GAP)한 뒤, ResNet의 최종 feature map과 똑같이 linear classifier를 뒤따르게 하는 초기 시도는 매우 좋지 않은 성능을 보였다. 그러나 우리는 이것이 extra token 때문도 아니고 GAP operation 때문도 아님을 발견했다. 대신, 성능 차이는 서로 다른 learning-rate에 대한 요구로 완전히 설명된다, Figure 참조9.
D.4 Positional Embedding
우리는 positional embedding을 사용해 spatial information을 encoding하는 서로 다른 방법들에 대한 ablations를 수행했다. 우리는 다음 경우들을 시도했다:
-
•
positional information을 제공하지 않음: inputs를bag of patches.
-
•
1-dimensional positional embedding: inputs를 raster order의 patches sequence로 간주함(이 논문의 다른 모든 실험에서 default).
-
•
2-dimensional positional embedding: inputs를 두 차원의 patches grid로 간주함. 이 경우, 두 sets of embeddings가 학습되며, 각각은 축 중 하나에 대한 것이다,-embedding, 그리고-embedding, 각각 size를 가진다. 그런 다음, input에서 path 위의 coordinate에 기반하여, 우리는및embedding을 concatenate하여 해당 patch에 대한 최종 positional embedding을 얻는다.
-
•
Relative positional embeddings: spatial information을 그들의 absolute position 대신 patches 사이의 relative distance를 고려하여 encoding함. 이를 위해, 우리는 1-dimensional Relative Attention을 사용하며, 여기서 patches의 가능한 모든 pairs에 대한 relative distance를 정의한다. 따라서, 주어진 모든 pair(하나는 query로, 다른 하나는 attention mechanism에서 key/value로)에 대해, 우리는 offset을 가지며, 각 offset은 embedding과 연관된다. 그런 다음, 우리는 단순히 extra attention을 실행하는데, 여기서 original query(query의 content)를 사용하지만, relative positional embeddings를 keys로 사용한다. 그런 다음 relative attention의 logits를 bias term으로 사용하고, softmax를 적용하기 전에 main attention(content-based attention)의 logits에 더한다.
| Pos. Emb. | Default/Stem | Every Layer | Every Layer-Shared |
|---|---|---|---|
| No Pos. Emb. | 0.61382 | N/A | N/A |
| 1-D Pos. Emb. | 0.64206 | 0.63964 | 0.64292 |
| 2-D Pos. Emb. | 0.64001 | 0.64046 | 0.64022 |
| Rel. Pos. Emb. | 0.64032 | N/A | N/A |
spatial information을 encoding하는 서로 다른 방법들에 더해, 우리는 또한 이 정보를 우리 모델에 통합하는 서로 다른 방법들을 시도했다. 1-dimensional 및 2-dimensional positional embeddings에 대해, 우리는 세 가지 서로 다른 경우를 시도했다: (1) 모델의 stem 직후 및 inputs를 Transformer encoder에 공급하기 전에 inputs에 positional embeddings를 더한다(이 논문의 다른 모든 실험에서 default); (2) 각 layer의 시작 부분에서 inputs에 positional embeddings를 학습하고 더한다; (3) 각 layer의 시작 부분에서 inputs에 학습된 positional embeddings를 더한다(layers 간 shared).
Table8은 ViT-B/16 모델에 대한 이 ablation study의 결과를 요약한다. 볼 수 있듯이, positional embedding이 없는 모델과 positional embedding이 있는 모델들의 성능 사이에는 큰 격차가 있지만, positional information을 encoding하는 서로 다른 방법들 사이에는 차이가 거의 없거나 전혀 없다. 우리는 Transformer encoder가 pixel-level이 아니라 patch-level inputs에서 작동하기 때문에 spatial information을 encoding하는 방법의 차이가 덜 중요하다고 추측한다. 더 정확히 말하면, patch-level inputs에서는 spatial dimensions가 원래 pixel-level inputs보다 훨씬 작다, 예를 들어,와 대조적으로, 그리고 이 resolution에서 spatial relations를 represent하도록 학습하는 것은 이러한 서로 다른 positional encoding strategies에 대해 똑같이 쉽다. 그럼에도 불구하고, network가 학습한 position embedding similarity의 특정 pattern은 training hyperparameters에 의존한다(Figure10).
D.5 Empirical Computational Costs
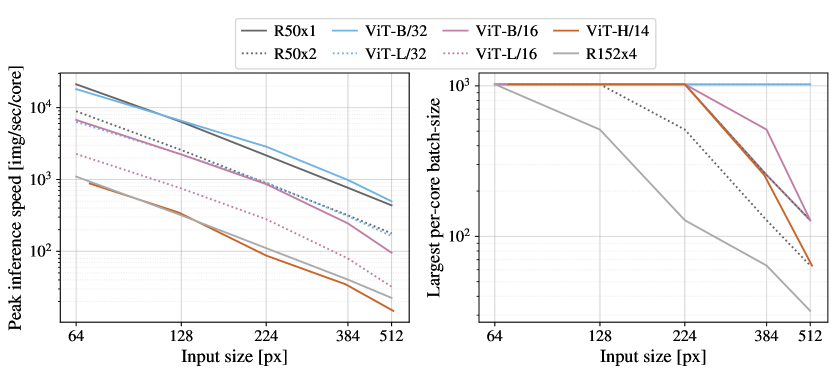
우리는 또한 우리 hardware에서 architectures의 실제 속도에 관심이 있는데, 이는 lane widths와 cache sizes 같은 세부 사항 때문에 theoretical FLOPs로 항상 잘 예측되지는 않는다. 이 목적을 위해, 우리는 관심 있는 main models에 대해 TPUv3 accelerator에서 inference speed의 timing을 수행한다; inference와 backprop speed 사이의 차이는 model-independent constant factor이다.
Figure12(left)는 다양한 input sizes에 걸쳐 하나의 core가 초당 처리할 수 있는 images 수를 보여준다. 각각의 단일 point는 wide range of batch-sizes 전반에서 측정된 peak performance를 가리킨다. 볼 수 있듯이, image size에 따른 ViT의 theoretical bi-quadratic scaling은 가장 큰 resolutions에서 가장 큰 models에 대해서만 간신히 시작된다.
또 다른 관심 quantity는 각 model이 하나의 core에 올릴 수 있는 가장 큰 batch-size이며, large datasets로 scaling하기에는 더 클수록 좋다. Figure12(right)는 동일한 models 집합에 대해 이 quantity를 보여준다. 이는 large ViT models가 ResNet models보다 memory-efficiency 측면에서 분명한 이점을 가진다는 것을 보여준다.
D.6 Axial Attention
Axial Attention(Huang et al.,2020; Ho et al.,2019)는 multidimensional tensors로 조직된 large inputs에서 self-attention을 실행하는 간단하지만 효과적인 technique이다. axial attention의 일반적인 아이디어는 input의 flattened version에 1-dimensional attention을 적용하는 대신, input tensor의 단일 axis를 따라 각각 여러 attention operations를 수행하는 것이다. axial attention에서 각 attention은 특정 axis를 따라 information을 mix하는 반면, 다른 axes를 따라서는 information을 independent하게 유지한다. 이 선상에서,Wang et al. (2020b)은 ResNet50에서 kernel size인 모든 convolutions가 axial self-attention, 즉 relative positional encoding으로 보강된 row 및 column attention으로 대체되는 AxialResNet 모델을 제안했다. 우리는 AxialResNet을 baseline model로 구현했다.333우리 구현은 다음의 open-sourced PyTorch implementation에 기반한다https://github.com/csrhddlam/axial-deeplab. 우리의 실험에서, 우리는 다음에 보고된 scores를 재현했다(Wang et al.,2020b)accuracy 측면에서는, 그러나 우리의 구현은 open-source implementation과 유사하게 TPUs에서 매우 느리다. 따라서, 우리는 이를 광범위한 large-scale experiments에 사용할 수 없었다. 이것들은 신중하게 최적화된 implementation에 의해 가능해질 수 있다..
또한, 우리는 ViT가 1-dimensional sequence of patches 대신 2-dimensional shape로 inputs를 처리하도록 수정하고, Axial Transformer blocks를 통합했는데, 여기서는 self-attention 뒤에 MLP가 오는 대신 row-self-attention plus MLP 뒤에 column-self-attention plus MLP가 온다.
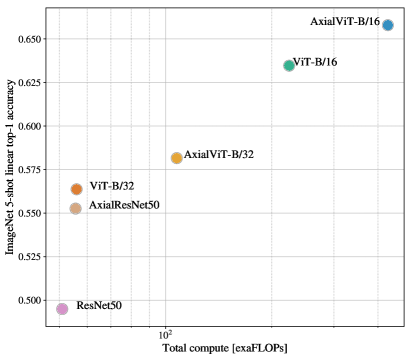
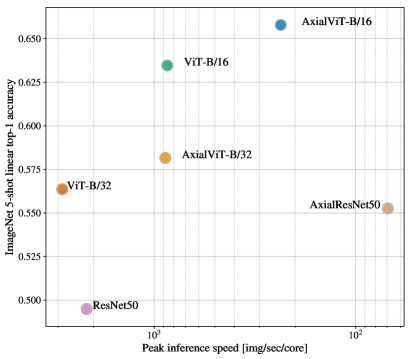
Figure13, 는 JFT dataset에서 pretrained되었을 때 Axial ResNet, Axial-ViT-B/32 및 Axial-ViT-B/16의 ImageNet 5shot linear 성능을 pretraining compute 대비로, FLOPs 수와 inference time(examples per seconds) 두 측면에서 제시한다. 볼 수 있듯이, Axial-ViT-B/32와 Axial-ViT-B/16은 성능 측면에서 각각의 ViT-B counterpart보다 더 잘하지만, 이는 더 많은 compute의 비용을 수반한다. 이는 Axial-ViT models에서 global self-attention을 가진 각 Transformer block이 두 Axial Transformer blocks, 즉 row self-attention을 가진 하나와 column self-attention을 가진 하나로 대체되고, self-attention이 작동하는 sequence length가 axial case에서는 더 작지만 Axial-ViT block당 extra MLP가 있기 때문이다. AxialResNet의 경우, accuracy/compute trade-off 측면에서는 합리적으로 보이지만(Figure13, left), naive implementation은 TPUs에서 극도로 느리다(Figure13, right).
D.7 Attention Distance
ViT가 self-attention을 사용해 image 전반의 information을 통합하는 방식을 이해하기 위해, 우리는 서로 다른 layers에서 attention weights가 걸치는 average distance를 분석했다(Figure11). 이 “attention distance”는 CNNs의 receptive field size와 유사하다. Average attention distance는 lower layers의 heads 전반에서 매우 가변적이며, 일부 heads는 image의 많은 부분에 attend하는 반면, 다른 heads는 query location 또는 그 근처의 작은 regions에 attend한다. depth가 증가함에 따라, attention distance는 모든 heads에서 증가한다. network의 후반부에서는 대부분의 heads가 tokens 전반에 넓게 attend한다.
D.8 Attention Maps
output token에서 input space로의 attention maps를 계산하기 위해(Figures6및14), 우리는 Attention Rollout을 사용했다(Abnar&Zuidema,2020). 간단히 말해, 우리는 모든 heads에 걸쳐 ViT-L/16의 attention weights를 평균한 다음 모든 layers의 weight matrices를 재귀적으로 곱했다. 이는 모든 layers를 통한 tokens 전반의 attention mixing을 설명한다.

D.9 ObjectNet Results
우리는 또한 다음의 evaluation setup을 따라 ObjectNet benchmark에서 우리의 flagship ViT-H/14 모델을 평가한다Kolesnikov et al. (2020), 그 결과 82.1% top-5 accuracy 및 61.7% top-1 accuracy를 얻었다.
D.10 VTAB Breakdown
Table9은 각 VTAB-1k tasks에서 달성한 scores를 보여준다.
|
Caltech101 |
CIFAR-100 |
DTD |
Flowers102 |
Pets |
Sun397 |
SVHN |
Camelyon |
EuroSAT |
Resisc45 |
Retinopathy |
Clevr-Count |
Clevr-Dist |
DMLab |
dSpr-Loc |
dSpr-Ori |
KITTI-Dist |
sNORB-Azim |
sNORB-Elev |
평균 |
||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ViT-H/14 (JFT) | 95.3 | 85.5 | 75.2 | 99.7 | 97.2 | 65.0 | 88.9 | 83.3 | 96.7 | 91.4 | 76.6 | 91.7 | 63.8 | 53.1 | 79.4 | 63.3 | 84.5 | 33.2 | 51.2 | 77.6 | |
| ViT-L/16 (JFT) | 95.4 | 81.9 | 74.3 | 99.7 | 96.7 | 63.5 | 87.4 | 83.6 | 96.5 | 89.7 | 77.1 | 86.4 | 63.1 | 49.7 | 74.5 | 60.5 | 82.2 | 36.2 | 51.1 | 76.3 | |
| ViT-L/16 (I21k) | 90.8 | 84.1 | 74.1 | 99.3 | 92.7 | 61.0 | 80.9 | 82.5 | 95.6 | 85.2 | 75.3 | 70.3 | 56.1 | 41.9 | 74.7 | 64.9 | 79.9 | 30.5 | 41.7 | 72.7 |